Publications
2026
MDK: Rethinking the Data Center Reclamation Problem (Conference Link)
Patel, S., Yang, S., Wan, Y., Wu, K., Fedorova, A., Seltzer, M., Keeton, K.
Proceedings of the 2026 Symposium on Operating System Design and Implementation (OSDI26)
page replacement, eviction policy, memory reclamation, memory performance curves
From Rashomon Theory to PRAXIS: Efficient Decision Tree Rashomon Sets (PDF)
Heile, Z., McTavish, H., Babbar, V., Seltzer, M., Rudin, C.
Proceedings of the 2026 International Conference on Machine Learning (ICML26)
interpretable machine learning, machine learning, decision trees, rashomon sets
CLARITree: Cholesky and Lookahead Accelerations for Regression with Interpretable Piecewise Linear Trees (PDF)
Wang, Y., McTavish, H., Babbar, V., Seltzer, M., Rudin C.
Proceedings of the 2026 International Conference on Machine Learning (ICML26)
interpretable machine learning, machine learning, regression trees
Rashomon Sets of Falling Trees (Web Site)
Babbar, V., Boner, Z., Seltzer, M., Rudin, C.
Proceedings of the 2026 International Conference on Machine Learning (ICML26) Spotlight Poster
interpretable machine learning, machine learning, decision trees, rule lists, falling rule lists
2025
CHERIoT OS: An OS for Fine-Grain Memory-Safe Compartments on Low-cost Embedded Devices (PDF)
Lefeuvre, H., Amar, S., Chen, T., Chisnall, D., Filardo, N., Laurie, B., Moor, S., Norton-Wright, R., Seltzer, M., Tao, Y., Watson, R., Xia, H.
Proceedings of the 2025 Symposium on Operating Systems Principles
operating systems, embedded systems, IoT, capabilities, CHERI
Comparing Isolation Mechanisms with OSmosis (PDF)
Agrawal, S., Patel, S., Stevinson, A., Pham, L., Karimalis, I., Lefeuvre, H., Mehta, A., Achermann, R., Seltzer, M.
Workshop on Programming Languages and Operating Systems
operating systems, isolation mechanisms, sharing, modeling
Leveraging Predictive Equivalence in Decision trees (arXiv)
McTavish, H., Boner, Z., Donelly, J., Seltzer, M., Rudin, C.
International Conference on Machine Learning (ICML 2025)
interpretable machine learning, decision trees, machine learning, rashomon sets
Near Optimal Decision Trees in a SPLIT Second
(arXiv)
Babbar, V., McTavish, H., Rudin, C., Seltzer, M.
International Conference on Machine Learning (ICML 2025)
interpretable machine learning, decision trees, machine learning
Provenance Design and Evolution in a Production ML Library
(PDF)
Pocock, A., Wonsil, J., Mahinpei, R., Sullivan, J., Seltzer, M.
2025 ICML Workshop on Championing Open-source Development in Machine Learning (CODEML '25)
provenance, machine learning, open source
Raising the Reproducibility Bar
(PDF)
Wonsil, J., Guerra, R., Pocock, A., Sullivan, J., Seltzer, M.
Proceedings of the 2025 ACM Conference on Reprocibility
provenance, reproducibility
Experience with Reproducibility and Consistency in Writing an Academic Paper
(PDF)
Wonsil, J., Boufford, N., Pocock, A., Sullivan, J., Seltzer, M.
Proceedings of the 2025 ACM Conference on Reprocibility
provenance, reproducibility
Velosiraptor: Code Synthesis for Memory Translation
(arXiv)
Achermann, R., Chu, E., Mehri, R., Karimalis, I., Seltzer, M.
Proceedings of the 30th ACM International Conference on
Architectural Support for Programming Languages and
Operating Systems (ASPLOS '25)
virtual memory, automatic programming, software engineering, program synthesis
CUTTANA: Scalable Graph Partitioning for Faster Distributed Graph Databases and Analytics
(PDF)
Rezaei, M., Sridhar, S., Seltzer, M.,
Proceedings of the Very Large Database Endowment (PVLDB)
graph partitioning, graphs
2024
Interpretable Generalized Additive Models for Datasets with Missing Values
(PDF)
McTavish, H., Donnelly, J., Seltzer, M., Rudin, C.
2024 Conference on Neural Information Processing (NeurIPS 2024)
Interpretable Machine Learning, GAMS, Missing Data, machine learning
HyperBrain: Anomaly Detection for Temporal Hypergraph Brain Networks
(PDF)
Sadeghian, S., Li, X., Seltzer, M
Proceedings of the Workshop on Machine Learning in Clinical Neuroimaging (MLCN 2024; Co-located with MICCAI 2024)
hypergraph, temporal graph, temporal hypergraph, fMRI, GNN, graph learning, machine learning
Parallel Assembly Synthesis
(PDF)
Hu, J., Chong, S., Seltzer, M.,
Proceedings of the 34th International Symposium on Logic-Based Program Synthesis and Transformation (LOPSTR 2024; Co-located with PPDP as part of Formal Methods 2024)
program synthesis, assembly synthesis, parallelization
NetShaper: A Differentially Private Network Side-Channel Mitigation System
(Arxiv)
Sabzi, A., Vora, R., Goswami, S., Seltzer, M., Lecuyer, M., Mehta, A.,
USENIX Security Symposium (USENIX Security 2024)
side channel, differential privacy, network side channel
Amazing Things Come from Having Many Good Models
(Arxiv)
Rudin, C., Zhong, C., Semenova, L., Seltzer, M., Parr, R., Liu, J., Katta, S., Donnelly, J., Chen, H., Boner, Z.,
International Conference on Machine Learning (ICML 2024)
Rashomon set, GAMs, decision trees, scoring systems, machine learning
Enabling Application-Aware Memory Page Replacement Policies and Mechanisms with ExtMem
(PDF)
Jalalian, S., Patel, S., Hajidehi, M., Seltzer, M., Fedorova, S.,
Proceedings of the USENIX Annual Technical Conference (ATC-2024)
prefetching, swap, semikernel
Computational Experiment Comprehension using Provenance Summarization
(PDF)
Boufford, M., Wonsil, M., Pocock, A., Sullivan, J., Seltzer, M., Pasquier, T.,
Proceedings of the ACM Conference on Reproducibility (REP 2024)
provenance, reproducibility, LLM, provenance summarization
RABIT: A Robot Arm Bug Intervention Tool for Self-Driving Labs
(PDF)
Wattoo, Z., Gujarati, A., Seltzer, M.,
Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks
self-driving lab, intrusion detection, anomaly detection
Optimal Sparse Survival Trees
(arXiv)
Selected for spotlight presentation.
Zhang, R., Xin, R., A., Seltzer, M., Rudin, C.,
Artificial Intelligence and Statistics (AISTATS 2024)
interpretable machine learning, interpretable ML, ML, survival trees, optimal trees, machine learning
2023
Exploring and Interacting with the Set of Good Sparse Generalized Additive Models
(Arxiv)
Zhong, C., Chen, Z., Liu, J., Seltzer, M., Rudin, C.,
37th Conference on Neural Information Processing (NeurIPS 2023)
Rashomon set, GAMs, sparse models, generalized additive models, machine learning
CAT-Walk: Inductive Hypergraph Learning via Set Walks
(Arxiv)
Behrouz, A., Hashemi, F., Sadeghian, S., Seltzer, M.,
37th Conference on Neural Information Processing (NeurIPS 2023)
machine learning, hypergraphs, edge prediction, node prediction
CHERI-picking: Leveraging capability hardware for prefetching
(PDF)
Patel, S., Agrawal, S., Fedorova, A., Seltzer, M.,
Programming Languages and Operating Systems Workshop (PLOS '23)
Prefetching, capabilities, CHERI
Synthesizing Device Drivers with Ghost Writer
(PDF)
Wang, B., Noorafshan, S., Achermann, R., Seltzer, M.,
Programming Languages and Operating Systems Workshop (PLOS '23)
Device drivers, program synthesis, behavior trees
Anomaly Detection in the Human Brain via Inductive Learning on Temporal
Multiplex Networks
(PDF)
Behrouz, A., Seltzer, M.
Proceedings of Machine Learning Research 219:1-31 (Presented at the 2023 Machine Learning for Healthcare Conference (MLHC), August 2023
graph neural networks, anomaly detection, machine learning, healthcare
ADMIRE++: Explainable Anomaly Detection in the Human Brain via
Inductive Learning on Temporal Multiplex Networks
(PDF)
Best Paper
Behrouz, A., Seltzer, M.
International Machine Learning in Healthcare Workshop (w/ICML),
July 2023
explainable AI, machine learning, healthcare, anomaly detection
Integrated Reproducibility with Self-describing Machine Learning Models
(PDF)
Wonsil J., Sullivan, J., Seltzer, M., Pocock, A.
Proceedings of the First ACM Conference on Reproducibility, June 2023
reproducibility, provenance, java, machine learning, Tribuo
Reproducibility as a Service
(PDF)
Wonsil, J., Boufford, N., Agrawal, P., Chen, C., Cui, T.,
Sivaram, A., Seltzer, M.
Software: Practice and Experience, 2023.
provenance, reproducibility, data science
Why write code when you can synthesize address translations?
(PDF)
Achermann, R., Karimalis, I., Seltzer, M.
Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS),
May 2023
program synthesis, memory translation
Making Provenance Work for You
(PDF)
Lerner, B., Boose, E., Brand, O., Ellison, A., Fong, E., Lau, M., Ngo, K., Pasquier, T., Perez, L., Seltzer, M., Sheehan, M., Wonsil, J.
The R Journal (2023)
Provenance, R, RDT, Reproducibility
Optimal Sparse Regression Trees
(arXiv)
Zhang, R., Xin, R., Seltzer, M., Rudin, C.
Proceedings of the 37th Conference on Artifical Intelligence (AAAI)
Interpretable ML, Sparse Models, Regression Trees, machine learning
2022
Anomaly Detection in Multiplex Dynamic Networks: from Blockchain Security
to Brain Disease Prediction,
(PDF)
Selected for spotlight presentation.
Behrouz, A., Seltzer, M.,
Thirty-sixth Conference on Neural Information Processing Systems, (NeurIPS 2022)
graph learning, anomaly detection, intrusion detection, machine learning
Fast Optimization of Weighted Sparse Decision Trees for use in Optimal Treatment
Regimes and Optimal Policy Design
(arXiv)
Behrouz, A., Lecuyer, M., Rudin, C., Seltzer, M.,
Advances in Interpretable Machine Learning and Artificial Intelligence (AIMLAI 2022)
Optimal Sparse Decision Trees, Interpretable Machine Learning,
Optimal Treatment Regimes, machine learning
FasterRisk: Fast and Accurate Interpretable Risk Scores
(arXiv)
Liu, J., Zhong, C., Li, B., Seltzer, M., Rudin, C.,
Thirty-sixth Conference on Neural Information Processing Systems, (NeurIPS 2022)
Risk Scores, Interpretable Machine Learning, machine learning
Exploring the Whole Rashomon Set of Sparse Decision Trees
(arXiv) Selected for Oral
Presentation
Xin, R, Zhong, C., Chen Z., Takagi, R., Seltzer, M., Rudin, C.,
Thirty-sixth Conference on Neural Information Processing Systems, (NeurIPS 2022)
Optimal Sparse Decision Trees, Rashomon Set, machine learning
Shellac: a compiler synthesizer for concurrent programs
(PDF)
Chen, C., Seltzer, M., Greenstreet, M.,
Conference on Verified Software: Theories, Tools, and Experiments (VSTTE), 2022
program synthesis, compilation, arduino C++, verilog, UNITY
TimberTrek: Exploring and Curating Sparse Decision Trees with
Interactive Visualization
(website)
Wang, Z., Zhong, C., Xin, R., Takagi, T., Chen, Z.,
Chau, D., Rudin, C., Seltzer, M.,
IEEE Visualization Conference (VIS), 2022.
optimal sparse decision trees, machine learning, interpretable AI, visualization
Towards Porting Operating Systems with Program Synthesis
(PDF).
Hu, J., Lu, E., Holland, D., Kawaguchi, M., Chong, S., Seltzer, M.,
ACM Transactions on Programming Languages and Systems (TOPLAS), September 2022.
program synthesis,operating systems
Tinkertoy: Build your own operating systems for IoT devices
(PDF)
Best Paper
Wang, B., Seltzer, M.,
ACM SIGBED International Conference on Embedded Software (EMSOFT 2022)
IoT, Operating System, Design and Implementation
Arming IDS Researchers with a Robotic Arm Dataset
(PDF)
(teaser)
(video)
(dataset)
Guarati, A., Wattoo, Z., Aliabadi, M., Clark, S., Liu, X., Shiri, P., Trivedi, A., Zhu, R., Hein, J., Seltzer, M.,
The 52nd Annual IEEE/IFIP International Conference on Dependable Systems and
Networks (DSN 2022), June 2022.
robotic arms, intrusion detection, dataset
Fast Sparse Classification for Generalized Linear and Additive Models
(PDF)
(video)
(poster)
Liu, J., Zhong, C., Seltzer, M., Rudin, C.
The 25th International Conference on Artificial Intelligence and Statistics
linear models, sparse models, classification, additive models, machine learning
Fast Sparse Decision Tree Optimization via Reference Ensembles
(PDF)
(video teaser)
(full talk)
McTavish, H., Zhong, C., Achermann, R., Karimalis, I., Chen, J.,
Rudin, C., Seltzer, M.
Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22)
interpretable machine learning, optimization, decision trees, machine learning
2021
Assuage: Assembly Synthesis Using A Guided Exploration
(PDF)
Hu, J., Vaithilingam, P., Chong, S., Seltzer, M., Glassman, E.
User-Interfaces Systems and Technology(UIST 2021)
program synthesis, interactive synthesis, assembly programming
ARTINALI#: An Efficient Intrusion Detection Technique for Resource-Constrained Cyber-Physical systems
(PDF)
Aliabadi, M., Seltzer, M., Asl, M., Ghavamizadeh, R.
International Journal of Critical Infrastructure Protection
intrusion detection, cyber-physical systems
SIGL: Securing Software Installations Through Deep Graph Learning
(PDF)
(video)
Han, X., Yu, X., Pasquier, T., Li, D., Rhee, J., Mickens, J., Seltzer, M., Haifent, C.
Proceedings of the USENIX Security Symposium, August 2021.
malware, software installation, provenance
2020
Parking Packet Payload with P4
(PDF)
Goswami, S., Kodirov, N., Mustard, C., Beschastnikh, I., Seltzer, M.
Proceedings of the International Conference on emerging Networking and Experiments and Technologies (CoNEXT)
P4, smart switches, network functions, NF
Generalized and Scalable Optimal Sparse Decision Trees
(PDF)
Lin, J., Zhong, C., Hu, D., Rudin, C., Seltzer, M.,
Proceedings of the International Conference on Machine Learning (ICML 2020)
optimization, decision trees, dynamic programming, branch and bound, machine learning
Unexpected Performance of Intel® OptaneTM DC Persistent Memory
(PDF)
Mason, T., Doudali, T., Seltzer, M., Gavrilovska, A.,
IEEE Computer Architecture Letters, 19(1), January-June 2020.
NVM, persistent memory, optane, performance
Xanthus: Push-button Orchestration of Host Provenance Data Collection
(PDF)
Han, X., Mickens, J., Gehani, A., Seltzer, M., Pasquier, T.,
Proceedings of the Third Annual Workshop on Practical Reproducible
Evaluation of Computer Systems (Co-located with HPDC 2020)
provenance, reproducibility, unicorn, intrustion detection, machine learning
Smooth Kronecker: Solving the Combing Problems in Kronecker Graphs
(PDF)
Anand, V., Mehrotra, P., Margo, D., Seltzer, M.,
Proceedings of the Joint Workshop on Graph Data Management Experiences
and Systems (GRADES) and Network Data Analytics (NDA) (Co-located with
SIGMOD 2020)
graph generator, kroneckor, benchmarking, graph
People of Data: The End-to-End Provenance Project
(PDF)
Ellison, A., Boose, E., Lerner, B., Fong, E., Seltzer, M.,
Patterns
R, provenance, data provenance, data science
Rclean: A Tool for Writing Cleaner, More Transparent Code
(PDF)
Lau, M., Pasquier T., Seltzer, M.,
JOSS: The Journal of Open Source Software
R, provenance, data provenance, data science, statistical analysis
A user-centered, learning asthma smartphone application for patients and
providers
(PDF)
Gaynor, M., Schneider, D., Seltzer, M., Crannage, E., Barron, M.,
Waterman, J., Oberle, A.,
Learning Health Systems
user-centered design, health, asthma, health app
Unicorn: Runtime Provenance-Based Detector for Advanced Persistent Threats
(PDF)
Han, X., Pasquier, T., Bates, A., Mickens, J., Seltzer, M.,
Network and Distributed System Security
Symposium (NDSS)
provenance, intrusion detection, CamFlow, machine learning
Improving Data Scientist Efficiency with Provenance
(PDF)
Hu, J., Joung, J., Jacobs, M., Gajos, K., Seltzer, M.,
International Conference on Software Engineering
provenance, data science, noWorkflow, incremental execution
2019
Optimal Sparse Decision Trees
(PDF)
Hu, X., Rudin, C., Seltzer, M.,
Conference on Neural Information Processing Systems (NeurIPS)
decision trees, interpretable machine learning, machine learning
ProvMark: A provenance expressiveness benchmarking system
(PDF)
Chan, S., Cheney, J., Bhatotia, P., Pasquier, T.,
Gehani, A., Irshad, H., Carata, L., Seltzer, M.,
International Middleware Conference
provenance, benchmarking, CamFlow
Trials and Tribulations in Synthesizing Operating Systems
(PDF)
Hu, J., Lu, E., Holland, D., Kawaguchi, M., Chong, S., Seltzer, M.,
Workshop on Programing Languages and Operating Systems (co-located with SOSP)
program synthesis, operating systems
Visonpaper -- From Here to Provtopia
(PDF)
Pasquier, T., Eyers, D., Seltzer, M.,
Towards Polystores that manage multiple Databases, Privacy, Security and/or Policy Issues for Heterogenous Data (POLY, co-located with VLDB 2019)</h5
provenance, compliance, GDPR
2018
Incentivizing Deep Fixes in Software Economies
(PDF)
Rao, M., Bacon, D.F., Parkes, D., Seltzer, M.
IEEE Transactions on Software Engineering. (June 2018, 21 pages) doi: 10.1109/TSE.2018.2842188
software engineering, bug fixing, econCS
Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using CrossReferencing Logs
(PDF)
Huang, Y., Pavlovic, M., Marathe, V., Seltzer, M., Harris, T., Byan, S.
Proceedings of the 2018 USENIX Annual Technical Conference, Boston MA, June 2018.
key value store, NVM, logging, logs
Sharing and Preserving Computational Analyses for Posterity with encapsulator
(PDF)
Pasquier, T., Lau, M., Han, X., Fong, E., Lerner, B., Boose, E., Crosas, M., Ellison, A., Seltzer, M.
IEEE Computing in Science and Engineering 20(111), July 2018. doi: or,” IEEE Computing in Science and Engineering 20(111), July 2018. doi: 10
provenance, reproducibility
Provenance-based Intrusion Detection: Opportunities
and Challenges
(PDF)
Han, X., Pasquier, T., Seltzer, M.
Proceedings of the Workshop on the Theory and Practice of Provenance (TaPP 2018), London UK, July 2018
provenance, intrusion detection, machine learning
Runtime Analysis of Whole-System Provenance
(PDF)
Pasquier, T., Han, X., Moyer, T., Bates, A., Hermant, O., Eyers, D., Bacon, J., Seltzer, M.
Proceedings of the 2018 Conference on Computer and Communications Security
(CCS '18), Toronto CA, October 2018.
camflow, provenance, data integrity
Learning Certifiably Optimal Rule Lists for Categorical Data
(PDF)
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M., Rudin, C.
Journal of Machine Learning Research 18 (2018) 1-78.
optimization, rule lists, machine learning, data structures
2017
Practical Whole-System Provenance Capture
(PDF)
Pasquier, T., Han, X., Goldstein, M., Moyer, T., Eyers, D., Seltzer, M., and Bacon, J., 2017.
Proceedings of SoCC ’17, Santa Clara, CA, USA, September 24–27, 2017.
provenance, camflow, os
Learning Certifiably Optimal Rule Lists
(PDF)
(video)
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M., Rudin, C.
Proceedings of the 23rd ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining (KDD), August 2017, 35-44.
optimization, rule lists, machine learning, data structures
If these data could talk
(PDF)
Pasquier, T., Lau, M., Trisovic, A., Boose, E., Couturier, B., Crosas, M., Ellison, A., Gibson, V., Jones, C., and Seltzer, M.
Nature Scientific Data, vol. 4, 2017.
provenance, reproducibility
Data Provenance to Audit Compliance with Privacy Policy
(PDF)
Pasquier, T., Singh, J., Powles, J., Eyers, D., Seltzer, M., Bacon, J.
Internet of Things, Journal of Personal and Ubiquitous Computing, published online Aug. 15, 2017.
provenance, privacy, compliance
Scalable Bayesian Rule Lists
(PDF)
Yang, H., Rudin, C., Seltzer, M.
Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, PMLR 70, 2017.
algorithms, rule lists, machine learning, mcmc
FRAPpuccino: Fault-detection through Runtime Analysis of Provenance
(PDF)
Han, X., Pasquier, T., Ranjan, T., Goldstein, M., and Seltzer, M.
Proceedings of the Workshop on Hot Topics in Cloud Computing (HotCloud’17), USENIX Association, Santa Clara, CA, July 2017.
provenance, fault detection, intrusion detection, security
Persistent Memcached: Bringing Legacy Code to Byte-Addressable Persistent Memory
(PDF)
Marathe, V., Seltzer, M., Byan, S., Harris, T.
Proceedings of USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 17) USENIX Association, Santa Clara, CA, July 2017.
persistent memory, nvm, storage, kvstore
A Crowdsourcing Approach to Collecting Tutorial Videos — Toward Personalized Learning-at-Scale
(PDF)
Whitehill, J., Seltzer, M.
Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale (L@S)
education
Sorting Shapes the Performance of Graph-Structured Systems
(PDF)
Daniel Wyatt Margo
Ph.D. Dissertation, Harvard John A. Paulson School of Engineering and Applied Sciences, March 27, 2017.
graphs, partitioning, performance, kronecker
2015
Towards General-Purpose Neural Network Computing
(PDF)
Eldridge, S., Appavoo, J., Joshi, A., Waterland, A., Seltzer, M.
Proceedings of the 13th International Conference on Parallel
Architectures and Compilation Techniques (PACT 2015), Petrozavodsk Russia, September 2015.
ASC, automatically scalable computing, neural networks
Recent advances in computer architecture: the opportunities and challenges for provenance.
(PDF)
Balakrishnan, Nikilesh, Thomas Bytheway, Lucian Carata, Oliver RA Chick, James Snee, Sherif Akoush, Ripduman Sohan, Margo Seltzer, and Andy Hopper
7th USENIX Workshop on the Theory and Practice of Provenance (TaPP 15). 2015.
provenance, architecture
A Scalable Distributed Graph Partitioner
(PDF)
Margo, D., Seltzer, M
Proceedings of the 41st International Conference on Very Large Data Bases, Kohala Coast, Hawaii, August 2015, pp 1478-1489.
graphs, algorithms
LLAMA: Efficient Graph Analytics Using Large Multiversioned Arrays
(PDF)
Macko, P., Margo, D., Marathe, V., Seltzer, M.
Proceedings of the 31st IEEE International Conference on Data Engineering (ICDE 2015), Seoul Korea, April 2015.
graphs, algorithms, data structures, storage
2014
Accelerating MCMC via parallel predictive prefetching
(PDF)
Angelino, E., Kohler, E., Waterland, A., Seltzer, M., Adams, M.
Proceedings of the 2014 Conference on Uncertainty in Artificial Intelligence (UAI '14), Quebec City, Quebec Canada, July 2014.
algorithms, mcmc, asc
Proceedings of the AAAI 2014 Workshop on Incentives and Trust in E-Communities (WIT-EC'14)
(PDF)
Rao, M., Parkes, D., Seltzer, M., and Bacon, D.
Quebec City, Quebec Canada, July 2014.
incentives, econcs
Programmable Smart Machines: A Hybrid Neuromorphic approach to General Purpose Computation
(PDF)
Appavoo, J., Waterland, A., Eldridge, S., Zhao, K,. Joshi, A, Homer, S, Seltzer, M.
Proceedings of the first workshop on Neuromorphic Architectures
(NeuroArch) collocated with ISCA, June 2014.
ASC, automatically scalable computation, neuromorphic
A Primer on Provenance
(PDF)
Carata, L, Akoush, S., Balakrishnan, N., Bytheway, T., Sohan, R., Seltzer, M., Hopper, A.
ACM Queue 12(3), April 2014.
provenance
ASC: Automatically Scalable Computation
(PDF)
Waterland, A., Angelino, E., Adams, R., Appavoo, J., Seltzer, M.
Proceedings of the 2014 Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '14) (IEEE Top Pick), Salt Lake City Utah, March 2014.
ASC, automatically scalable computation, architecture, machine learning, parallelization, dynamical system
2013
Applying KISS to Healthcare Information Technology
(PDF)
Herzlinger, R., Seltzer, M., Gaynor, M.
Computer 46(11), IEEE, November 2013, 72--74.
healthcare technology
Evaluation of Filesystem Provenance Visualization Tools
Borkin, M., Yeh, C., Boyd, M., Macko, P., Gajos, K., Seltzer, M., Pfister, H.
Proceedings of the 2013 International Conference on Information Visualization (Vis 2013), Atlanta GA, October 2013.
provenance, visualization
Local Clustering in Provenance Graphs
(PDF)
Macko, P., Margo, D., Seltzer, M.
Proceedings of the 2013 International Conference on Information and Knowledge Management (CIKM 2013), Burlingame CA, October 2013.
provenance, algorithms, metrics
Performance Introspection of Graph Databases
Abstract
The explosion of graph data in social and biological networks, recommendation systems, provenance databases, etc. makes graph storage and processing of paramount importance. We present a performance introspection framework for graph databases, PIG, which provides both a toolset and methodology for understanding graph database performance. PIG consists of a hierarchical collection of benchmarks that compose to produce performance models; the models provide a way to illuminate the strengths and weaknesses of a particular implementation. The suite has three layers of benchmarks: primitive operations, composite access patterns, and graph algorithms. While the framework could be used to compare different graph database systems, its primary goal is to help explain the observed performance of a particular system. Such introspection allows one to evaluate the degree to which systems exploit their knowledge of graph access patterns. We present both the PIG methodology and infrastructure and then demonstrate its efficacy by analyzing the popular Neo4j and DEX graph databases.
PDF
Slides (PDF)
Macko, P., Margo, D., Seltzer, M.
Proceedings of the 2013 SYSTOR Conference, Haifa Israel, July 2013.
graphs, benchmarking
Computational Caches
Abstract
Caching is a well-known technique for speeding up computation. We cache data from file systems and databases; we cache dynamically generated code blocks; we cache page translations in TLBs. We propose to cache the act of computation, so that we can apply it later and in different contexts. We use a state-space model of computation to support such caching, involving two interrelated parts: speculatively memoized predicted/resultant state pairs that we use to accelerate sequential computation, and trained probabilistic models that we use to generate predicted states from which to speculatively execute. The key techniques that make this approach feasible are designing probabilistic models that automatically focus on regions of program execution state space in which prediction is tractable and identifying state space equivalence classes so that predictions need not be exact.
PDF
Slides (PDF)
Waterland, A., Angelino, E., Cubuk, E., Kaziras, E., Adams, R., Appavoo, J., Seltzer, M.
Proceedings of the 2013 SYSTOR Conference, Haifa Israel, July 2013.
asc, caching
Flash Caching on the Storage Client
Abstract
Flash memory has recently become popular as a caching medium. Most uses to date are on the storage server side. We investigate a different structure: flash as a cache on the client side of a networked storage environment. We use trace-driven simulation to explore the design space. We consider a wide range of configurations and policies to determine the potential client-side caches might offer and how best to arrange them.
Our results show that the flash cache writeback policy does not significantly affect performance. Write-through is sufficient; this greatly simplifies cache consistency handling. We also find that the chief benefit of the flash cache is its size, not its persistence. Cache persistence of- fers additional performance benefits at system restart at essentially no runtime cost. Finally, for some workloads a large flash cache allows using miniscule amounts of RAM for file caching (e.g., 256 KB) leaving more mem- ory available for application use.
PDF
Slides (PDF)
Holland, D., Angelino, E., Wald, G., Seltzer, M.
Proceedings of the 2013 USENIX Annual Technical Conference, San Jose, CA, June 2013.
caching, storage, nvm
2012
2011
A General-Purpose Provenance Library
Abstract
Most provenance capture takes place inside particular tools – a workflow engine, a database, an operating system, or an application. However, most users have an existing toolset – a collection of different tools that work well for their needs and with which they are comfortable. Currently, such users have limited ability to collect provenance without disrupting their work and changing environments, which most users are hesitant to do. Even users who are willing to adopt new tools, may realize limited benefit from provenance in those tools if they do not integrate with their entire environment, which may include multiple languages and frameworks.
We present the Core Provenance Library (CPL), a portable, multi-lingual library that application programmers can easily incorporate into a variety of tools to collect and integrate provenance. Although the manual instrumentation adds extra work for application programmers, we show that in most cases, the work is minimal, and the resulting system solves several problems that plague more constrained provenance collection systems.
PDF
Slides (PDF)
Macko, P., Seltzer, M.
Proceedings of the Fourth Workshop on the Theory and Practice of Provenance (TaPP 2012), Boston MA, June 2012.
provenance, software
Provenance Integration Requires Reconciliation
Abstract
While there has been a great deal of research on provenance systems, there has been little discussion about challenges that arise when making different provenance systems interoperate. In fact, most of the literature focuses on provenance systems in isolation and does not discuss interoperability – what it means, its requirements, and how to achieve it. We designed the Provenance-Aware Storage System to be a general- purpose substrate on top of which it would be “easy” to add other provenance-aware systems in a way that would provide “seamless integration” for the provenance captured at each level. While the system did exactly what we wanted on toy problems, when we began integrating StarFlow, a Python-based workflow/provenance system, we discovered that integration is far trickier and more subtle than anyone has suggested in the literature. This work describes our experience undertaking the integration of StarFlow and PASS, identifying several important additions to existing provenance models necessary for interoperability among provenance systems.
PDF
Slides (PDF)
Angelino, E., Braun, U., Holland, D., Macko, P., Margo, D., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance
Provenance Map Orbiter: Interactive Exploration of Large Provenance Graphs
Abstract
Provenance systems can produce enormous provenance graphs that can be used for a variety of tasks from deter- mining the inputs to a particular process to debugging entire workflow executions or tracking difficult-to-find dependencies. Visualization can be a useful tool to sup- port such tasks, but graphs of such scale (thousands to millions of nodes) are notoriously difficult to visualize. This paper presents the Provenance Map Orbiter, a tool for interactively exploring large provenance graphs using graph summarization and semantic zoom. It presents its users with a high-level abstracted view of the graph and the ability to incrementally drill down to the details.
PDF
Macko, P., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance, graphs, visualization
Collecting Provenance via the Xen Hypervisor
Abstract
The Provenance Aware Storage Systems project (PASS) currently collects system-level provenance by intercepting system calls in the Linux kernel and storing the provenance in a stackable filesystem. While this approach is reasonably efficient, it suffers from two significant drawbacks: each new revision of the kernel requires reintegration of PASS changes, the stability of which must be continually tested; also, the use of a stackable filesystem makes it difficult to collect provenance on root volumes, especially during early boot. In this paper we describe an approach to collecting system-level provenance from virtual guest machines running under the Xen hypervisor. We make the case that our approach alleviates the aforementioned difficulties and promotes adoption of provenance collection within cloud comput- ing platforms.
PDF
Slides (PDF)
Macko, P., Chiarini, M., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance, virtualization
Dimetrodon: Processor-level Preventive Thermal Management via Idle Cycle Injection
Abstract
Processor-level dynamic thermal management techniques have long targeted worst-case thermal margins. We examine the thermal-performance trade-offs in average-case, preventive thermal management by actively degrading application performance to achieve long-term thermal control. We propose Dimetrodon, the use of idle cycle injection, a flexible, per-thread technique, as a preventive thermal management mechanism and demonstrate its efficiency compared to hardware techniques in a commodity operating system on real hardware under throughput and latency-sensitive real-world workloads. Compared to hardware techniques that also lack flexibility, Dimetrodon achieves favorable trade-offs for temperature reductions up to 30% due to rapid heat dissipation during short idle intervals.
PDF
Peter Bailis, Vijay Janapa Reddi, Sanjay Gandhi, David Brooks, and Margo Seltzer
Proceeeding of the 2011 Design Automation Conference (DAC 2011), San Diego, CA, June 2011. Seltzer
architecture, scheduling, energy
Benchmarking File System Benchmarking: It *IS* Rocket Science
Abstract
The quality of file system benchmarking has not improved in over a decade of intense research spanning hundreds of publications. Researchers repeatedly use a wide range of poorly designed benchmarks, and in most cases, develop their own ad-hoc benchmarks. Our community lacks a definition of what we want to benchmark in a file system. We propose several dimensions of file system benchmarking and review the wide range of tools and techniques in widespread use. We experimentally show that even the simplest of benchmarks can be fragile, producing performance results spanning orders of magnitude. It is our hope that this paper will spur serious debate in our community, leading to action that can improve how we evaluate our file and storage systems.
PDF
Vasiliy Tarasov, Saumitra Hanage, Erez Zadok, Margo Seltzer
Proceedings of the 2011 Workshop on Hot Topics in Operating Systems (HOTOS XIII), Napa, CA, May 2011.
file systems, benchmarking, storage
Multicore OSes: Looking Forward from 1991, er, 2011
Abstract
Upcoming multicore processors, with hundreds of cores or more in a single chip, require a degree of parallel scalability that is not currently available in today’s system software. Based on prior experience in the supercomputing sector, the likely trend for multicore processors is away from shared memory and toward sharednothing architectures based on message passing. In light of this, the lightweight messages and channels programming model, found among other places in Erlang, is likely the best way forward. This paper discusses what adopting this model entails, describes the architecture of an OS based on this model, and outlines a few likely implementation challenges.
PDF
Slides (PDF)
David Holland, Margo Seltzer
Proceedings of the 2011 Workshop on Hot Topics in Operating Systems (HOTOS XIII), Napa, CA, May 2011.
os, operating systems
Mining the Web for Medical Hypotheses: A Proof-of-Concept System
Abstract
As the prevalence of blogs, discussion forums, and online news services continues to grow, so too does the portion of this Web content that relates to health and medicine. We propose that everyday, medically-oriented Web content is a valuable and viable data source for medical hypothesis generation and testing, despite its being noisy. In this paper, we present a proof-of-concept system supporting this notion. We construct a corpus comprising news articles relating to the drugs Vioxx, Naproxen and Ibuprofen, that were published between 1998-2002. Using this corpus, we show that there was a significant link between Vioxx and the concept “Myocardial Infarction” well before the drug was withdrawn from the market in 2004. Indeed, within the Vioxx-related content, the concept ranks amongst the top 3.3% in terms of importance. When compared with the Naproxen and Ibuprofen control literatures, the term occurs significantly more frequently in the Vioxx- related content.
PDF
Diana Maclean, Margo Seltzer
Proceedings of the International Conference on Health Informatics, Rome Italy, January 2011.
medical, data mining
2010
Tracking Back References in a Write-Anywhere File System
Abstract
Many file systems reorganize data on disk, for example to defragment storage, shrink volumes, or migrate data between different classes of storage. Advanced file system features such as snapshots, writable clones, and deduplication make these tasks complicated, as moving a single block may require finding and updating dozens, or even hundreds, of pointers to it.
We present Backlog, an efficient implementation of explicit back references, to address this problem. Back references are file system meta-data that map physical block numbers to the data objects that use them. We show that by using LSM-Trees and exploiting the write-anywhere behavior of modern file systems such as NetApp R WAFL R or btrfs, we can maintain back reference meta-data with minimal overhead (one extra disk I/O per 102 block operations) and provide excel- lent query performance for the common case of queries covering ranges of physically adjacent blocks.
PDF
Peter Macko, Margo Seltzer, Keith A. Smith
Proceedings of the 8th Conference on File and Storage Technologies (FAST'10), San Jose, CA, February 2010.
storage, file systems
Provenance for the Cloud
Abstract
The cloud is poised to become the next computing environment for both data storage and computation due to its pay-as-you-go and provision-as-you-go models. Cloud storage is already being used to back up desktop user data, host shared scientific data, store web application data, and to serve web pages. Today's cloud stores, however, are missing an important ingredient: provenance.
Provenance is metadata that describes the history of an object. We make the case that provenance is crucial for data stored on the cloud and identify the properties of provenance that enable its utility. We then examine current cloud offerings and design and implement three protocols for maintaining data/provenance in current cloud stores. The protocols represent different points in the de- sign space and satisfy different subsets of the provenance properties. Our evaluation indicates that the overheads of all three protocols are comparable to each other and reasonable in absolute terms. Thus, one can select a protocol based upon the properties it provides without sacrificing performance. While it is feasible to provide provenance as a layer on top of today's cloud offerings, we conclude by presenting the case for incorporating provenance as a core cloud feature, discussing the issues in doing so.
PDF
Kira-Kumar Muniswamy-Reddy, Peter Macko, Margo Seltzer
Proceedings of the 8th Conference on File and Storage Technologies (FAST'10), San Jose, CA, February 2010.
cloud, provenance
Towards Query Interoperability: PASSing PLUS
Abstract
We describe our experiences importing PASS provenance into PLUS. Although both systems import and export provenance that conforms to the Open Provenance Model (OPM), the two systems vary greatly with respect to the granularity of provenance captured, how much semantic knowledge the system contributes, and the completeness of provenance capture. We encountered several problems reconciling provenance between the two systems and use that experience to specify a Common Provenance Framework, that provides a higher degree of interoperability between provenance systems. In each case, the problems stem from the fact that OPM interoperability is a weaker requirement than query interoperability. Our goal in presenting this work is to generate discussion about differing degrees of interoperability and the requirements thereof.
PDF
Slides (PDF)
Uri Braun, Margo Seltzer, Adriane Chapman, Barbara Blaustein, M. David Allen, Len Seligman
Proceedings of the 2nd Workshop on the Theory and Practice of Provenance (TaPP'10) San Jose, CA, February 2010.
provenance
Provenance as first class cloud data
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Muniswamy-Reddy, K. and Seltzer, M.
Operating Systems Review, ACM 43, 4 (Jan. 2010), 11-16.
provenance, cloud
2009
Provenance: a future history.
Abstract
Science, industry, and society are being revolutionized by radical new capabilities for information sharing, distributed computation, and collaboration offered by the World Wide Web. This revolution promises dramatic benefits but also poses serious risks due to the fluid nature of digital information. One important cross-cutting issue is managing and recording provenance, or metadata about the origin, context, or history of data. We posit that provenance will play a central role in emerging advanced digital infrastructures. In this paper, we outline the current state of provenance research and practice, identify hard open research problems involving provenance semantics, formal modeling, and security, and articulate a vision for the future of provenance.
PDF
Cheney, J., Chong, S., Foster, N., Seltzer, M., and Vansummeren, S.
Proceeding of the 24th ACM SIGPLAN Conference Companion on Object Oriented Programming Systems Languages and Applications (Orlando, Florida, USA, October 25 - 29, 2009). OOPSLA '09. ACM, New York, NY, 957-964.
provenance
Provenance as First-Class Cloud Data
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Muniswamy-Reddy, K., Seltzer, M.
3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (LADIS'09), October 2009.
provenance, cloud
Layering in Provenance Systems
Abstract
Digital provenance describes the ancestry or history of a digital object. Most existing provenance systems, however, operate at only one level of abstraction: the system call layer, a workflow specification, or the high-level constructs of a particular application. The provenance collectable in each of these layers is different, and all of it can be important. Single-layer systems fail to account for the different levels of abstraction at which users need to reason about their data and processes. These systems cannot integrate data provenance across layers and cannot answer questions that require an integrated view of the provenance.
We have designed a provenance collection structure facilitating the integration of provenance across multiple levels of abstraction, including a workflow engine, a web browser, and an initial runtime Python provenance tracking wrapper. We layer these components atop provenance-aware network storage (NFS) that builds upon a Provenance-Aware Storage System (PASS). We discuss the challenges of building systems that integrate provenance across multiple layers of abstraction, present how we augmented systems in each layer to integrate provenance, and present use cases that demonstrate how provenance spanning multiple layers provides functionality not available in existing systems. Our evaluation shows that the overheads imposed by layering provenance systems are reasonable.
HTML
PDF
Slides (PDF)
Muniswamy-Reddy, K., Braun, U., Holland, D., Macko, P., Maclean, D., Margo, D., Seltzer, M., Smogor, R.
Proceedings of the 2009 USENIX Annual Technical Conference, San Diego, CA, June 2009.
provenance, os
Hierarchical File Systems Are Dead
Abstract
For over forty years, we have assumed hierarchical file system namespaces. These namespaces were a rudimentary attempt at simple organization. As users have begun to interact with increasing amounts of data and are increasingly demanding search capability, such a simple hierarchical model has outlasted its usefulness. For this reason, we should design file systems whose organizations map to the ways we access and manipulate data now. We present a new file system architecture in which we replace the hierarchical namespace with a tagged, search-based one.
PDF
Slides (PDF)
Seltzer, M., Murphy, M.
Proceedings of the 12th Workshop on Hot Topics in Operating Systems (HOTOS'09), Monte Verita, Switzerland, May 2009.
file systems, storage
The Case for Browser Provenance
(PDF)
Margo, D., Seltzer, M.
1st Workshop on the Theory and Practice of Provenance (TaPP'09), February 2009.
provenance, ui
Making a Cloud Provenance-Aware
(PDF)
Muniswamy-Reddy, K., Seltzer, M.
1st Workshop on the Theory and Practice of Provenance (TaPP'09), February 2009.
provenance, cloud
2008
Securing Provenance
(PDF)
Braun, U., Shinnar, A., Seltzer, M.
Proceedings of the 3rd USENIX Workshop on Hot Topics in Security (HotSec), San Jose, CA, July 2008.
provenance, security
Choosing a Data Model and Query Language for Provenance
(PDF)
Holland, D., Braun, U., Maclean, D., Muniswamy-Reddy, K., Seltzer, M.
Proceedings of the 2nd International Provenance and Annotation Workshop, Salt Lake City, UT, Jun 2008.
provenance, pl
2007
Improving Performance Isolation on Chip Multiprocessors via an Operating System Scheduler
Abstract
We describe a new operating system scheduling algorithm that improves performance isolation on chip multiprocessors (CMP). Poor performance isolation occurs when an application’s performance is determined by the behaviour of its co-runners, i.e., other applications simultaneously running with it. This performance dependency is caused by unfair, co- runner-dependent cache allocation on CMPs. Poor performance isolation interferes with the operating system’s control over priority enforcement and hinders QoS provisioning. Previous solutions required modifications to the hardware. We present a new software solution. Our cache-fair algorithm ensures that the application runs as quickly as it would under fair cache allocation, regardless of how the cache is actually allocated. If the thread executes fewer instructions per cycle than it would under fair cache allocation, the scheduler increases that thread’s CPU timeslice. This way, the thread’s overall performance does not suffer because it is allowed to use the CPU longer. We describe our implementation of the algorithm in SolarisTM 10, and show that it significantly improves performance isolation for SPEC CPU, SPEC JBB and TPC-C.
PDF
Fedorova, A., Seltzer, M., Smith, M.D.
Proceedings of the Sixteenth International Conference on Parallel Architectures and Compilation Techniques (PACT), Brasov, Romania, September 2007.
operating systems, scheduling
Can a System Virtualize Processors?
(PDF, Slides)
Stein, L., Holland, D., Seltzer, M., Zhang, Z.
Proceedings of the First EuroSys Workshop on Virtualization for HPC, Lisbon, Portugal, March 2007.
virtualization
PASS-ing the Provenance Challenge
(PDF)
Holland, D., Seltzer, M., Braun, U., Muniswamy-Reddy, K.
Special Edition of Concurrency and Computation: Practice and Experience Wiley and Sons, 2007.
provenance
Network Coordinates in the Wild
Abstract
Network coordinates provide a mechanism for selecting and placing servers efficiently in a large distributed system. This approach works well as long as the coordinates continue to accurately reflect network topology. We conducted a long-term study of a subset of a million-plus node coordinate system and found that it exhibited some of the problems for which network coordinates are frequently criticized, for example, inaccuracy and fragility in the presence of violations of the triangle inequality. Fortunately, we show that several simple techniques remedy many of these problems. Using the Azureus BitTorrent network as our testbed, we show that live, large-scale network coordinate systems behave differently than their tame PlanetLab and simulation-based counterparts. We find higher relative errors, more triangle inequality violations, and higher churn. We present and evaluate a number of techniques that, when applied to Azureus, efficiently produce accurate and stable network coordinates
HTML
PDF
Ledlie, J., Gardner, P., Seltzer, M.
Proceedings of the Conference on Network System Design and Implementation, Boston MA, April 2007.
networking
2006
Data Management for Internet-Scale Single-Sign-On
(PDF)
Sharon Perl, Margo Seltzer
2006 USENIX Workshop on Real, Large Distributed Systems (Worlds '06)
single sign-on, berkeley-db, BDB-HA, replication, high-availability
A Non-Work-Conserving Operating System Scheduler For SMT Processors
(PDF)
Fedorova, A., Seltzer, M., Smith, M.D.
Proceedings of the Workshop on the Interaction between Operating Systems and Computer Architecture (WIOSCA 2006), Boston MA, June 2006.
operating systems, scheduling
Provenance-Aware Storage Systems
Abstract
A Provenance-Aware Storage System (PASS) is a storage system that automatically collects and maintains prove- nance or lineage, the complete history or ancestry of an item. We discuss the advantages of treating provenance as meta-data collected and maintained by the storage system, rather than as manual annotations stored in a separately administered database. We describe a PASS implementation, discussing the challenges it presents, performance cost it incurs, and the new functionality it enables. We show that with reasonable overhead, we can provide useful functionality not available in today's file systems or provenance management systems.
HTML
PDF
Muniswamy-Reddy, K., Holland, D., Braun, U., Seltzer, M.
Proceedings of the 2006 USENIX Annual Technical Conference, Boston, MA, June 2006.
provenance, storage, file systems
Issues in Automatic Provenance Collection
Abstract
Automatic provenance collection describes systems that observe processes and data transformations inferring, collecting, and maintaining provenance about them. Automatic collection is a powerful tool for analysis of ob jects and processes, providing a level of transparency and pervasiveness not found in more conventional provenance systems. Unfortunately, automatic collection is also difficult. We discuss the challenges we encountered and the issues we exposed as we developed an automatic provenance collector that runs at the operating system level.
PDF
Braun, U., Garfinkel, S., Holland, D., Muniswamy-Reddy, K., Seltzer, M.,
Proceedings of the 2006 International Provenance and Annotation Workshop, Chicago, IL, May 2006.
provenance
EGG: An Extensible and Economics-inspired Open Grid Computing Platform
Abstract
The Egg project provides a vision and implementation of how heterogeneous computational requirements will be supported within a single grid and a compelling reason to explain why computational grids will thrive. Environment computing, which allows a user to specify properties that a compute environment must satisfy in order to support the users computation, provides a how. Economic principles, allowing resource owners, users, and other stakeholders to make value and policy statements, provides a why. The Egg project introduces a language for defining software environments (egg shell), a general type for grid objects (the cache), and a currency (the egg). The Egg platform resembles an economically driven Internet-wide Unix system with egg shell playing the role of a scripting language and caches playing the role of a global file system, including an initial collection of devices.
PDF
Slides (PDF)
Brunelle, J., Hurst, P., Huth, J., Kang, L., Ng, C., Parkes, D., Seltzer, M., Shank, J., Youssef, S.
Proceedings of the 2006 Grid Asia, Singapore, May 2006.
econcs
Network-Aware Operator Placement for Stream-Processing Systems
Abstract
To use their pool of resources efficiently, distributed stream-processing systems push query operators to nodes within the network. Currently, these operators, ranging from simple filters to custom business logic, are placed manually at intermediate nodes along the transmission path to meet application-specific performance goals. Determining placement locations is challenging because network and node conditions change over time and because streams may interact with each other, opening venues for reuse and repositioning of operators.
This paper describes a stream-based overlay network (SBON), a layer between a stream-processing system and the physical network that manages operator placement for stream-processing systems. Our design is based on a cost space, an abstract representation of the network and on-going streams, which permits decentralized, large-scale multi-query optimization decisions. We present an evaluation of the SBON approach through simulation, experiments on PlanetLab, and an integration with Borealis, an existing stream-processing engine. Our results show that an SBON consistently improves network utilization, provides low stream latency, and enables dynamic optimization at low engineering cost.
PDF
Pietzuch, P., Ledlie, J., Shneidman, J., Roussopoulos, M., Welsh, M., Seltzer, M.
Proceedings fo the 22nd International Conference on Data Engineering (ICDE ’06), Atlanta, GA, April 2006.
networking
2005
Supporting Network Coordinates on PlanetLab
Abstract
Large-scale distributed applications need latency information to make network-aware routing decisions. Collecting these measurements, however, can impose a high burden. Network coordinates are a scalable and efficient way to supply nodes with up-to-date latency estimates. We present our experience of maintaining network coordinates on PlanetLab. We present two different APIs for accessing coordinates: a per-application library, which takes advantage of application-level traffic, and a stand-alone service, which is shared across applications. Our results show that statistical filtering of latency samples improves accuracy and stability and that a small number of neighbors is sufficient when updating coordinates.
PDF
Pietzuch, P., Ledlie, J., Seltzer, M.
Proceedings of the Second Workshop on Real, Large Distributed Systems (WORLDS’05), San Francisco, CA, December 2005.
networking
Beyond Relational Databases
Abstract
This article discusses how data management needs vary across applications, pointing out that one needs to match database solutions with data management needs.
PDF
Seltzer, M.
ACM Queue, 3,3 April 2005
databases, kvstore
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design
Abstract
We investigated how operating system design should be adapted for multithreaded chip multiprocessors (CMT) -- a new generation of processors that exploit thread-level parallelism to mask the memory latency in modern workloads. We determined that the L2 cache is a critical shared resource on CMT and that an insufficient amount of L2 cache can undermine the ability to hide memory latency on these processors. To use the L2 cache as efficiently as possible, we propose an L2-conscious scheduling algorithm and quantify its performance potential. Using this algorithm it is possible to reduce miss ratios in the L2 cache by 25-37% and improve processor throughput by 27-45%.
PDF
Fedorova, A., Seltzer, M., Small, C., Nussbaum, D.
Proceedings of the 2005 Annual Technical Conference, Anaheim, CA April 2005.
operating systems, caching, scheduling
A Cost-Space Approach to Distributed Query Optimization in Stream-Based Overlays
Abstract
Distributed stream-based applications, such as continuous query systems, have network scale and time characteristics that challenge traditional distributed query optimization. The optimization sub-problems of plan generation and service placement should be integrated to meet these challenges. These tasks have typically been treated as independent sub-problems because of the complexity of their integration. We suggest cost spaces as one way to mitigate this complexity. We further consider how cost spaces can be used to allow tractable multi-query optimization.
PDF
Shneidman, J., Pietzuch, P., Welsh, M., Seltzer, M., Roussopoulos, M.
Proceedings of the 1st IEEE International Workshop on Networking Meets Databases (NetDB’05), Tokyo, Japan, April 2005.
algorithms, networking, p2p
Provenance Aware Sensor Data Storage
Abstract
Sensor network data has both historical and real-time value. Making historical sensor data useful, in particular, requires storage, naming, and indexing. Sensor data presents new challenges in these areas. Such data is location-specific but also distributed; it is collected in a particular physical location and may be most useful there, but it has additional value when com- bined with other sensor data collections in a larger distributed sys- tem. Thus, arranging location-sensitive peer-to-peer storage is one challenge. Sensor data sets do not have obvious names, so naming them in a globally useful fashion is another challenge. The last challenge arises from the need to index these sensor data sets to make them searchable. The key to sensor data identity is prove- nance, the full history or lineage of the data. We show how prove- nance addresses the naming and indexing issues and then present a research agenda for constructing distributed, indexed repositories of sensor data.
PDF
Slides (PDF)
Ledlie, J., Ng, C., Holland, D., Muniswamy-Reddy, K., Braun, U., Seltzer, M.
Proceedings of the 1st IEEE International Workshop on Networking Meets Databases (NetDB05) Tokyo, Japan, April 2005.
provenance, sensor networks, iot, naming
Distributed, Secure Load Balancing with Skew, Heterogeneity, and Churn
Abstract
Numerous proposals exist for load balancing in peer-to-peer (p2p) networks. Some focus on namespace balancing, making the distance between nodes as uniform as possible. This technique works well under ideal conditions, but not under those found empirically. Instead, researchers have found heavy-tailed query distributions (skew), high rates of node join and leave (churn), and wide variation in node network and storage capacity (heterogeneity). Other approaches tackle these less-than-ideal conditions, but give up on important security properties. We propose an algorithm that both facilitates good performance and does not dilute security. Our algorithm, k-Choices, achieves load balance by greedily matching nodes' target workloads with actual applied workloads through limited sampling, and limits any fundamental decrease in security by basing each node's set of potential identifiers on a single certificate. Our algorithm compares favorably to four others in trace-driven simulations. We have implemented our algorithm and found that it improved aggregate throughput by 20% in a widely heterogeneous system in our experiments.
PDF
Slides (PDF)
Ledlie, J., Seltzer, M.
Proceedings of the 2005 INFOCOM, March 2005.
algorithms, p2p, load balancing
Evaluating DHT Service Placement in Stream-Based Overlays
Abstract
Stream-based overlay networks (SBONs) are one approach to implementing large-scale stream processing systems. A fundamental consideration in an SBON is that of service placement, which determines the physical location of in-network processing services or operators, in such a way that network resources are used efficiently. Service placement consists of two components: node discovery, which selects a candidate set of nodes on which services might be placed, and node selection, which chooses the particular node to host a service. By viewing the placement problem as the composition of these two processes we can trade-off quality and efficiency between them. A bad discovery scheme can yield a good placement, but at the cost of an expensive selection mechanism.
Recent work on operator placement proposes to leverage routing paths in a distributed hash table (DHT) to obtain a set of candidate nodes for service placement. We evaluate the appropriateness of using DHT routing paths for service placement in an SBON, when aiming to minimize network usage. For this, we consider two DHT-based algorithms for node discovery, which use either the union or intersection of DHT routing paths in the SBON, and compare their performance to other techniques. We show that current DHT-based schemes are actually rather poor node discovery algorithms, when minimizing network utilization. An efficient DHT may not traverse enough hops to obtain a sufficiently large candidate set for placement. The union of DHT routes may result in a low-quality set of discovered nodes that requires an expensive node selection algorithm. Finally, the intersection of DHT routes relies on route convergence, which prevents the placement of services with a large fan-in.
PDF
Pietzuch, P, Shneidman, J., Ledlie, J., Welsh, M., Seltzer, M., Roussopoulos, M.
Proceedings of the International Workshop on Peer to Peer Systems (IPTPS’05), Ithaca, NY, February 2005.
algorithms, p2p, networking
2004
An Architecture A Day Keeps the Hacker Away
Abstract
System security as it is practiced today is a losing battle. In this paper, we outline a possible comprehensive solution for binary-based attacks, using virtual machines, machine descriptions, and randomization to achieve broad heterogeneity at the machine level. This heterogeneity increases the "cost" of broad-based binary attacks to a sufficiently high level that they cease to become feasible. The convergence of several recent technologies appears to make our approach achievable at a reasonable cost, with only moderate run-time overhead.
PDF
Slides (PDF)
Holland, D., Lim, A., Seltzer, M.
Proceedings of the 2004 Workshop on Architectural Support for Security and Anti-Virus," Boston, MA, April 2004.
architecture, synthesis
Open Problems in Data Collection
Abstract
Research in sensor networks, continuous queries (CQ), and other domains has been motivated by powerful applications that aim to aggregate, assimilate, and interact with scores of sensor networks in parallel. Numerous system ingredients are necessary to make these applications possible. Sensor network research is building some of these components from the bottom up, dealing with issues such as wireless connectivity and battery life. CQ, peer-to-peer (P2P), and other research areas are building top down, examining in-network services, naming, decentralized queries, and scale. While many research groups use the same types of applications to motivate their work, many of these applications cannot be built today because of missing bridge research. These challenges include: uniting vastly differing devices and services, managing intermittent connectivity, placing in-network services with QoS and other constraints, developing unified security models, and correlating between sensor networks. This paper distills these new problems and outlines one proposed system that explores solutions to these concerns.
PDF
Ledlie, J., Shneidman, J., Welsh, M., Roussopoulos, M. Seltzer, M.
Networks Proceedings of the 2004 SIGOPS European Workshop, September 2004, Leuven, Belgium.
networking, sensor networks, p2p
Chip Multithreading Systems Need a New Operating System Scheduler
Abstract
The unpredictable nature of modern workloads, characterized by frequent branches and control transfers, can result in processor pipeline utilization as low as 19%. Chip multithreading (CMT), a processor architecture combining chip multiprocessing and hardware multithreading, is designed to address this issue. Hardware vendors plan to ship CMT systems within the next two years; understanding how such systems will perform is crucial if we are to use them to full advantage.
Our simulation experiments show that a CMT-savvy operating system scheduler could improve application performance by a factor of two. In this paper we describe our initial analysis of application performance on CMT systems and propose a design for a scheduler tailored for the needs of a CMT system.
PDF
Fedorova, A., Small, C., Nussbaum, D., Seltzer, M.
Proceedings of the 2004 SIGOPS EUropean Workshop, September 2004, Leuven, Belgium.
operating systems, scheduling
File classification in self-* storage systems
Abstract
To tune and manage themselves, file and storage systems must understand key properties (e.g., access pattern, lifetime, size) of their various files. This paper describes how systems can automatically learn to classify the properties of files (e.g., read-only access pattern, short-lived, small in size) and predict the properties of new files, as they are created, by exploiting the strong associations between a file's properties and the names and attributes assigned to it. These associations exist, strongly but differently, in each of four real NFS environments studied. Decision tree classifiers can automatically identify and model such associations, providing prediction accuracies that often exceed 90%. Such predictions can be used to select storage policies (e.g., disk allocation schemes and replication factors) for individual files. Further, changes in associations can expose information about applications, helping autonomic system components distinguish growth from fundamental change.
PDF
PostScript
Mesnier, M., Thereska, E., Ellard, D., Ganger, G., Seltzer, M.
Proceedings of the International Conference on Autonomic Computing (ICAC-04), May 2004, New York, NY.
file systems, naming
The Case Against User-level Networking
Abstract
Extensive research on system support for enabling I/O-intensive applications to achieve performance close to the limits imposed by the hardware suggests two main approaches: Low overhead I/O protocols and the flexibility to customize I/O policies to the needs of applications. One way to achieve both is by supporting user-level access to I/O devices, enabling user-level implementations of I/O protocols. User-level networking is an example of this approach, specific to network interface controllers (NICs). In this paper, we argue that the real key to high-performance in I/O-intensive applications is user-level file caching and user-level network buffering, both of which can be achieved without user-level access to NICs.
Avoiding the need to support user-level networking carries two important benefits for overall system design: First, a NIC exporting a privileged kernel interface is simpler to design and implement than one exporting a user-level interface. Second, the kernel is re-instated as a global system resource controller and arbitrator. We develop an analytical model of network storage applications and use it to show that their performance is not affected by the use of a kernel-based API to NICs.
PDF
Magoutis, K., Seltzer, M., Gabber, E.
Proceedings of the Third Annual Workshop on System-Area Networks (SAN-3), February 2004, Madrid Spain.
operating systems, networking
Application Performance on the Direct Access File System
Abstract
The Direct Access File System (DAFS) is a distributed file system built on top of direct-access transports (DAT). Direct- access transports are characterized by using remote direct memory access (RDMA) for data transfer and user-level networking. The motivation behind the DAT-enabled distributed file system architecture is the reduction of the CPU overhead on the I/O data path.
We have created an implementation of DAFS for the FreeBSD platform. In this paper we describe the performance evaluation study of DAFS that we have performed using this software. The goal of this study is to determine whether the architecture of DAFS brings any fundamental performance benefits to applications compared to traditional distributed file systems, such as NFS. We perform comparison of DAFS to a version of NFS optimized to reduce the I/O overhead. In order to thoroughly understand the impact of DAFS on application performance, we consider a diverse range of applications workloads.
We conclude that DAFS can accomplish superior performance for latency-sensitive applications, outperforming NFS by up to a factor of 2. Bandwidth-sensitive applications do equally well on both systems, unless they are CPU-intensive, in which case they perform better on DAFS. We also found that RDMA is a less restrictive mechanism to achieve copy avoidance than that used by the optimized NFS.
PDF
Fedorova, A., Seltzer, M., Magoutis, K., Addetia, S.
Proceedings of Workshop on Software and Performance 2004 (WOSP’04), January 2004, Redwood City, CA.
file systems, networking
2003
New NFS Tracing Tools and Techniques for System Analysis
Abstract
Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF
PostScript
Ellard, D., Seltzer, M.
Proceedings of the 17th Annual Large Installation System Administration Conference (LISA’03), October 2003, San Diego, CA, pp 73-85.
file systems, tools
NFS Tricks and Benchmarking Traps
Abstract
We describe two modifications to the FreeBSD 4.6 NFS server to increase read throughput by improving the read-ahead heuristic to deal with reordered requests and stride access patterns. We show that for some stride access patterns, our new heuristics improve end-to-end NFS throughput by nearly a factor of two. We also show that benchmarking and experimenting with changes to an NFS server can be a subtle and challenging task, and that it is often difficult to distinguish the impact of a new algorithm or heuristic from the quirks of the underlying software and hardware with which they interact. We discuss these quirks and their potential effects.
PDF
PostScript
Slides (PDF)
Ellard, D., Seltzer, M.
Proceedings of the 2003 FREENIX Technical Conference, June 2003, San Antonio, TX, pp 101-114.
file systems
Passive NFS Tracing of Email and Research Workloads
Abstract
We present an analysis of a pair of NFS traces of contemporary email and research workloads. We show that although the research workload resembles previously-studied workloads, the email workload is quite different. We also perform several new analyses that demonstrate the periodic nature of file system activity, the effect of out-of-order NFS calls, and the strong relationship between the name of a file and its size, lifetime, and access
PDF
PostScript
Slides (PDF)
Ellard, D., Ledlie, J., Malkani, P., Seltzer, M
Proceedings of the Second Symposium on File and Storage Technologies, March 2003, San Francisco, CA, pp 203-216.
file systems, tools
Making the Most Out of Direct-Access Network Attached Storage
Abstract
The performance of high-speed network-attached storage applications is often limited by end-system overhead, caused primarily by memory copying and network protocol processing. In this paper, we examine alternative strategies for reducing overhead in such systems. We consider optimizations to remote procedure call (RPC)-based data transfer using either remote direct memory access (RDMA) or network interface support for pre-posting of application receive buffers. We demonstrate that both mechanisms enable file access throughput that saturates a 2Gb/s network link when performing large I/Os on relatively slow, commodity PCs. However, for multi-client workloads dominated by small I/Os, throughput is limited by the per-I/O overhead of processing RPCs in the server. For such workloads, we propose the use of a new network I/O mechanism, Optimistic RDMA (ORDMA). ORDMA is an alternative to RPC that aims to improve server throughput and response time for small I/Os. We measured performance improvements of up to 32% in server throughput and 36% in response time with use of ORDMA in our prototype.
PDF
Magoutis, K, Fedorova, A., Addetia, S., Seltzer, M.
Proceedings of the Second Symposium on File and Storage Technologies, March 2003, San Francisco, CA.
file systems, networking
Scooped Again
Abstract
The Peer-to-Peer (p2p) and Grid infrastructure communities are tackling an overlapping set of problems. In addressing these problems, p2p solutions are usually motivated by elegance or research interest. Grid researchers, under pressure from thousands of scientists with real file sharing and computational needs, are pooling their solutions from a wide range of sources in an attempt to meet user demand. Driven by this need to solve large scientific problems quickly, the Grid is being constructed with the tools at hand: FTP or RPC for data transfer, centralization for scheduling and authentication, and an assumption of correct, obediant nodes. If history is any guide, the World Wide Web depicts viscerally that systems that address user needs can have enormous staying power and affect future research. The Grid infrastructure is a great customer waiting for future p2p products. By no means should we make them our only customers, but we should at least put them on the list. If p2p research does not at least address the Grid, it may eventually be sidelined by defacto distributed algorithms that are less elegant but were used to solve Grid problems. In essense, well have been scooped, again.
PDF
PostScript
Ledlie, J., Shneidman, J., Seltzer, M., Huth, J.
Proceedings of the Second International Workshop on Peer-to-Peer Systems (IPTPS-03), Berkeley, CA, February 2003.
networking, p2p
2002
Building a Reliable Mutable File System on Peer-to-peer Storage
Abstract
This paper sketches the design of the Eliot File System (Eliot), a mutable filesystem that maintains the pure im- mutability of its peer-to-peer (P2P) substrate by isolating mutation in an auxiliary metadata service.
The immutability of address-to-content bindings has several advantages in P2P systems. However, mutable filesystems are desirable because they allow clients to update existing files; a necessary property for many applications. In order to facilitate modifications, the filesystem must provide some atom of mutability. Since this atom of mutability is a fundamental characteristic of the filesystem and not the underlying storage substrate, it is a mistake to violate the integrity of the substrate with special cases for mutability. Instead, Eliot employs a separate, generalized metadata service that isolates all mutation and client state in an auxiliary replicated database. Eliot provides fine-granularity file updates with either AFS open/close or NFS-like consistency semantics. Eliot builds a mutable filesystem on a global resource bed of purely immutable P2P block storage.
PDF
PostScript
Stein, C., Tucker, M., Seltzer, M.
Proceedings of the International Workshop on Reliable Peer-to-peer Distributed Systems, Osaka, Japan, October 2002.
file systems, p2p
Self-Organization in Peer-to-Peer Systems
Abstract
This paper addresses the problem of forming groups in peer-to-peer (P2P) systems and examines what dependability means in decentralized distributed systems. Much of the literature in this field assumes that the participants form a local picture of global state, yet little research has been done discussing how this state remains stable as nodes enter and leave the system. We assume that nodes remain in the system long enough to benefit from retaining state, but not sufficiently long that the dynamic nature of the problem can be ignored. We look at the components that describe a system's dependability and argue that next-generation decentralized systems must explicitly delineate the information dispersal mechanisms (e.g., probe, event-driven, broadcast), the capabilities assumed about constituent nodes (bandwidth, uptime, re-entry distributions), and distribution of information demands (needles in a haystack vs. hay in a haystack). We evaluate two systems based on these criteria: Chord and a heterogeneous-node hierarchical grouping scheme. The former gives a greater than 1 failed request rate under normal P2P conditions and a prototype of the latter a similar rate under more strenuous conditions with an order of magnitude more organizational messages. This analysis suggests several methods to greatly improve the prototype.
PDF
PostScript
Ledlie, J., Taylor, J., Serban, L., Seltzer, M.
Proceedings of the 10th ACM SIGOPS European Workshop, Saint-Emilion, France, September 2002.
networking, p2p
Structure and Performance of the Direct Access File System
Abstract
The Direct Access File System (DAFS) is an emerging industrial standard for network-attached storage. DAFS takes advantage of new user-level network interface standards. This enables a user-level file system structure in which client-side functionality for remote data access resides in a library rather than in the kernel. This structure addresses longstanding performance problems stemming from weak integration of buffering layers in the network transport, kernel-based file systems and applications. The benefits of this architecture include lightweight, portable and asynchronous access to network storage and improved application control over data movement, caching and prefetching.
This paper explores the fundamental performance characteristics of a user-level file system structure based on DAFS. It presents experimental results from an open-source DAFS prototype and compares its performance to a kernel-based NFS implementation optimized for zero-copy data transfer. The results show that both systems can deliver file access throughput in excess of 100 MB/s, saturating network links with similar raw bandwidth. Lower client overhead in the DAFS configuration can improve application performance by up to 40% over optimized NFS when application processing and I/O demands are well-balanced.
PDF
Magoutis, K., Addetia, S., Fedorova, A., Seltzer, M., Chase, J., Gallatin, D., Kisley, R., Wickremesinghe, R., Gabber, E.
Proceedings of the 2002 USENIX Technical Conference, June 2002, Monterey, CA, 1–14.
file systems, networking
On the Design of a New CPU Architecture for Pedagogical Purposes
Abstract
Ant-32 is a new processor architecture designed specifically to address the pedagogical needs of teaching many subjects, including assembly language programming, machine architecture, compilers, operating systems, and VLSI design. This paper discusses our motivation for creating Ant-32 and the philosophy we used to guide our design decisions and gives a high level decsription of the resulting design.
PDF
PostScript
Ellard, D., Holland, D., Murphy, N, Seltzer, M.
Proceedings of the Workshop on Computer Architecture Education, May, 2002, Anchorage, Alaska.
architecture, education
A New Instructional Operating System
Abstract
his paper presents a new instructional operating system, OS/161, and simulated execution environment, System/161, for use in teaching an introductory undergraduate operating systems course. We describe the new system, the assignments used in our course, and our experience teaching using the new system.
PDF
PostScript
Holland, D., Lim, A., and Seltzer, M.
Proceedings of the 2002 SIGCSE Conference, February 2002, Covington, KY, 111–115.
operating systems, education
2001
Unifying File System Protection
(PDF)
Stein, C., Howard, J., Seltzer, M.
Proceedings of the 2001 USENIX Technical Conference, June 2001, Boston, MA, 79–90.
file systems, security
Research Issues in No-Futz Computing
Abstract
At the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), the attendees reached consensus that the most important issue facing the OS research community was "No-Futz" computing; eliminating the ongoing "futzing" that characterizes most systems today. To date, little research has been accomplished in this area. Our goal in writing this paper is to focus the research community on the challenges we face if we are to design systems that are truly futz-free, or even low-futz.
PDF
PostScript
Holland, D., Josephson, W., Magoutis, K., Seltzer, M., Stein, C.
Proceedings of the 2001 Workshop on Hot Topics in Operating Systems (HotOS VII), Elmau Germany, May 2001.
operating systems
HBench:JGC - An Application-Specific Benchmark Suite for Evaluating JVM Garbage Collector Performance
Abstract
As Java becomes a viable platform for server applications, performance becomes a greater concern. An important aspect of Java Virtual Machine performance is its dynamic memory management system (garbage collection or GC). Traditional GC benchmarking often focuses on a set of fixed applications. As a result, when an actual application's memory behavior differs from that of the standard benchmarks, the benchmark results do not help the user judge which GC implementation suits her application the best. In this paper, we present HBench:JGC, an application-specific benchmarking suite, based on the idea that a system's performance be measured in the context of a specific application. HBench:JGC employs a methodology that characterizes the application memory usage and the GC implementation independently and carefully combines both characterizations to form a single metric that reflects a particular application's performance in the presence of a particular GC implementation. We evaluate our approach on Sun Microsystems's JDK1.2.2 classic JVM with a sequential mark-sweep GC. Our results demonstrate HBench:JGC's unique predictive power and its ability to provide meaningful metrics that lead to a better understanding of GC performance.
PDF
Zhang, X., Seltzer, M.
Proceedings of the 6th USENIX Conference on Object-Oriented Technology (COOTS 2001), February 2001, San Antonio, TX.
benchmarking
2000
Journaling versus Soft Updates: Asynchronous Meta-data Protection in File Systems
Abstract
The UNIX Fast File System (FFS) is probably the most widely-used file system for performance comparisons. However, such comparisons frequently overlook many of the performance enhancements that have been added over the past decade. In this paper, we explore the two most commonly used approaches for improving the performance of meta-data operations and recovery: journaling and Soft Updates. Journaling systems use an auxiliary log to record meta-data operations and Soft Updates uses ordered writes to ensure meta-data consistency.
The commercial sector has moved en masse to journaling file systems, as evidenced by their presence on nearly every server platform available today: Solaris, AIX, Digital UNIX, HP-UX, Irix, and Windows NT. On all but Solaris, the default file system uses journaling. In the meantime, Soft Updates holds the promise of providing stronger reliability guarantees than journaling, with faster recovery and superior performance in certain boundary cases.
HTML
PDF
PostScript
Slides (PDF)
Slides (PostScript)
Seltzer, M., Ganger, G., McKusick, M., Smith, K., Soules, C., Stein, C.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 71–84.
file systems
Isolation with Flexibility: A Resource Management Framework for Central Servers
Abstract
Proportional-share resource management is becoming increasingly important in today's computing environments. In particular, the growing use of the computational resources of central service providers argues for a proportional-share approach that allows resource principals to obtain allocations that reflect their relative importance. In such environments, resource principals must be isolated from one another to prevent the activities of one principal from impinging on the resource rights of others. However, such isolation limits the flexibility with which resource allocations can be modified to reflect the actual needs of applications. We present extensions to the lottery-scheduling resource management framework that increase its flexibility while preserving its ability to provide secure isolation. To demonstrate how this extended framework safely overcomes the limits imposed by existing proportional-share schemes, we have implemented a prototype system that uses the framework to manage CPU time, physical memory, and disk bandwidth. We present the results of experiments that evaluate the prototype, and we show that our framework has the potential to enable server applications to achieve significant gains in performance.
Addendum
As discussed in our 2000 USENIX paper, lottery scheduling's currency abstraction imposes lower limits on the resource allocations that clients of a system can receive. In our USENIX paper, we proposed one method for overcoming these lower limits. In this addendum to the paper, we discuss a limitation of our original solution to the lower-limits problem, and we propose an alternate solution that overcomes the shortcomings of the original solution.
PDF
PostScript
Slides (PDF)
Addendum (PDF)
Sullivan., D., Seltzer, M.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 337–-350.
os, scheduling
Operating System Support for Multi-User, Remote Graphical Interaction
Abstract
The emergence of thin client computing and multi-user, remote, graphical interaction revives a range of operating system research issues long dormant, and introduces new directions as well. This paper investigates the effect of operating system design and implementation on the performance of thin client service and interactive applications. We contend that the key performance metric for this type of system and its applications is user-perceived latency and we give a structured approach for investigating operating system design with this criterion in mind. In particular, we apply our approach to a quantitative comparison and analysis of Windows NT, Terminal Server Edition (TSE), and Linux with the X Windows System, two popular implementations of thin client service.
We find that the processor and memory scheduling algorithms in both operating systems are not tuned for thin client service. Under heavy CPU and memory load, we observed user-perceived latencies up to 100 times beyond the threshold of human perception. Even in the idle state, these systems induce unnecessary latency. TSE performs particularly poorly despite scheduler modifications to improve interactive responsiveness. We also show that TSE's network protocol outperforms X by up to six times, and also makes use of a bitmap cache which is essential for handling dynamic elements of modern user interfaces and can reduce network load in these cases by up to 2000%.
PDF
Wong., A., Seltzer, M.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 183–196.
operating systems, networking
Improving Interactive System Performance Using TIPME
Abstract
On the vast majority of today's computers, the dominant form of computation is GUI-based user interaction. In such an environment, the user's perception is the final arbiter of performance. Human-factors research shows that a user's perception of performance is affected by unexpectedly long delays. However, most performance-tuning techniques currently rely on throughput-sensitive benchmarks. While these techniques improve the average performance of the system, they do little to detect or eliminate response-time variabilities--in particular, unexpectedly long delays.
We introduce a measurement infrastructure that allows us to improve user-perceived performance by helping us to identify and eliminate the causes of the unexpected long response times that users find unacceptable. We describe TIPME (The Interactive Performance Monitoring Environment), a collection of measurement tools that allowed us to quickly and easily diagnose interactive performance "bugs" in a mature operating system. We present two case studies that demonstrate the effectiveness of our measurement infrastructure. Each of the performance problems we identify drastically affects variability in response time in a mature system, demonstrating that current tuning techniques do not address this class of performance problems.
PDF
PostScript
Endo, Y., Seltzer, M.
Proceedings of the 2000 ACM Sigmetrics Conference, June 2000, Santa Clara, CA.
benchmarking
HBench:Java: An Application-Specific Benchmark for JVMs
Abstract
Java applications represent a broad class of programs, ranging from programs running on embedded products to high-performance server applications. Standard Java benchmarks ignore this fact and assume a fixed workload. When an actual application's behavior differs from that included in a standard benchmark, the benchmark results are useless, if not misleading. In this paper, we present HBench:Java, an application-specific benchmarking framework, based on the concept that a system's performance must be measured in the context of the application of interest. HBench:Java employs a methodology that uses vectors to characterize the application and the underlying JVM and carefully combines the two vectors to form a single metric that reflects a specific application's performance on a particular JVM such that the performance of multiple JVMs can be realistically compared. Our performance results demonstrate HBench:Java's superiority over traditional benchmarking approaches in predicting real application performance and its ability to pinpoint performance problems.
PDF
Zhang, X., Seltzer, M.
Proceedings of the ACM 2000 Java Grande Conference, June 2000, San Francisco, CA.
benchmarking
1999
Evaluating Windows NT Terminal Server Performance
Abstract
With the introduction of Windows NT, Terminal Server Edition (TSE), Microsoft finally brings to Windows the ``thin-client'' computing model the X Window System has offered Unix for a decade. TSE's two most salient features are the provision of multi-user login service and the provision of that service remotely, over a network link. These features distinguish TSE from previous Microsoft operating systems not only by functionality, but also by how its performance ought to be measured. Because TSE's primary service is interactive, user-perceived latency is more important than ever. In this paper, we examine the resource consumption and latency characteristics of shared usage on a TSE system. We find that the introduction of remote, multi-user access has added to the minimal level of resource consumption, that the efficiency of TSE's RDP protocol is generally good but degrades on dynamic user interface elements, and that TSE can exhibit poor latency performance when subjected to high processor, memory, and network load.
PDF
PostScript
Wong, A., Seltzer, M.
Proceedings of the 3rd USENIX Windows NT Symposium, July, 1999, Seattle, WA, 145–154.
benchmarking, ui
HACC: An Architecture for Cluster-Based Web Server
Abstract
This paper presents the design, implementation, and performance of the Harvard Array of Clustered Computers (HACC), a cluster-based design for scalable, cost-effective web servers. HACC is designed for locality enhancement. Requests that arrive at the cluster are distributed among the nodes so as to enhance the locality of reference that occurs on individual nodes in the cluster. By improving locality on individual cluster nodes, we can reduce their working set sizes and achieve superior performance for less cost than conventional approaches. We implemented HACC on Windows NT 4.0 and evaluated its performance for both static documents and workloads of dynamically generated documents adapted from logs of commercial web servers. Our performance results show that HACC's locality enhancement can improve performance by up to 121% for our stochastically generated static file case, by up to 40% for our trace-based static file case, and by up to 52% for our trace-based dynamic document case, compared to an IP-Sprayer approach to building cluster-based web servers.
PDF
Zhang, X., Barrientos, M., Chen, J., Seltzer, M.
Proceedings of the 3rd USENIX Windows NT Symposium, July, 1999, Seattle, WA, 155–164.
storage, p2p
Berkeley DB
Abstract
Berkeley DB is an Open Source embedded database system with a number of key advantages over comparable systems. It is simple to use, supports concurrent access by multiple users, and provides industrial-strength transaction support, including surviving system and disk crashes. This paper describes the design and technical features of Berkeley DB, the distribution, and its license.
PDF
Olson, M., Bostic, K., Seltzer, M.
Proceedings of the 1999 FREENIX Conference, June, 1999, Monterey, CA.
databases, kvstore
Tickets and Currencies Revisted: Extensions to Multi-Resource Lottery Scheduling
Abstract
Lottery scheduling's ticket and currency abstractions provide a resource management framework that allows for both flexible allocation and insulation between groups of processes. We propose extensions to this framework that enable greater flexibility while preserving the ability to isolate groups of processes. In particular, we present a mechanism that allows processes to modify their own resource rights by exchanging resource-specific tickets with other processes. Ticket exchanges limit the effects of the changed allocations to the participants in the exchange, and they allow applications to coordinate with each other in ways that are mutually beneficial. Application-specific "negotiators" can be used to initiate exchanges based on an application's quality-of-service requirements and the current state of the system. We also propose flexible access controls for currencies through extensible "brokers" that solve such problems as the inability of users isolated by currencies to renice background jobs. Finally, we suggest using extensibility to allow users to install specialized allocation mechanisms for their processes. Together, these extensions enable an application-centered approach to resource management that is both secure and effective.
HTML
PDF
PostScript
Slides (PostScript)
Sullivan, D., Haas, R., Seltzer, M.
Proceedings of the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), March, 1999, Rio Rico, AZ.
os, scheduling
The Case for Application-Specific Benchmarking
Abstract
Most performance analysis today uses either microbenchmarks or standard macrobenchmarks (e.g., SPEC, LADDIS, the Andrew benchmark). However, the results of such benchmarks provide little information to indicate how well a particular system will handle a particular application. Such results are, at best, useless and, at worst, misleading. In this paper, we argue for an application-directed approach to benchmarking, using performance metrics that reflect the expected behavior of a particular application across a range of hardware or software platforms. We present three different approaches to application-specific measurement, one using vectors that characterize both the underlying system and an application, one using trace-driven techniques, and a hybrid approach. We argue that such techniques should become the new standard.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Seltzer, M., Krinsky, D., Smith, K., Zhang, X.
Proceedings of the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), March, 1999, Rio Rico, AZ.
benchmarking
Challenges in Embedded Database System Administration
Abstract
Database configuration and maintenance have historically been complex tasks, often requiring expert knowledge of database design and application behavior. In an embedded environment, it is not feasible to require such expertise and ongoing database maintenance. This paper discusses the database administration challenges posed by embedded systems and describes how the Berkeley DB architecture addresses these challenges.
HTML
Seltzer, M., Olson, M.
Proceedings of the 1999 USENIX Workshop on Embedded Systems, Cambridge, MA, March 1999.
databases
The ANT Architecture — An Architecture for CS1
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncracies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts. Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF
PostScript
Ellard, D. J., Ellard, P. A., Megquier, J. M., Chen, J. B., Seltzer, M. I.
The IEEE Computer Society Technical Committee on Computer Architecture Newsletter, February, 1999, 25–27.
architecture, education
1998
MiSFIT: Constructing Safe Extensible Systems
Abstract
The boundary between application and system is becoming increasingly permeable. Extensible applications, such as web browsers, database systems, and operating systems, demonstrate the value of allowing end-users to extend and modify the behavior of what was formerly considered to be a static, inviolate system. Unfortunately, flexibility often comes with a cost: systems unprotected from misbehaved end-user extensions are fragile and prone to instability.
Object-oriented programming models are a good fit for the development of this kind of system. An extension can be designed as a refinement to an existing class and loaded into a running system. In our model, when code is downloaded into the system, it is used to replace a virtual function on an existing C++ object. Because our tool is source-language-neutral, it can be used to build safe, extensible systems written in other languages as well.
There are three methods commonly used to make end-user extensions safe: restrict the extension language (e.g., Java), interpret the extension language (e.g., Tcl), or combine run-time checks with a trusted environment. The third technique is the one discussed here; it offers the twin benefits of the flexibility to implement extensions in an unsafe language, such as C++, and the performance of compiled code.
MiSFIT, the Minimal i386 Software Fault Isolation Tool, can be used as a component of a tool set for building safe extensible systems in C++. MiSFIT transforms C++ code, compiled by the Gnu C++ compiler, into safe binary code. Combined with a runtime support library, the overhead of MiSFIT is an order of magnitude lower than the overhead of interpreted Java, and permits safe extensible systems to be written in C++.
PDF
Small, C., Seltzer, M.
IEEE Concurrency, (6), 3, July–Sep 1998, 34–41.
operating systems, tools, pl
The Mug Shot Search
Abstract
Mug-shot search is the classic example of the general problem of searching a large facial image database when starting out with only a mental image of the sought-after face. We have implemented a prototype content-based image retrieval system that integrates composite face creation methods with a face-recognition technique (Eigenfaces) so that a user can both create faces and search for them automatically in a database.
Although the Eigenface method has been studied extensively for its ability to perform face identification tasks (in which the input to the system is an on-line facial image to identify), little research has been done to determine how effective it is when applied to the mug shot search problem (in which there is no on-line input image at the outset, and in which the task is similarity retrieval rather than face-recognition). With our prototype system, we have conducted a pilot user study that examines the usefulness of Eigenfaces applied to this problem. The study shows that the Eigenface method, though helpful, is an imperfect model of human perception of similarity between faces. Using a novel evaluation methodology, we have made progress at identifying specific search strategies that, given an imperfect correlation between the system and human similarity metrics, use whatever correlation does exist to the best advantage. The study also indicates that the use of facial composites as query images is advantageous compared to restricting users to database images for their queries.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Slides (PDF)
Baker, E., Seltzer, M.
Proceedings of the 1998 Vision Interfaces Conference, Vancouver, Canada, June 1998, 421–430.
algorithms, ui
The ANT Architecture — An Architecture for CS1
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncrasies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts.
PDF
PostScript
Ellard, D., Ellard, Pl, Megquier, J., Chen, JB, Seltzer, M.
Proceedings of the Workshop on Computer Architecture Education, 1998.
architecture, education
1997
Web Facts and Fantasy
Abstract
There is a great deal of research about improving Web server performance and building better, faster servers, but little research in characterizing servers and the load imposed upon them. While some tremendously popular and busy sites, such as netscape.com, playboy.com, and altavista.com, receive several million hits per day, most servers are never subjected to loads of this magnitude. This paper presents the analysis of internet Web server logs for a variety of different types of sites. We present a taxonomy of the different types of Web sites and characterize their access patterns and, more importantly, their growth. We then use our server logs to address some common perceptions about the Web. We show that, on a variety of sites, contrary to popular belief, the use of CGI does not appear to be increasing and that long latencies are not necessarily due to server loading. We then show that, as expected, persistent connections are generally useful, but that dynamic time-out intervals may be unnecessarily complex and that allowing multiple persistent connections per client may actually hinder resource utilization compared to allowing only a single persistent connection.
HTML
PDF
PostScript
Manley, S., Seltzer, M.
Proceedings of the Symposium on Internet Technologies and Systems, Monterey, CA, December 1997, 125-134.
networking, web
Measuring Windows NT — Possibilities and Limitations
Abstract
The majority of today's computing takes place on interactive systems that use a Graphical User Interface (GUI). Performance of these systems is unique in that "good performance" is a reflection of a user's perception. In this paper, we explain why this unique environment requires a new methodological aproach. We describe a measurement/diagnostic tool currently under development and evaluate the feasibility of implementing such a tool under Windows NT. We then present several issues that must be resolved in order for Windows NT to become a popular research platform for this type of work.
PDF
Endo, Y., Seltzer M.
Proceedings of the First USENIX Workshop on NT, Seattle, WA, August 1997.
benchmarking, operating systems
Operating System Benchmarking in the Wake of Lmbench: Case Study of the Performance of NetBSD on the Intel Architecture
Abstract
The lmbench suite of operating system microbenchmarks provides a set of portable programs for use in cross-platform comparisons. We have augmented the lmbench suite to increase its flexibility and precision, and to improve its methodological and statistical operation. This enables the detailed study of interactions between the operating system and the hardware architecture. We describe modifications to lmbench, and then use our new benchmark suite, hbench:OS, to examine how the performance of operating system primitives under NetBSD has scaled with the processor evolution of the Intel x86 architecture. Our analysis shows that off-chip memory system design continues to influence operating system performance in a significant way and that key design decisions (such as suboptimal choices of DRAM and cache technology, and memory-bus and cache coherency protocols) can essentially nullify the performance benefits of the aggressive execution core and sophisticated on-chip memory system of a modern processor such as the Intel Pentium Pro.
HTML
PDF
PostScript
Additional documentation
Brown, A., Seltzer, M.
Proceedings of the 1997 Sigmetrics Conference, Seattle, WA, June 1997, 214-224.
benchmarking, os
File System Aging
Abstract
Benchmarks are important because they provide a means for users and researchers to characterize how their workloads will perform on different systems and different system architectures. The field of file system design is no different from other areas of research in this regard, and a variety of file system benchmarks are in use, representing a wide range of the different user workloads that may be run on a file system. A realistic benchmark, however, is only one of the tools that is required in order to understand how a file system design will perform in the real world. The benchmark must also be executed on a realistic file system. While the simplest approach maybe to measure the performance of an empty file system, this represents a state that is seldom encountered by real users. In order to study file systems in more representative conditions, we present a methodology for aging a test file system by replaying a workload similar to that experienced by a real file system over a period of many months, or even years. Our aging tools allow the same aging workload to be applied to multiple versions of the same file system, allowing scientific evaluation of the relative merits of competing file system designs.
In addition to describing our aging tools, we demonstrate their use by applying them to evaluate two enhancements to the file layout policies of the UNIX fast file system.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Slides (PDF)
Smith, K., Seltzer, M.
Proceedings of the 1997 Sigmetrics Conference, Seattle, WA, June 1997, 203-213.
file systems
Self-Monitoring and Self-Adapting Operating Systems
Abstract
Extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. Extensibility enables a system to efficiently support a broader class of applications than is currently supported. This paper discusses the key challenge in making extensible systems practical: determining which parts of the system need to be extended and how. The determination of which parts of the system need to be extended requires self-monitoring, capturing a significant quantity of data about the performance of the system. Determining how to extend the system requires self-adaptation. In this paper, we describe how an extensible operating system (VINO) can use in situ simulation to explore the efficacy of policy changes. This automatic exploration is applicable to other extensible operating systems and can make these systems self-adapting to workload demands.
PDF
Slides (PDF)
Seltzer, M., Small, C.
Proceedings of the 1997 Workshop on Hot Operating Systems, Cape Cod, MA, May 5-6, 1997, 124-129.
operating systems
1996
Dealing with Disaster: Surviving Misbehaving Kernel Extensions
Abstract
Today's extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. The advantage of this approach is that it provides improved application flexibility and performance; the disadvantage is that buggy or malicious code can jeopardize the integrity of the kernel. It has been demonstrated that it is feasible to use safe languages, software fault isolation, or virtual memory protection to safeguard the main kernel. However, such protection mechanisms do not address the full range of problems, such as resource hoarding, that can arise when application code is introduced into the kernel.
In this paper, we present an analysis of extension mechanisms in the VINO kernel. VINO uses software fault isolation as its safety mechanism and a lightweight transaction system to cope with resource-hoarding. We explain how these two mechanisms are sufficient to protect against a large class of errant or malicious extensions, and we quantify the overhead that this protection introduces.
We find that while the overhead of these techniques is high relative to the cost of the extensions themselves, it is low relative to the benefits that extensibility brings.
HTML
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M., Endo, Y., Small, C., Smith, K.
Proceedings of the Second Symposium on Operating System Design and Implementation, Seattle, WA, October 1996, 213-227.
operating systems
Understanding Latency in GUI-based Applications
Endo, Y., Wang, Z., Chen, B., Seltzer, M.
Proceedings of the Second Symposium on Operating System Design and Implementation, Seattle, WA, October 1996, 195-199.
benchmarking, ui
Symbiotic System Software: Fast Operating Systems for Fast Applications
(PDF)
Seltzer., M., Small, C., Smith, M.
Proceedings of the First Workshop on Compiler Support for System Software, Tuscon, AZ, Feb 1996.
operating systems
World-Wide Web Cache Consistency
Abstract
The bandwidth demands of the World Wide Web continue to grow at a hyper-exponential rate. Given this rocketing growth, caching of web objects as a means to reduce network bandwidth consumption is likely to be a necessity in the very near future. Unfortunately, many Web caches do not satisfactorily maintain cache consistency. This paper presents a survey of contemporary cache consistency mechanisms in use on the Internet today and examines recent research in Web cache consistency. Using trace-driven simulation, we show that a weak cache consistency protocol (the one used in the Alex ftp cache) reduces network bandwidth consumption and server load more than either time-to-live fields or an invalidation protocol and can be tuned to return stale data less than 5% of the time.
PDF
PostScript
Gwertzman, J., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 141-152.
caching, web
Comparison of OS Extension Technologies
Abstract
The current trend in operating systems research is to allow applications to dynamically extend the kernel to improve application performance or extend functionality, but the most effective approach to extensibility remains unclear. Some systems use safe languages to permit code to be downloaded directly into the kernel; other systems provide in-kernel interpreters to execute extension code; still others use software techniques to ensure the safety of kernel extensions. The key characteristics that distinguish these systems are the philosophy behind extensibility and the technology used to implement extensibility. This paper presents a taxonomy of the types of extensions that might be desirable in an extensible operating system, evaluates the performance cost of various extension techniques currently being employed, and compares the cost of adding a kernel extension to the benefit of having the extension in the kernel. Our results show that compiled technologies (e.g. Modula-3 and software fault isolation) are good candidates for implementing general-purpose kernel extensions, but that the overhead of interpreted languages is sufficiently high that they are inappropriate for this use.
PDF
PostScript
Small, C., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 41-54.
operating systems, transactions
A Comparison of FFS Disk Allocation Policies
Abstract
The 4.4BSD file system includes a new algorithm for allocating disk blocks to files. The goal of this algorithm is to improve file clustering, increasing the amount of sequential I/O when reading or writing files, thereby improving file system performance. In this paper we study the effectiveness of this algorithm at reducing file system fragmentation. We have created a program that artificially ages a file system by replaying a workload similar to that experienced by a real file system. We used this program to evaluate the effectiveness of the new disk allocation algorithm by replaying ten months of activity on two file systems that differed only in the disk allocation algorithms that they used. At the end of the ten month simulation, the file system using the new allocation algorithm had approximately half the fragmentation of a similarly aged file system that used the traditional disk allocation algorithm. Measuring the performance difference between the two file systems by reading and writing the same set of files on the two systems showed that this decrease in fragmentation improved file write throughput by 20% and read throughput by 32%. In certain test cases, the new allocation algorithm provided a performance improvement of greater than 50%.
PDF
Supplementary Materials
Smith, K., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 15-26.
file systems
The Measured Performance of Personal Computer Operating Systems
Abstract
This paper presents a comparative study of the performance of three operating systems that run on the personal computer architecture derived from the IBM-PC. The operating systems, Windows for Workgroups (tm), Windows NT (tm), and NetBSD (a freely available UNIX (tm) variant) cover a broad range of system functionality and user requirements, from a single address space model to full protection with preemptive multi-tasking. Our measurements were enabled by hardware counters in Intel's Pentium (tm) processor that permit measurement of a broad range of processor events including instruction counts and on-chip cache miss counts. We used both microbenchmarks, which expose specific differences between the systems, and application workloads, which provide an indication of expected end-to-end performance. Our microbenchmark results show that accessing system functionality is often more expensive in Windows than in the other two systems due to frequent changes in machine mode and the use of system call hooks. When running native applications, Windows NT is more efficient than Windows, but it incurs overhead similar to that of a microkernel since its application interface(the Win32 API) is implemented as a user-level server. Overall, system functionality can be accessed most efficiently in NetBSD; we attribute this to its monolithic structure, and to the absence of the complications created by backwards compatibility in the other systems. Measurements of application performance show that although the impact of these differences is significant in terms of instruction counts and other hardware events (often a factor of 2 to 7 difference between the systems), overall performance is sometimes determined by the functionality provided by specific subsystems, such as the graphics subsystem or the file system buffer cache.
PDF
PostScript
Supplementary Materials
Transactions on Computer Systems version (PostScript)
Chen, B., Endo, Y., Chan, K., Mazieres, D., Dias, A., Seltzer, M., Smith, M.
Proceedings of the 15th ACM Symposium on Operating Systems Principles, Copper Mountain, Colorado, December 3-6, 1995. Also in ACM Transactions on Computer Systems, January 1996, 3-40.
benchmarking, operating systems
1995
Structuring the Kernel as a Toolkit of Extensible, Reusable Components
Abstract
Applications often require functionality that is implemented in the kernel, but is not directly available to the user level. While extensible operating systems allow kernel functionality to be augmented, we believe that the emphasis on extensibility is misplaced. Applications should be able to reuse kernel code directly and the emphasis should be placed on designing a kernel with that reuse in mind. The advantage of structuring the kernel as a set of reusable, extensible tools is that applications can avoid re-implementing functionality that is already present in the kernel. This will lead to smaller applications, fewer lines of total code, and a more unified computing environment that will be easier to maintain and perform better.
PDF
PostScript
Small, C., Seltzer, M.
Proceedings of the International Workshop on Object Orientation in Operating Systems, Lund, Sweden, August 1995, 134-137.
operating systems
The Case for Geographical Push-Caching
Abstract
Most existing wide-area caching schemes are client initiated. Decisions on when and where to cache information are made without the benefit of the server's global knowledge of the situation. We believe that the server should play a role in making these caching decisions, and we propose geographical push-caching as a way of bringing the server back into the loop. The World Wide Web is an excellent example of a wide-area system that will benefit from geographical push-caching, and we present an architecture that allows a Web server to autonomously replicate HTML pages.
PDF
PostScript
Gwertzman, J., Seltzer., M.
Proceedings of the Fifth Annual Workshop on Hot Operating Systems, Orcas Island, WA, May 1995, 51-55.
caching, web
File System Logging versus Clustering: A Performance Comparison
Abstract
The Log-structured File System (LFS), introduced in 1991, has received much attention for its potential order-of-magnitude improvement in file system performance. Early research results showed that small file performance could scale with processor speed and that cleaning costs could be kept low, allowing LFS to write at an effective bandwidth of 62 to 83% of the maximum. Later work showed that the presence of synchronous disk operations could degrade performance by as much as 62% and that cleaning overhead could become prohibitive in transaction processing workloads, reducing performance by as much as 40%. The same work showed that the addition of clustered reads and writes in the Berkeley Fast File System (FFS) made it competitive with LFS in large-file handling and software development environments as approximated by the Andrew benchmark.
These seemingly inconsistent results have caused confusion in the file system research community. This paper presents a detailed performance comparison of the 4.4BSD Log-structured File system and the 4.4BSD Fast File System. Ignoring cleaner overhead, our results show that the order-of-magnitude improvement in performance claimed for LFS applies only to meta-data intensive activities, specifically the creation of files one-kilobyte or less and deletion of files 64 kilobytes or less.
For small files, both systems provide comparable read performance, but LFS offers superior performance on writes. For large files (one megabyte and larger), the performance of the two file systems is comparable. When FFS is tuned for writing, its large-file write performance is approximately 15% better than LFS, but its write performance is 25% worse. When FFS is optimized for reading, its large-file read and write performance is comparable to LFS.
Both LFS and FFS can suffer performance degradation, due to cleaning and disk fragmentation respectively. We find that active FFS file systems function at approximately 85-95% of their maximum performance after two to three years. We examine LFS cleaner performance in a transaction-processing environment and find that cleaner overhead reduces LFS performance by more than 33% when the disk is 50% full.
PDF
PostScript
Supplementary Materials
Seltzer, M., Smith, K., Balakrishnan, H., Chang, J., McMains, S., Padmanabhan, V.
Proceedings of the 1995 Winter USENIX Technical Conference, New Orleans, LA, January 1995, 249-264.
file systems, benchmarking
Heuristic Cleaning Algorithms for Log-Structured File Systems
Abstract
Research results show that while Log-Structured File Systems (LFS) offer the potential for dramatically improved file system performance, the cleaner can seriously degrade performance, by as much as 40% in transaction processing workloads. Our goal is to examine trace data from live file systems and use those to derive simple heuristics that will permit the cleaner to run without interfering with normal file access. Our results show that trivial heuristics perform very well, allowing 97% of all cleaning on the most heavily loaded system we studied to be done in the background.
PDF
PostScript
Blackwell, T., Harris., J., Seltzer, M.
Proceedings of the 1995 Winter USENIX Technical Conference, New Orleans, LA, January 1995, 277-288.
algorithms, file systems
1994
An Experimental Flow Controlled Multicast ATM Switch
(PDF)
Blackwell, T., Chan, K., Chang, K., Charuhas, T., Karp, B., Kung, H. T., Lin, D., Morris, R., Seltzer, M., Smith, M., Young, C., Bahgat, O., Chaar, M., Chapman, A., Depelteau, G., Grimble, K., Huang, S., Hung, P., Kemp, M., McLaughlin, I., Ng, T., Vincent, J., and Watchor, J.
Proceedings of the First Annual Conference on Telecommunications Research and Development in Massachusetts, Vol. 6, October 1994, 33-38.
networking
Evolving Line Drawings
Abstract
This paper explores the application of interactive genetic algorithms to the creation of line drawings. We have built a system that mates or mutates drawings selected by the user to create a new generation of drawings. The initial population from which the user makes selections may be generated randomly or input manually. The process of selection and procreation is repeated many times to evolve a drawing. A wide variety of complex sketches with highlighting and shading can be evolved from very simple drawings. This technique has potential for augmenting and enhancing the power of traditional computer-aided drawing tools, and for expanding the repertoire of the computer-assisted artist.
HTML
PDF
PostScript
Slides (HTML)
Slides (PDF)
Baker, E., Seltzer, M.
Proceedings of Graphics Interface ’94, Banff, Canada, May 1994, 91-100.
visualization, algorithms
1993
Transaction Support in a Log-Structured File System
Abstract
Transaction Support in a Log-Structured File System
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M.
Proceedings of the Ninth International Conference on Data Engineering, Vienna, Austria, April 1993, 503-510.
file systems, transactions
An Implementation of a Log-Structured File System for UNIX
Abstract
Research results demonstrate that a log-structured file system offers the potential for dramatically improved write performance, faster recovery time, and faster file creation and deletion than traditional UNIX file systems. This paper presents a redesign and implementation of the Sprite log-structured file system that is more robust and integrated into the vnode interface. Measurements show its performance to be superior to the 4BSD Fast File System in a variety of benchmarks and not significantly less than FFS in any test. Unfortunately, an enhanced version of FFS (with read and write clustering) provides comparable and sometimes superior performance to our LFS. However, LFS can be extended to provide additional functionality such as embedded transactions and versioning, not easily implemented in traditional file systems.
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M., Bostic, K., McKusick., M., Staelin, C.
Proceedings of the 1993 Winter USENIX Conference, San Diego, CA January 1993, 307-326.
file systems
1992
File System Performance and Transaction Support
(PDF)
Seltzer, M.,
Ph.D. Dissertation, University of California, Berkeley, December 1992.
file system, transaction support, read-optimized, write-optimized, log-structured file system
Non-Volatile Memory for Fast, Reliable File Systems
Abstract
Given the decreasing cost of non-volatile RAM (NVRAM), by the late 1990's it will be feasible for most workstations to include a megabyte or more of NVRAM, enabling the design of higher-performance, more reliable systems. We present the trace-driven simulation and analysis of two uses of NVRAM to improve I/O performance in distributed file systems: non-volatile file caches on client workstations to reduce write traffic to file servers, and write buffers for write-optimized file systems to reduce server disk accesses. Our results show that a megabyte of NVRAM on diskless clients reduces the amount of file data written to the server by 40 to 50%. Increasing the amount of NVRAM shows rapidly diminishing returns, and the particular NVRAM block replacement policy makes little difference to write traffic. Closely integrating the NVRAM with the volatile cache provides the best total traffic reduction. At today's prices, volatile memory provides a better performance improvement per dollar than NVRAM for client caching, but as volatile cache sizes increase and NVRAM becomes cheaper, NVRAM will become cost effective. On the server side, providing a one-half megabyte write-buffer per file system reduces disk accesses by about 20% on most of the measured log-structured file systems (LFS), and by 90% on one heavily-used file system that includes transaction-processing workloads.
PDF
PostScript
Baker, M., Asami, S., Deprit, E., Ousterhout, J., Seltzer, M.
Proceedings of ASPLOS-V, Boston, MA, October 1992, 10-22.
file systems, nvm
LIBTP: Portable, Modular Transactions for UNIX
Abstract
Transactions provide a useful programming paradigm for maintaining logical consistency, arbitrating concurrent access, and managing recovery. In traditional UNIX systems, the only easy way of using transactions is to purchase a database system. Such systems are often slow, costly, and may not provide the exact functionality desired. This paper presents the design, implementation, and performance of LIBTP, a simple, non-proprietary transaction library using the 4.4BSD database access routines (db(3)). On a conventional transaction processing style benchmark, its performance is approximately 85% that of the database access routines without transaction protection, 200% of that using fsync(2) to commit modifications to disk, and 125% that of a commercial relational database system.
PDF
PostScript
Seltzer, M., Olson, M.
Proceedings 1992 Winter USENIX Conference, San Francisco, CA, January 1992, 9-26.
databases, transactions
1991
Read Optimized File Systems: A Performance Evaluation
Abstract
This paper presents a performance comparison of several file system allocation policies. The file systems are designed to provide high bandwidth between disks and main memory by taking advantage of parallelism in an underlying disk array, cateringv to large units of transfer, and minimizing the bandwidth dedicated to the transfer of meta data. All of the file systems described use a multiblock allocation strategy that allows both large and small files to be allocated efficiently. Simulation results show that these multiblock policies result in systems that are able to utilize a large percentage of the underlying disk bandwidth; more than 90% in sequential cases. As general purpose systems are called upon to support more data intensive applications such as databases and supercomputing, these policies offer an opportunity to provide superior performance to a larger class of users.
PDF
PostScript
Seltzer, M., Stonebraker, M.
Proceedings 7th Annual International Conference on Data Engineering, Kobe, Japan, April 1991, 602-611.
file systems, benchmarking
A New Hashing Package for UNIX
Abstract
UNIX support of disk oriented hashing was originally provided by dbm [ATI79] and subsequently improved upon in ndbm [BSD86]. In AT&T System V, in-memory hashed storage and access support was added in the hsearch library routines [ATT85]. The result is a system with two incompatible hashing schemes, each with its own set of shortcomings. This paper presents the design and performance characteristics of a new hashing package providing a superset of the functionality provided by dbm and hsearch. The new package uses linear hashing to provide efficient support of both memory based and disk based hash tables with performance superior to both dbm and hsearch under most conditions.
PDF
PostScript
Seltzer, M., Yigit, O.
Proceedings 1991 Winter USENIX Conference, Dallas, TX, January 1991, 173-184.
algorithms, data structures
1990
Transaction Support in Read Optimized and Write Optimized File Systems
Abstract
This paper provides a comparative analysis of five implementations of transaction support. The first of the methods is the traditional approach of implementing transaction processing within a data manager on top of a read optimized file system. The second also assumes a traditional file system but embeds transaction support inside the file system. The third model considers a traditional data manager on top of a write optimized file system. The last two models both embed transaction support inside a write optimized file system, each using a different logging mechanism. Our results show that in a transaction processing environment, a write optimized file system often yields better performance than one optimized for reads. In addition, we show that file system embedded transaction managers can perform as well as data managers when transaction throughput is limited by I/O bandwidth. Finally, even when the CPU is the critical resource, the difference in performance between a data manager and an embedded system is much smaller than previous work has shown.
PDF
PostScript
Seltzer, M., Stonebraker, M.
Proceedings 16th International Conference on Very Large Data Bases, Brisbane, Australia, August 1990, 174-185.
file systems, transactions
Disk Scheduling Revisited
Abstract
Since the invention of the movable head disk, people have improved I/O performance by intelligent scheduling of disk accesses. We have applied these techniques to systems with large memories and potentially long disk queues. By viewing the entire buffer cache as a write buffer, we can improve disk bandwidth utilization by applying some traditional disk scheduling techniques. We have analyzed these techniques, which attempt to optimize head movement and guarantee fairness in response time, in the presence of long disk queues. We then propose two algorithms which take rotational latency into account, achieving disk bandwidth utilizations of nearly four times a simple first come first serve algorithm. One of these two algorithms, a weighted shortest total time first, is particularly applicable to a file server environment because it guarantees that all requests get to disk within a specified time window.
PDF
PostScript
Seltzer, M., Chen, P., Ousterhout, J.
Proceedings 1990 Winter USENIX Conference, Washington, D.C., January 1990, 313-324.
storage
Velosiraptor: Code Synthesis for Memory Translation (arXiv)
Achermann, R., Chu, E., Mehri, R., Karimalis, I., Seltzer, M.
Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '25)
virtual memory, automatic programming, software engineering, program synthesis
CUTTANA: Scalable Graph Partitioning for Faster Distributed Graph Databases and Analytics (PDF)
Rezaei, M., Sridhar, S., Seltzer, M.,
Proceedings of the Very Large Database Endowment (PVLDB)
graph partitioning, graphs
2024
Interpretable Generalized Additive Models for Datasets with Missing Values (PDF)
McTavish, H., Donnelly, J., Seltzer, M., Rudin, C.
2024 Conference on Neural Information Processing (NeurIPS 2024)
Interpretable Machine Learning, GAMS, Missing Data, machine learning
HyperBrain: Anomaly Detection for Temporal Hypergraph Brain Networks (PDF)
Sadeghian, S., Li, X., Seltzer, M
Proceedings of the Workshop on Machine Learning in Clinical Neuroimaging (MLCN 2024; Co-located with MICCAI 2024)
hypergraph, temporal graph, temporal hypergraph, fMRI, GNN, graph learning, machine learning
Parallel Assembly Synthesis (PDF)
Hu, J., Chong, S., Seltzer, M.,
Proceedings of the 34th International Symposium on Logic-Based Program Synthesis and Transformation (LOPSTR 2024; Co-located with PPDP as part of Formal Methods 2024)
program synthesis, assembly synthesis, parallelization
NetShaper: A Differentially Private Network Side-Channel Mitigation System (Arxiv)
Sabzi, A., Vora, R., Goswami, S., Seltzer, M., Lecuyer, M., Mehta, A.,
USENIX Security Symposium (USENIX Security 2024)
side channel, differential privacy, network side channel
Amazing Things Come from Having Many Good Models (Arxiv)
Rudin, C., Zhong, C., Semenova, L., Seltzer, M., Parr, R., Liu, J., Katta, S., Donnelly, J., Chen, H., Boner, Z.,
International Conference on Machine Learning (ICML 2024)
Rashomon set, GAMs, decision trees, scoring systems, machine learning
Enabling Application-Aware Memory Page Replacement Policies and Mechanisms with ExtMem (PDF)
Jalalian, S., Patel, S., Hajidehi, M., Seltzer, M., Fedorova, S.,
Proceedings of the USENIX Annual Technical Conference (ATC-2024)
prefetching, swap, semikernel
Computational Experiment Comprehension using Provenance Summarization (PDF)
Boufford, M., Wonsil, M., Pocock, A., Sullivan, J., Seltzer, M., Pasquier, T.,
Proceedings of the ACM Conference on Reproducibility (REP 2024)
provenance, reproducibility, LLM, provenance summarization
RABIT: A Robot Arm Bug Intervention Tool for Self-Driving Labs (PDF)
Wattoo, Z., Gujarati, A., Seltzer, M.,
Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks
self-driving lab, intrusion detection, anomaly detection
Optimal Sparse Survival Trees (arXiv) Selected for spotlight presentation.
Zhang, R., Xin, R., A., Seltzer, M., Rudin, C.,
Artificial Intelligence and Statistics (AISTATS 2024)
interpretable machine learning, interpretable ML, ML, survival trees, optimal trees, machine learning
2023
Exploring and Interacting with the Set of Good Sparse Generalized Additive Models (Arxiv)
Zhong, C., Chen, Z., Liu, J., Seltzer, M., Rudin, C.,
37th Conference on Neural Information Processing (NeurIPS 2023)
Rashomon set, GAMs, sparse models, generalized additive models, machine learning
CAT-Walk: Inductive Hypergraph Learning via Set Walks (Arxiv)
Behrouz, A., Hashemi, F., Sadeghian, S., Seltzer, M.,
37th Conference on Neural Information Processing (NeurIPS 2023)
machine learning, hypergraphs, edge prediction, node prediction
CHERI-picking: Leveraging capability hardware for prefetching (PDF)
Patel, S., Agrawal, S., Fedorova, A., Seltzer, M.,
Programming Languages and Operating Systems Workshop (PLOS '23)
Prefetching, capabilities, CHERI
Synthesizing Device Drivers with Ghost Writer (PDF)
Wang, B., Noorafshan, S., Achermann, R., Seltzer, M.,
Programming Languages and Operating Systems Workshop (PLOS '23)
Device drivers, program synthesis, behavior trees
Anomaly Detection in the Human Brain via Inductive Learning on Temporal Multiplex Networks (PDF)
Behrouz, A., Seltzer, M.
Proceedings of Machine Learning Research 219:1-31 (Presented at the 2023 Machine Learning for Healthcare Conference (MLHC), August 2023
graph neural networks, anomaly detection, machine learning, healthcare
ADMIRE++: Explainable Anomaly Detection in the Human Brain via Inductive Learning on Temporal Multiplex Networks (PDF) Best Paper
Behrouz, A., Seltzer, M.
International Machine Learning in Healthcare Workshop (w/ICML), July 2023
explainable AI, machine learning, healthcare, anomaly detection
Integrated Reproducibility with Self-describing Machine Learning Models (PDF)
Wonsil J., Sullivan, J., Seltzer, M., Pocock, A.
Proceedings of the First ACM Conference on Reproducibility, June 2023
reproducibility, provenance, java, machine learning, Tribuo
Reproducibility as a Service (PDF)
Wonsil, J., Boufford, N., Agrawal, P., Chen, C., Cui, T., Sivaram, A., Seltzer, M.
Software: Practice and Experience, 2023.
provenance, reproducibility, data science
Why write code when you can synthesize address translations? (PDF)
Achermann, R., Karimalis, I., Seltzer, M.
Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS), May 2023
program synthesis, memory translation
Making Provenance Work for You (PDF)
Lerner, B., Boose, E., Brand, O., Ellison, A., Fong, E., Lau, M., Ngo, K., Pasquier, T., Perez, L., Seltzer, M., Sheehan, M., Wonsil, J.
The R Journal (2023)
Provenance, R, RDT, Reproducibility
Optimal Sparse Regression Trees (arXiv)
Zhang, R., Xin, R., Seltzer, M., Rudin, C.
Proceedings of the 37th Conference on Artifical Intelligence (AAAI)
Interpretable ML, Sparse Models, Regression Trees, machine learning
2022
Anomaly Detection in Multiplex Dynamic Networks: from Blockchain Security to Brain Disease Prediction, (PDF) Selected for spotlight presentation.
Behrouz, A., Seltzer, M.,
Thirty-sixth Conference on Neural Information Processing Systems, (NeurIPS 2022)
graph learning, anomaly detection, intrusion detection, machine learning
Fast Optimization of Weighted Sparse Decision Trees for use in Optimal Treatment Regimes and Optimal Policy Design (arXiv)
Behrouz, A., Lecuyer, M., Rudin, C., Seltzer, M.,
Advances in Interpretable Machine Learning and Artificial Intelligence (AIMLAI 2022)
Optimal Sparse Decision Trees, Interpretable Machine Learning, Optimal Treatment Regimes, machine learning
FasterRisk: Fast and Accurate Interpretable Risk Scores (arXiv)
Liu, J., Zhong, C., Li, B., Seltzer, M., Rudin, C.,
Thirty-sixth Conference on Neural Information Processing Systems, (NeurIPS 2022)
Risk Scores, Interpretable Machine Learning, machine learning
Exploring the Whole Rashomon Set of Sparse Decision Trees (arXiv) Selected for Oral Presentation
Xin, R, Zhong, C., Chen Z., Takagi, R., Seltzer, M., Rudin, C.,
Thirty-sixth Conference on Neural Information Processing Systems, (NeurIPS 2022)
Optimal Sparse Decision Trees, Rashomon Set, machine learning
Shellac: a compiler synthesizer for concurrent programs (PDF)
Chen, C., Seltzer, M., Greenstreet, M.,
Conference on Verified Software: Theories, Tools, and Experiments (VSTTE), 2022
program synthesis, compilation, arduino C++, verilog, UNITY
TimberTrek: Exploring and Curating Sparse Decision Trees with Interactive Visualization (website)
Wang, Z., Zhong, C., Xin, R., Takagi, T., Chen, Z., Chau, D., Rudin, C., Seltzer, M.,
IEEE Visualization Conference (VIS), 2022.
optimal sparse decision trees, machine learning, interpretable AI, visualization
Towards Porting Operating Systems with Program Synthesis (PDF).
Hu, J., Lu, E., Holland, D., Kawaguchi, M., Chong, S., Seltzer, M.,
ACM Transactions on Programming Languages and Systems (TOPLAS), September 2022.
program synthesis,operating systems
Tinkertoy: Build your own operating systems for IoT devices (PDF) Best Paper
Wang, B., Seltzer, M.,
ACM SIGBED International Conference on Embedded Software (EMSOFT 2022)
IoT, Operating System, Design and Implementation
Arming IDS Researchers with a Robotic Arm Dataset (PDF) (teaser) (video) (dataset)
Guarati, A., Wattoo, Z., Aliabadi, M., Clark, S., Liu, X., Shiri, P., Trivedi, A., Zhu, R., Hein, J., Seltzer, M.,
The 52nd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2022), June 2022.
robotic arms, intrusion detection, dataset
Fast Sparse Classification for Generalized Linear and Additive Models (PDF) (video) (poster)
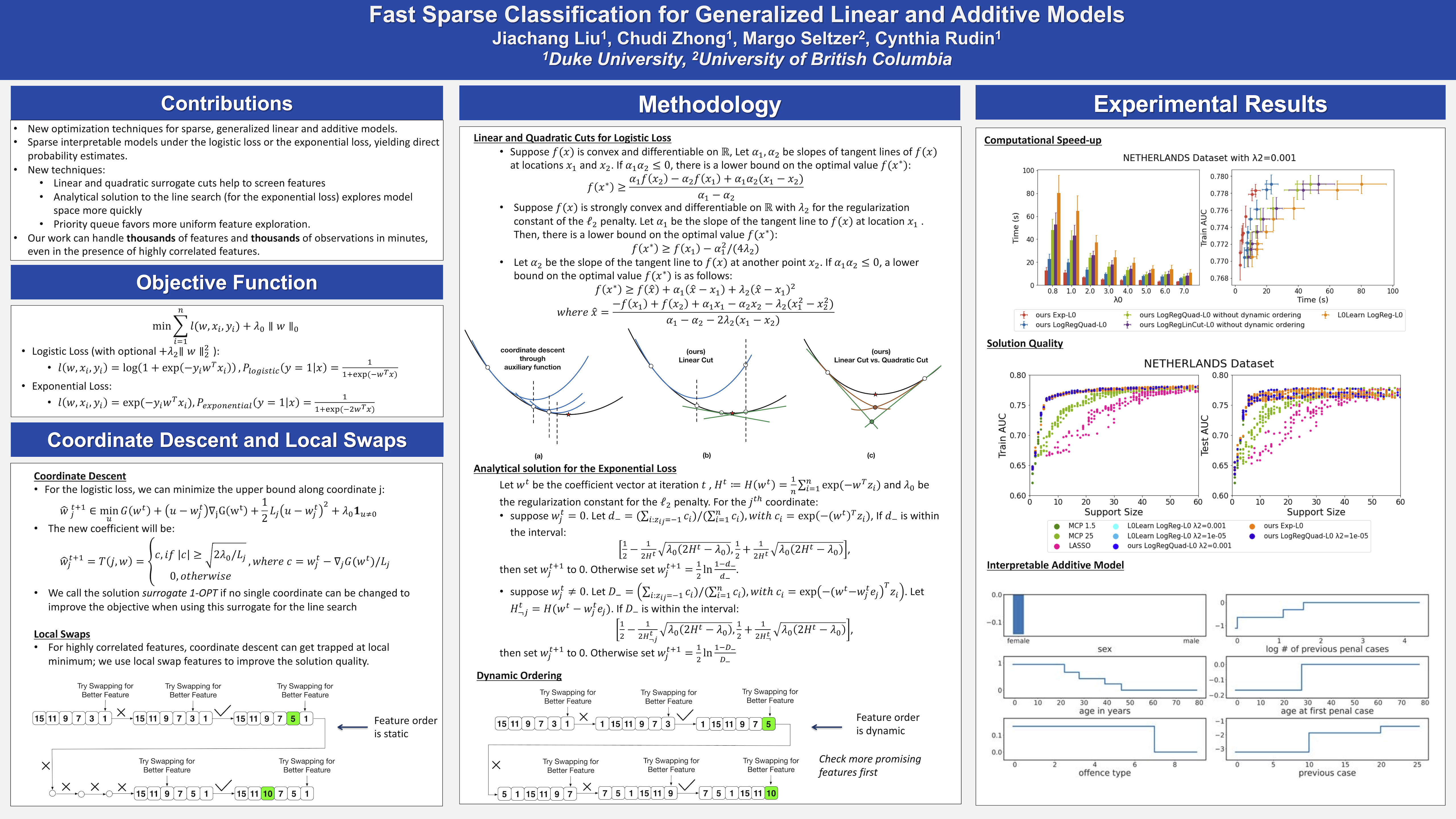{kind=link}
Liu, J., Zhong, C., Seltzer, M., Rudin, C.
The 25th International Conference on Artificial Intelligence and Statistics
linear models, sparse models, classification, additive models, machine learning
Fast Sparse Decision Tree Optimization via Reference Ensembles (PDF) (video teaser) (full talk)
McTavish, H., Zhong, C., Achermann, R., Karimalis, I., Chen, J., Rudin, C., Seltzer, M.
Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22)
interpretable machine learning, optimization, decision trees, machine learning
2021
Assuage: Assembly Synthesis Using A Guided Exploration (PDF)
Hu, J., Vaithilingam, P., Chong, S., Seltzer, M., Glassman, E.
User-Interfaces Systems and Technology(UIST 2021)
program synthesis, interactive synthesis, assembly programming
ARTINALI#: An Efficient Intrusion Detection Technique for Resource-Constrained Cyber-Physical systems (PDF)
Aliabadi, M., Seltzer, M., Asl, M., Ghavamizadeh, R.
International Journal of Critical Infrastructure Protection
intrusion detection, cyber-physical systems
SIGL: Securing Software Installations Through Deep Graph Learning (PDF) (video)
Han, X., Yu, X., Pasquier, T., Li, D., Rhee, J., Mickens, J., Seltzer, M., Haifent, C.
Proceedings of the USENIX Security Symposium, August 2021.
malware, software installation, provenance
2020
Parking Packet Payload with P4 (PDF)
Goswami, S., Kodirov, N., Mustard, C., Beschastnikh, I., Seltzer, M.
Proceedings of the International Conference on emerging Networking and Experiments and Technologies (CoNEXT)
P4, smart switches, network functions, NF
Generalized and Scalable Optimal Sparse Decision Trees (PDF)
Lin, J., Zhong, C., Hu, D., Rudin, C., Seltzer, M.,
Proceedings of the International Conference on Machine Learning (ICML 2020)
optimization, decision trees, dynamic programming, branch and bound, machine learning
Unexpected Performance of Intel® OptaneTM DC Persistent Memory (PDF)
Mason, T., Doudali, T., Seltzer, M., Gavrilovska, A.,
IEEE Computer Architecture Letters, 19(1), January-June 2020.
NVM, persistent memory, optane, performance
Xanthus: Push-button Orchestration of Host Provenance Data Collection
(PDF)
Han, X., Mickens, J., Gehani, A., Seltzer, M., Pasquier, T.,
Proceedings of the Third Annual Workshop on Practical Reproducible
Evaluation of Computer Systems (Co-located with HPDC 2020)
provenance, reproducibility, unicorn, intrustion detection, machine learning
Smooth Kronecker: Solving the Combing Problems in Kronecker Graphs
(PDF)
Anand, V., Mehrotra, P., Margo, D., Seltzer, M.,
Proceedings of the Joint Workshop on Graph Data Management Experiences
and Systems (GRADES) and Network Data Analytics (NDA) (Co-located with
SIGMOD 2020)
graph generator, kroneckor, benchmarking, graph
People of Data: The End-to-End Provenance Project
(PDF)
Ellison, A., Boose, E., Lerner, B., Fong, E., Seltzer, M.,
Patterns
R, provenance, data provenance, data science
Rclean: A Tool for Writing Cleaner, More Transparent Code
(PDF)
Lau, M., Pasquier T., Seltzer, M.,
JOSS: The Journal of Open Source Software
R, provenance, data provenance, data science, statistical analysis
A user-centered, learning asthma smartphone application for patients and
providers
(PDF)
Gaynor, M., Schneider, D., Seltzer, M., Crannage, E., Barron, M.,
Waterman, J., Oberle, A.,
Learning Health Systems
user-centered design, health, asthma, health app
Unicorn: Runtime Provenance-Based Detector for Advanced Persistent Threats
(PDF)
Han, X., Pasquier, T., Bates, A., Mickens, J., Seltzer, M.,
Network and Distributed System Security
Symposium (NDSS)
provenance, intrusion detection, CamFlow, machine learning
Improving Data Scientist Efficiency with Provenance
(PDF)
Hu, J., Joung, J., Jacobs, M., Gajos, K., Seltzer, M.,
International Conference on Software Engineering
provenance, data science, noWorkflow, incremental execution
2019
Optimal Sparse Decision Trees
(PDF)
Hu, X., Rudin, C., Seltzer, M.,
Conference on Neural Information Processing Systems (NeurIPS)
decision trees, interpretable machine learning, machine learning
ProvMark: A provenance expressiveness benchmarking system
(PDF)
Chan, S., Cheney, J., Bhatotia, P., Pasquier, T.,
Gehani, A., Irshad, H., Carata, L., Seltzer, M.,
International Middleware Conference
provenance, benchmarking, CamFlow
Trials and Tribulations in Synthesizing Operating Systems
(PDF)
Hu, J., Lu, E., Holland, D., Kawaguchi, M., Chong, S., Seltzer, M.,
Workshop on Programing Languages and Operating Systems (co-located with SOSP)
program synthesis, operating systems
Visonpaper -- From Here to Provtopia
(PDF)
Pasquier, T., Eyers, D., Seltzer, M.,
Towards Polystores that manage multiple Databases, Privacy, Security and/or Policy Issues for Heterogenous Data (POLY, co-located with VLDB 2019)</h5
provenance, compliance, GDPR
2018
Incentivizing Deep Fixes in Software Economies
(PDF)
Rao, M., Bacon, D.F., Parkes, D., Seltzer, M.
IEEE Transactions on Software Engineering. (June 2018, 21 pages) doi: 10.1109/TSE.2018.2842188
software engineering, bug fixing, econCS
Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using CrossReferencing Logs
(PDF)
Huang, Y., Pavlovic, M., Marathe, V., Seltzer, M., Harris, T., Byan, S.
Proceedings of the 2018 USENIX Annual Technical Conference, Boston MA, June 2018.
key value store, NVM, logging, logs
Sharing and Preserving Computational Analyses for Posterity with encapsulator
(PDF)
Pasquier, T., Lau, M., Han, X., Fong, E., Lerner, B., Boose, E., Crosas, M., Ellison, A., Seltzer, M.
IEEE Computing in Science and Engineering 20(111), July 2018. doi: or,” IEEE Computing in Science and Engineering 20(111), July 2018. doi: 10
provenance, reproducibility
Provenance-based Intrusion Detection: Opportunities
and Challenges
(PDF)
Han, X., Pasquier, T., Seltzer, M.
Proceedings of the Workshop on the Theory and Practice of Provenance (TaPP 2018), London UK, July 2018
provenance, intrusion detection, machine learning
Runtime Analysis of Whole-System Provenance
(PDF)
Pasquier, T., Han, X., Moyer, T., Bates, A., Hermant, O., Eyers, D., Bacon, J., Seltzer, M.
Proceedings of the 2018 Conference on Computer and Communications Security
(CCS '18), Toronto CA, October 2018.
camflow, provenance, data integrity
Learning Certifiably Optimal Rule Lists for Categorical Data
(PDF)
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M., Rudin, C.
Journal of Machine Learning Research 18 (2018) 1-78.
optimization, rule lists, machine learning, data structures
2017
Practical Whole-System Provenance Capture
(PDF)
Pasquier, T., Han, X., Goldstein, M., Moyer, T., Eyers, D., Seltzer, M., and Bacon, J., 2017.
Proceedings of SoCC ’17, Santa Clara, CA, USA, September 24–27, 2017.
provenance, camflow, os
Learning Certifiably Optimal Rule Lists
(PDF)
(video)
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M., Rudin, C.
Proceedings of the 23rd ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining (KDD), August 2017, 35-44.
optimization, rule lists, machine learning, data structures
If these data could talk
(PDF)
Pasquier, T., Lau, M., Trisovic, A., Boose, E., Couturier, B., Crosas, M., Ellison, A., Gibson, V., Jones, C., and Seltzer, M.
Nature Scientific Data, vol. 4, 2017.
provenance, reproducibility
Data Provenance to Audit Compliance with Privacy Policy
(PDF)
Pasquier, T., Singh, J., Powles, J., Eyers, D., Seltzer, M., Bacon, J.
Internet of Things, Journal of Personal and Ubiquitous Computing, published online Aug. 15, 2017.
provenance, privacy, compliance
Scalable Bayesian Rule Lists
(PDF)
Yang, H., Rudin, C., Seltzer, M.
Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, PMLR 70, 2017.
algorithms, rule lists, machine learning, mcmc
FRAPpuccino: Fault-detection through Runtime Analysis of Provenance
(PDF)
Han, X., Pasquier, T., Ranjan, T., Goldstein, M., and Seltzer, M.
Proceedings of the Workshop on Hot Topics in Cloud Computing (HotCloud’17), USENIX Association, Santa Clara, CA, July 2017.
provenance, fault detection, intrusion detection, security
Persistent Memcached: Bringing Legacy Code to Byte-Addressable Persistent Memory
(PDF)
Marathe, V., Seltzer, M., Byan, S., Harris, T.
Proceedings of USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 17) USENIX Association, Santa Clara, CA, July 2017.
persistent memory, nvm, storage, kvstore
A Crowdsourcing Approach to Collecting Tutorial Videos — Toward Personalized Learning-at-Scale
(PDF)
Whitehill, J., Seltzer, M.
Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale (L@S)
education
Sorting Shapes the Performance of Graph-Structured Systems
(PDF)
Daniel Wyatt Margo
Ph.D. Dissertation, Harvard John A. Paulson School of Engineering and Applied Sciences, March 27, 2017.
graphs, partitioning, performance, kronecker
2015
Towards General-Purpose Neural Network Computing
(PDF)
Eldridge, S., Appavoo, J., Joshi, A., Waterland, A., Seltzer, M.
Proceedings of the 13th International Conference on Parallel
Architectures and Compilation Techniques (PACT 2015), Petrozavodsk Russia, September 2015.
ASC, automatically scalable computing, neural networks
Recent advances in computer architecture: the opportunities and challenges for provenance.
(PDF)
Balakrishnan, Nikilesh, Thomas Bytheway, Lucian Carata, Oliver RA Chick, James Snee, Sherif Akoush, Ripduman Sohan, Margo Seltzer, and Andy Hopper
7th USENIX Workshop on the Theory and Practice of Provenance (TaPP 15). 2015.
provenance, architecture
A Scalable Distributed Graph Partitioner
(PDF)
Margo, D., Seltzer, M
Proceedings of the 41st International Conference on Very Large Data Bases, Kohala Coast, Hawaii, August 2015, pp 1478-1489.
graphs, algorithms
LLAMA: Efficient Graph Analytics Using Large Multiversioned Arrays
(PDF)
Macko, P., Margo, D., Marathe, V., Seltzer, M.
Proceedings of the 31st IEEE International Conference on Data Engineering (ICDE 2015), Seoul Korea, April 2015.
graphs, algorithms, data structures, storage
2014
Accelerating MCMC via parallel predictive prefetching
(PDF)
Angelino, E., Kohler, E., Waterland, A., Seltzer, M., Adams, M.
Proceedings of the 2014 Conference on Uncertainty in Artificial Intelligence (UAI '14), Quebec City, Quebec Canada, July 2014.
algorithms, mcmc, asc
Proceedings of the AAAI 2014 Workshop on Incentives and Trust in E-Communities (WIT-EC'14)
(PDF)
Rao, M., Parkes, D., Seltzer, M., and Bacon, D.
Quebec City, Quebec Canada, July 2014.
incentives, econcs
Programmable Smart Machines: A Hybrid Neuromorphic approach to General Purpose Computation
(PDF)
Appavoo, J., Waterland, A., Eldridge, S., Zhao, K,. Joshi, A, Homer, S, Seltzer, M.
Proceedings of the first workshop on Neuromorphic Architectures
(NeuroArch) collocated with ISCA, June 2014.
ASC, automatically scalable computation, neuromorphic
A Primer on Provenance
(PDF)
Carata, L, Akoush, S., Balakrishnan, N., Bytheway, T., Sohan, R., Seltzer, M., Hopper, A.
ACM Queue 12(3), April 2014.
provenance
ASC: Automatically Scalable Computation
(PDF)
Waterland, A., Angelino, E., Adams, R., Appavoo, J., Seltzer, M.
Proceedings of the 2014 Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '14) (IEEE Top Pick), Salt Lake City Utah, March 2014.
ASC, automatically scalable computation, architecture, machine learning, parallelization, dynamical system
2013
Applying KISS to Healthcare Information Technology
(PDF)
Herzlinger, R., Seltzer, M., Gaynor, M.
Computer 46(11), IEEE, November 2013, 72--74.
healthcare technology
Evaluation of Filesystem Provenance Visualization Tools
Borkin, M., Yeh, C., Boyd, M., Macko, P., Gajos, K., Seltzer, M., Pfister, H.
Proceedings of the 2013 International Conference on Information Visualization (Vis 2013), Atlanta GA, October 2013.
provenance, visualization
Local Clustering in Provenance Graphs
(PDF)
Macko, P., Margo, D., Seltzer, M.
Proceedings of the 2013 International Conference on Information and Knowledge Management (CIKM 2013), Burlingame CA, October 2013.
provenance, algorithms, metrics
Performance Introspection of Graph Databases
Abstract
The explosion of graph data in social and biological networks, recommendation systems, provenance databases, etc. makes graph storage and processing of paramount importance. We present a performance introspection framework for graph databases, PIG, which provides both a toolset and methodology for understanding graph database performance. PIG consists of a hierarchical collection of benchmarks that compose to produce performance models; the models provide a way to illuminate the strengths and weaknesses of a particular implementation. The suite has three layers of benchmarks: primitive operations, composite access patterns, and graph algorithms. While the framework could be used to compare different graph database systems, its primary goal is to help explain the observed performance of a particular system. Such introspection allows one to evaluate the degree to which systems exploit their knowledge of graph access patterns. We present both the PIG methodology and infrastructure and then demonstrate its efficacy by analyzing the popular Neo4j and DEX graph databases.
PDF
Slides (PDF)
Macko, P., Margo, D., Seltzer, M.
Proceedings of the 2013 SYSTOR Conference, Haifa Israel, July 2013.
graphs, benchmarking
Computational Caches
Abstract
Caching is a well-known technique for speeding up computation. We cache data from file systems and databases; we cache dynamically generated code blocks; we cache page translations in TLBs. We propose to cache the act of computation, so that we can apply it later and in different contexts. We use a state-space model of computation to support such caching, involving two interrelated parts: speculatively memoized predicted/resultant state pairs that we use to accelerate sequential computation, and trained probabilistic models that we use to generate predicted states from which to speculatively execute. The key techniques that make this approach feasible are designing probabilistic models that automatically focus on regions of program execution state space in which prediction is tractable and identifying state space equivalence classes so that predictions need not be exact.
PDF
Slides (PDF)
Waterland, A., Angelino, E., Cubuk, E., Kaziras, E., Adams, R., Appavoo, J., Seltzer, M.
Proceedings of the 2013 SYSTOR Conference, Haifa Israel, July 2013.
asc, caching
Flash Caching on the Storage Client
Abstract
Flash memory has recently become popular as a caching medium. Most uses to date are on the storage server side. We investigate a different structure: flash as a cache on the client side of a networked storage environment. We use trace-driven simulation to explore the design space. We consider a wide range of configurations and policies to determine the potential client-side caches might offer and how best to arrange them.
Our results show that the flash cache writeback policy does not significantly affect performance. Write-through is sufficient; this greatly simplifies cache consistency handling. We also find that the chief benefit of the flash cache is its size, not its persistence. Cache persistence of- fers additional performance benefits at system restart at essentially no runtime cost. Finally, for some workloads a large flash cache allows using miniscule amounts of RAM for file caching (e.g., 256 KB) leaving more mem- ory available for application use.
PDF
Slides (PDF)
Holland, D., Angelino, E., Wald, G., Seltzer, M.
Proceedings of the 2013 USENIX Annual Technical Conference, San Jose, CA, June 2013.
caching, storage, nvm
2012
2011
A General-Purpose Provenance Library
Abstract
Most provenance capture takes place inside particular tools – a workflow engine, a database, an operating system, or an application. However, most users have an existing toolset – a collection of different tools that work well for their needs and with which they are comfortable. Currently, such users have limited ability to collect provenance without disrupting their work and changing environments, which most users are hesitant to do. Even users who are willing to adopt new tools, may realize limited benefit from provenance in those tools if they do not integrate with their entire environment, which may include multiple languages and frameworks.
We present the Core Provenance Library (CPL), a portable, multi-lingual library that application programmers can easily incorporate into a variety of tools to collect and integrate provenance. Although the manual instrumentation adds extra work for application programmers, we show that in most cases, the work is minimal, and the resulting system solves several problems that plague more constrained provenance collection systems.
PDF
Slides (PDF)
Macko, P., Seltzer, M.
Proceedings of the Fourth Workshop on the Theory and Practice of Provenance (TaPP 2012), Boston MA, June 2012.
provenance, software
Provenance Integration Requires Reconciliation
Abstract
While there has been a great deal of research on provenance systems, there has been little discussion about challenges that arise when making different provenance systems interoperate. In fact, most of the literature focuses on provenance systems in isolation and does not discuss interoperability – what it means, its requirements, and how to achieve it. We designed the Provenance-Aware Storage System to be a general- purpose substrate on top of which it would be “easy” to add other provenance-aware systems in a way that would provide “seamless integration” for the provenance captured at each level. While the system did exactly what we wanted on toy problems, when we began integrating StarFlow, a Python-based workflow/provenance system, we discovered that integration is far trickier and more subtle than anyone has suggested in the literature. This work describes our experience undertaking the integration of StarFlow and PASS, identifying several important additions to existing provenance models necessary for interoperability among provenance systems.
PDF
Slides (PDF)
Angelino, E., Braun, U., Holland, D., Macko, P., Margo, D., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance
Provenance Map Orbiter: Interactive Exploration of Large Provenance Graphs
Abstract
Provenance systems can produce enormous provenance graphs that can be used for a variety of tasks from deter- mining the inputs to a particular process to debugging entire workflow executions or tracking difficult-to-find dependencies. Visualization can be a useful tool to sup- port such tasks, but graphs of such scale (thousands to millions of nodes) are notoriously difficult to visualize. This paper presents the Provenance Map Orbiter, a tool for interactively exploring large provenance graphs using graph summarization and semantic zoom. It presents its users with a high-level abstracted view of the graph and the ability to incrementally drill down to the details.
PDF
Macko, P., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance, graphs, visualization
Collecting Provenance via the Xen Hypervisor
Abstract
The Provenance Aware Storage Systems project (PASS) currently collects system-level provenance by intercepting system calls in the Linux kernel and storing the provenance in a stackable filesystem. While this approach is reasonably efficient, it suffers from two significant drawbacks: each new revision of the kernel requires reintegration of PASS changes, the stability of which must be continually tested; also, the use of a stackable filesystem makes it difficult to collect provenance on root volumes, especially during early boot. In this paper we describe an approach to collecting system-level provenance from virtual guest machines running under the Xen hypervisor. We make the case that our approach alleviates the aforementioned difficulties and promotes adoption of provenance collection within cloud comput- ing platforms.
PDF
Slides (PDF)
Macko, P., Chiarini, M., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance, virtualization
Dimetrodon: Processor-level Preventive Thermal Management via Idle Cycle Injection
Abstract
Processor-level dynamic thermal management techniques have long targeted worst-case thermal margins. We examine the thermal-performance trade-offs in average-case, preventive thermal management by actively degrading application performance to achieve long-term thermal control. We propose Dimetrodon, the use of idle cycle injection, a flexible, per-thread technique, as a preventive thermal management mechanism and demonstrate its efficiency compared to hardware techniques in a commodity operating system on real hardware under throughput and latency-sensitive real-world workloads. Compared to hardware techniques that also lack flexibility, Dimetrodon achieves favorable trade-offs for temperature reductions up to 30% due to rapid heat dissipation during short idle intervals.
PDF
Peter Bailis, Vijay Janapa Reddi, Sanjay Gandhi, David Brooks, and Margo Seltzer
Proceeeding of the 2011 Design Automation Conference (DAC 2011), San Diego, CA, June 2011. Seltzer
architecture, scheduling, energy
Benchmarking File System Benchmarking: It *IS* Rocket Science
Abstract
The quality of file system benchmarking has not improved in over a decade of intense research spanning hundreds of publications. Researchers repeatedly use a wide range of poorly designed benchmarks, and in most cases, develop their own ad-hoc benchmarks. Our community lacks a definition of what we want to benchmark in a file system. We propose several dimensions of file system benchmarking and review the wide range of tools and techniques in widespread use. We experimentally show that even the simplest of benchmarks can be fragile, producing performance results spanning orders of magnitude. It is our hope that this paper will spur serious debate in our community, leading to action that can improve how we evaluate our file and storage systems.
PDF
Vasiliy Tarasov, Saumitra Hanage, Erez Zadok, Margo Seltzer
Proceedings of the 2011 Workshop on Hot Topics in Operating Systems (HOTOS XIII), Napa, CA, May 2011.
file systems, benchmarking, storage
Multicore OSes: Looking Forward from 1991, er, 2011
Abstract
Upcoming multicore processors, with hundreds of cores or more in a single chip, require a degree of parallel scalability that is not currently available in today’s system software. Based on prior experience in the supercomputing sector, the likely trend for multicore processors is away from shared memory and toward sharednothing architectures based on message passing. In light of this, the lightweight messages and channels programming model, found among other places in Erlang, is likely the best way forward. This paper discusses what adopting this model entails, describes the architecture of an OS based on this model, and outlines a few likely implementation challenges.
PDF
Slides (PDF)
David Holland, Margo Seltzer
Proceedings of the 2011 Workshop on Hot Topics in Operating Systems (HOTOS XIII), Napa, CA, May 2011.
os, operating systems
Mining the Web for Medical Hypotheses: A Proof-of-Concept System
Abstract
As the prevalence of blogs, discussion forums, and online news services continues to grow, so too does the portion of this Web content that relates to health and medicine. We propose that everyday, medically-oriented Web content is a valuable and viable data source for medical hypothesis generation and testing, despite its being noisy. In this paper, we present a proof-of-concept system supporting this notion. We construct a corpus comprising news articles relating to the drugs Vioxx, Naproxen and Ibuprofen, that were published between 1998-2002. Using this corpus, we show that there was a significant link between Vioxx and the concept “Myocardial Infarction” well before the drug was withdrawn from the market in 2004. Indeed, within the Vioxx-related content, the concept ranks amongst the top 3.3% in terms of importance. When compared with the Naproxen and Ibuprofen control literatures, the term occurs significantly more frequently in the Vioxx- related content.
PDF
Diana Maclean, Margo Seltzer
Proceedings of the International Conference on Health Informatics, Rome Italy, January 2011.
medical, data mining
2010
Tracking Back References in a Write-Anywhere File System
Abstract
Many file systems reorganize data on disk, for example to defragment storage, shrink volumes, or migrate data between different classes of storage. Advanced file system features such as snapshots, writable clones, and deduplication make these tasks complicated, as moving a single block may require finding and updating dozens, or even hundreds, of pointers to it.
We present Backlog, an efficient implementation of explicit back references, to address this problem. Back references are file system meta-data that map physical block numbers to the data objects that use them. We show that by using LSM-Trees and exploiting the write-anywhere behavior of modern file systems such as NetApp R WAFL R or btrfs, we can maintain back reference meta-data with minimal overhead (one extra disk I/O per 102 block operations) and provide excel- lent query performance for the common case of queries covering ranges of physically adjacent blocks.
PDF
Peter Macko, Margo Seltzer, Keith A. Smith
Proceedings of the 8th Conference on File and Storage Technologies (FAST'10), San Jose, CA, February 2010.
storage, file systems
Provenance for the Cloud
Abstract
The cloud is poised to become the next computing environment for both data storage and computation due to its pay-as-you-go and provision-as-you-go models. Cloud storage is already being used to back up desktop user data, host shared scientific data, store web application data, and to serve web pages. Today's cloud stores, however, are missing an important ingredient: provenance.
Provenance is metadata that describes the history of an object. We make the case that provenance is crucial for data stored on the cloud and identify the properties of provenance that enable its utility. We then examine current cloud offerings and design and implement three protocols for maintaining data/provenance in current cloud stores. The protocols represent different points in the de- sign space and satisfy different subsets of the provenance properties. Our evaluation indicates that the overheads of all three protocols are comparable to each other and reasonable in absolute terms. Thus, one can select a protocol based upon the properties it provides without sacrificing performance. While it is feasible to provide provenance as a layer on top of today's cloud offerings, we conclude by presenting the case for incorporating provenance as a core cloud feature, discussing the issues in doing so.
PDF
Kira-Kumar Muniswamy-Reddy, Peter Macko, Margo Seltzer
Proceedings of the 8th Conference on File and Storage Technologies (FAST'10), San Jose, CA, February 2010.
cloud, provenance
Towards Query Interoperability: PASSing PLUS
Abstract
We describe our experiences importing PASS provenance into PLUS. Although both systems import and export provenance that conforms to the Open Provenance Model (OPM), the two systems vary greatly with respect to the granularity of provenance captured, how much semantic knowledge the system contributes, and the completeness of provenance capture. We encountered several problems reconciling provenance between the two systems and use that experience to specify a Common Provenance Framework, that provides a higher degree of interoperability between provenance systems. In each case, the problems stem from the fact that OPM interoperability is a weaker requirement than query interoperability. Our goal in presenting this work is to generate discussion about differing degrees of interoperability and the requirements thereof.
PDF
Slides (PDF)
Uri Braun, Margo Seltzer, Adriane Chapman, Barbara Blaustein, M. David Allen, Len Seligman
Proceedings of the 2nd Workshop on the Theory and Practice of Provenance (TaPP'10) San Jose, CA, February 2010.
provenance
Provenance as first class cloud data
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Muniswamy-Reddy, K. and Seltzer, M.
Operating Systems Review, ACM 43, 4 (Jan. 2010), 11-16.
provenance, cloud
2009
Provenance: a future history.
Abstract
Science, industry, and society are being revolutionized by radical new capabilities for information sharing, distributed computation, and collaboration offered by the World Wide Web. This revolution promises dramatic benefits but also poses serious risks due to the fluid nature of digital information. One important cross-cutting issue is managing and recording provenance, or metadata about the origin, context, or history of data. We posit that provenance will play a central role in emerging advanced digital infrastructures. In this paper, we outline the current state of provenance research and practice, identify hard open research problems involving provenance semantics, formal modeling, and security, and articulate a vision for the future of provenance.
PDF
Cheney, J., Chong, S., Foster, N., Seltzer, M., and Vansummeren, S.
Proceeding of the 24th ACM SIGPLAN Conference Companion on Object Oriented Programming Systems Languages and Applications (Orlando, Florida, USA, October 25 - 29, 2009). OOPSLA '09. ACM, New York, NY, 957-964.
provenance
Provenance as First-Class Cloud Data
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Muniswamy-Reddy, K., Seltzer, M.
3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (LADIS'09), October 2009.
provenance, cloud
Layering in Provenance Systems
Abstract
Digital provenance describes the ancestry or history of a digital object. Most existing provenance systems, however, operate at only one level of abstraction: the system call layer, a workflow specification, or the high-level constructs of a particular application. The provenance collectable in each of these layers is different, and all of it can be important. Single-layer systems fail to account for the different levels of abstraction at which users need to reason about their data and processes. These systems cannot integrate data provenance across layers and cannot answer questions that require an integrated view of the provenance.
We have designed a provenance collection structure facilitating the integration of provenance across multiple levels of abstraction, including a workflow engine, a web browser, and an initial runtime Python provenance tracking wrapper. We layer these components atop provenance-aware network storage (NFS) that builds upon a Provenance-Aware Storage System (PASS). We discuss the challenges of building systems that integrate provenance across multiple layers of abstraction, present how we augmented systems in each layer to integrate provenance, and present use cases that demonstrate how provenance spanning multiple layers provides functionality not available in existing systems. Our evaluation shows that the overheads imposed by layering provenance systems are reasonable.
HTML
PDF
Slides (PDF)
Muniswamy-Reddy, K., Braun, U., Holland, D., Macko, P., Maclean, D., Margo, D., Seltzer, M., Smogor, R.
Proceedings of the 2009 USENIX Annual Technical Conference, San Diego, CA, June 2009.
provenance, os
Hierarchical File Systems Are Dead
Abstract
For over forty years, we have assumed hierarchical file system namespaces. These namespaces were a rudimentary attempt at simple organization. As users have begun to interact with increasing amounts of data and are increasingly demanding search capability, such a simple hierarchical model has outlasted its usefulness. For this reason, we should design file systems whose organizations map to the ways we access and manipulate data now. We present a new file system architecture in which we replace the hierarchical namespace with a tagged, search-based one.
PDF
Slides (PDF)
Seltzer, M., Murphy, M.
Proceedings of the 12th Workshop on Hot Topics in Operating Systems (HOTOS'09), Monte Verita, Switzerland, May 2009.
file systems, storage
The Case for Browser Provenance
(PDF)
Margo, D., Seltzer, M.
1st Workshop on the Theory and Practice of Provenance (TaPP'09), February 2009.
provenance, ui
Making a Cloud Provenance-Aware
(PDF)
Muniswamy-Reddy, K., Seltzer, M.
1st Workshop on the Theory and Practice of Provenance (TaPP'09), February 2009.
provenance, cloud
2008
Securing Provenance
(PDF)
Braun, U., Shinnar, A., Seltzer, M.
Proceedings of the 3rd USENIX Workshop on Hot Topics in Security (HotSec), San Jose, CA, July 2008.
provenance, security
Choosing a Data Model and Query Language for Provenance
(PDF)
Holland, D., Braun, U., Maclean, D., Muniswamy-Reddy, K., Seltzer, M.
Proceedings of the 2nd International Provenance and Annotation Workshop, Salt Lake City, UT, Jun 2008.
provenance, pl
2007
Improving Performance Isolation on Chip Multiprocessors via an Operating System Scheduler
Abstract
We describe a new operating system scheduling algorithm that improves performance isolation on chip multiprocessors (CMP). Poor performance isolation occurs when an application’s performance is determined by the behaviour of its co-runners, i.e., other applications simultaneously running with it. This performance dependency is caused by unfair, co- runner-dependent cache allocation on CMPs. Poor performance isolation interferes with the operating system’s control over priority enforcement and hinders QoS provisioning. Previous solutions required modifications to the hardware. We present a new software solution. Our cache-fair algorithm ensures that the application runs as quickly as it would under fair cache allocation, regardless of how the cache is actually allocated. If the thread executes fewer instructions per cycle than it would under fair cache allocation, the scheduler increases that thread’s CPU timeslice. This way, the thread’s overall performance does not suffer because it is allowed to use the CPU longer. We describe our implementation of the algorithm in SolarisTM 10, and show that it significantly improves performance isolation for SPEC CPU, SPEC JBB and TPC-C.
PDF
Fedorova, A., Seltzer, M., Smith, M.D.
Proceedings of the Sixteenth International Conference on Parallel Architectures and Compilation Techniques (PACT), Brasov, Romania, September 2007.
operating systems, scheduling
Can a System Virtualize Processors?
(PDF, Slides)
Stein, L., Holland, D., Seltzer, M., Zhang, Z.
Proceedings of the First EuroSys Workshop on Virtualization for HPC, Lisbon, Portugal, March 2007.
virtualization
PASS-ing the Provenance Challenge
(PDF)
Holland, D., Seltzer, M., Braun, U., Muniswamy-Reddy, K.
Special Edition of Concurrency and Computation: Practice and Experience Wiley and Sons, 2007.
provenance
Network Coordinates in the Wild
Abstract
Network coordinates provide a mechanism for selecting and placing servers efficiently in a large distributed system. This approach works well as long as the coordinates continue to accurately reflect network topology. We conducted a long-term study of a subset of a million-plus node coordinate system and found that it exhibited some of the problems for which network coordinates are frequently criticized, for example, inaccuracy and fragility in the presence of violations of the triangle inequality. Fortunately, we show that several simple techniques remedy many of these problems. Using the Azureus BitTorrent network as our testbed, we show that live, large-scale network coordinate systems behave differently than their tame PlanetLab and simulation-based counterparts. We find higher relative errors, more triangle inequality violations, and higher churn. We present and evaluate a number of techniques that, when applied to Azureus, efficiently produce accurate and stable network coordinates
HTML
PDF
Ledlie, J., Gardner, P., Seltzer, M.
Proceedings of the Conference on Network System Design and Implementation, Boston MA, April 2007.
networking
2006
Data Management for Internet-Scale Single-Sign-On
(PDF)
Sharon Perl, Margo Seltzer
2006 USENIX Workshop on Real, Large Distributed Systems (Worlds '06)
single sign-on, berkeley-db, BDB-HA, replication, high-availability
A Non-Work-Conserving Operating System Scheduler For SMT Processors
(PDF)
Fedorova, A., Seltzer, M., Smith, M.D.
Proceedings of the Workshop on the Interaction between Operating Systems and Computer Architecture (WIOSCA 2006), Boston MA, June 2006.
operating systems, scheduling
Provenance-Aware Storage Systems
Abstract
A Provenance-Aware Storage System (PASS) is a storage system that automatically collects and maintains prove- nance or lineage, the complete history or ancestry of an item. We discuss the advantages of treating provenance as meta-data collected and maintained by the storage system, rather than as manual annotations stored in a separately administered database. We describe a PASS implementation, discussing the challenges it presents, performance cost it incurs, and the new functionality it enables. We show that with reasonable overhead, we can provide useful functionality not available in today's file systems or provenance management systems.
HTML
PDF
Muniswamy-Reddy, K., Holland, D., Braun, U., Seltzer, M.
Proceedings of the 2006 USENIX Annual Technical Conference, Boston, MA, June 2006.
provenance, storage, file systems
Issues in Automatic Provenance Collection
Abstract
Automatic provenance collection describes systems that observe processes and data transformations inferring, collecting, and maintaining provenance about them. Automatic collection is a powerful tool for analysis of ob jects and processes, providing a level of transparency and pervasiveness not found in more conventional provenance systems. Unfortunately, automatic collection is also difficult. We discuss the challenges we encountered and the issues we exposed as we developed an automatic provenance collector that runs at the operating system level.
PDF
Braun, U., Garfinkel, S., Holland, D., Muniswamy-Reddy, K., Seltzer, M.,
Proceedings of the 2006 International Provenance and Annotation Workshop, Chicago, IL, May 2006.
provenance
EGG: An Extensible and Economics-inspired Open Grid Computing Platform
Abstract
The Egg project provides a vision and implementation of how heterogeneous computational requirements will be supported within a single grid and a compelling reason to explain why computational grids will thrive. Environment computing, which allows a user to specify properties that a compute environment must satisfy in order to support the users computation, provides a how. Economic principles, allowing resource owners, users, and other stakeholders to make value and policy statements, provides a why. The Egg project introduces a language for defining software environments (egg shell), a general type for grid objects (the cache), and a currency (the egg). The Egg platform resembles an economically driven Internet-wide Unix system with egg shell playing the role of a scripting language and caches playing the role of a global file system, including an initial collection of devices.
PDF
Slides (PDF)
Brunelle, J., Hurst, P., Huth, J., Kang, L., Ng, C., Parkes, D., Seltzer, M., Shank, J., Youssef, S.
Proceedings of the 2006 Grid Asia, Singapore, May 2006.
econcs
Network-Aware Operator Placement for Stream-Processing Systems
Abstract
To use their pool of resources efficiently, distributed stream-processing systems push query operators to nodes within the network. Currently, these operators, ranging from simple filters to custom business logic, are placed manually at intermediate nodes along the transmission path to meet application-specific performance goals. Determining placement locations is challenging because network and node conditions change over time and because streams may interact with each other, opening venues for reuse and repositioning of operators.
This paper describes a stream-based overlay network (SBON), a layer between a stream-processing system and the physical network that manages operator placement for stream-processing systems. Our design is based on a cost space, an abstract representation of the network and on-going streams, which permits decentralized, large-scale multi-query optimization decisions. We present an evaluation of the SBON approach through simulation, experiments on PlanetLab, and an integration with Borealis, an existing stream-processing engine. Our results show that an SBON consistently improves network utilization, provides low stream latency, and enables dynamic optimization at low engineering cost.
PDF
Pietzuch, P., Ledlie, J., Shneidman, J., Roussopoulos, M., Welsh, M., Seltzer, M.
Proceedings fo the 22nd International Conference on Data Engineering (ICDE ’06), Atlanta, GA, April 2006.
networking
2005
Supporting Network Coordinates on PlanetLab
Abstract
Large-scale distributed applications need latency information to make network-aware routing decisions. Collecting these measurements, however, can impose a high burden. Network coordinates are a scalable and efficient way to supply nodes with up-to-date latency estimates. We present our experience of maintaining network coordinates on PlanetLab. We present two different APIs for accessing coordinates: a per-application library, which takes advantage of application-level traffic, and a stand-alone service, which is shared across applications. Our results show that statistical filtering of latency samples improves accuracy and stability and that a small number of neighbors is sufficient when updating coordinates.
PDF
Pietzuch, P., Ledlie, J., Seltzer, M.
Proceedings of the Second Workshop on Real, Large Distributed Systems (WORLDS’05), San Francisco, CA, December 2005.
networking
Beyond Relational Databases
Abstract
This article discusses how data management needs vary across applications, pointing out that one needs to match database solutions with data management needs.
PDF
Seltzer, M.
ACM Queue, 3,3 April 2005
databases, kvstore
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design
Abstract
We investigated how operating system design should be adapted for multithreaded chip multiprocessors (CMT) -- a new generation of processors that exploit thread-level parallelism to mask the memory latency in modern workloads. We determined that the L2 cache is a critical shared resource on CMT and that an insufficient amount of L2 cache can undermine the ability to hide memory latency on these processors. To use the L2 cache as efficiently as possible, we propose an L2-conscious scheduling algorithm and quantify its performance potential. Using this algorithm it is possible to reduce miss ratios in the L2 cache by 25-37% and improve processor throughput by 27-45%.
PDF
Fedorova, A., Seltzer, M., Small, C., Nussbaum, D.
Proceedings of the 2005 Annual Technical Conference, Anaheim, CA April 2005.
operating systems, caching, scheduling
A Cost-Space Approach to Distributed Query Optimization in Stream-Based Overlays
Abstract
Distributed stream-based applications, such as continuous query systems, have network scale and time characteristics that challenge traditional distributed query optimization. The optimization sub-problems of plan generation and service placement should be integrated to meet these challenges. These tasks have typically been treated as independent sub-problems because of the complexity of their integration. We suggest cost spaces as one way to mitigate this complexity. We further consider how cost spaces can be used to allow tractable multi-query optimization.
PDF
Shneidman, J., Pietzuch, P., Welsh, M., Seltzer, M., Roussopoulos, M.
Proceedings of the 1st IEEE International Workshop on Networking Meets Databases (NetDB’05), Tokyo, Japan, April 2005.
algorithms, networking, p2p
Provenance Aware Sensor Data Storage
Abstract
Sensor network data has both historical and real-time value. Making historical sensor data useful, in particular, requires storage, naming, and indexing. Sensor data presents new challenges in these areas. Such data is location-specific but also distributed; it is collected in a particular physical location and may be most useful there, but it has additional value when com- bined with other sensor data collections in a larger distributed sys- tem. Thus, arranging location-sensitive peer-to-peer storage is one challenge. Sensor data sets do not have obvious names, so naming them in a globally useful fashion is another challenge. The last challenge arises from the need to index these sensor data sets to make them searchable. The key to sensor data identity is prove- nance, the full history or lineage of the data. We show how prove- nance addresses the naming and indexing issues and then present a research agenda for constructing distributed, indexed repositories of sensor data.
PDF
Slides (PDF)
Ledlie, J., Ng, C., Holland, D., Muniswamy-Reddy, K., Braun, U., Seltzer, M.
Proceedings of the 1st IEEE International Workshop on Networking Meets Databases (NetDB05) Tokyo, Japan, April 2005.
provenance, sensor networks, iot, naming
Distributed, Secure Load Balancing with Skew, Heterogeneity, and Churn
Abstract
Numerous proposals exist for load balancing in peer-to-peer (p2p) networks. Some focus on namespace balancing, making the distance between nodes as uniform as possible. This technique works well under ideal conditions, but not under those found empirically. Instead, researchers have found heavy-tailed query distributions (skew), high rates of node join and leave (churn), and wide variation in node network and storage capacity (heterogeneity). Other approaches tackle these less-than-ideal conditions, but give up on important security properties. We propose an algorithm that both facilitates good performance and does not dilute security. Our algorithm, k-Choices, achieves load balance by greedily matching nodes' target workloads with actual applied workloads through limited sampling, and limits any fundamental decrease in security by basing each node's set of potential identifiers on a single certificate. Our algorithm compares favorably to four others in trace-driven simulations. We have implemented our algorithm and found that it improved aggregate throughput by 20% in a widely heterogeneous system in our experiments.
PDF
Slides (PDF)
Ledlie, J., Seltzer, M.
Proceedings of the 2005 INFOCOM, March 2005.
algorithms, p2p, load balancing
Evaluating DHT Service Placement in Stream-Based Overlays
Abstract
Stream-based overlay networks (SBONs) are one approach to implementing large-scale stream processing systems. A fundamental consideration in an SBON is that of service placement, which determines the physical location of in-network processing services or operators, in such a way that network resources are used efficiently. Service placement consists of two components: node discovery, which selects a candidate set of nodes on which services might be placed, and node selection, which chooses the particular node to host a service. By viewing the placement problem as the composition of these two processes we can trade-off quality and efficiency between them. A bad discovery scheme can yield a good placement, but at the cost of an expensive selection mechanism.
Recent work on operator placement proposes to leverage routing paths in a distributed hash table (DHT) to obtain a set of candidate nodes for service placement. We evaluate the appropriateness of using DHT routing paths for service placement in an SBON, when aiming to minimize network usage. For this, we consider two DHT-based algorithms for node discovery, which use either the union or intersection of DHT routing paths in the SBON, and compare their performance to other techniques. We show that current DHT-based schemes are actually rather poor node discovery algorithms, when minimizing network utilization. An efficient DHT may not traverse enough hops to obtain a sufficiently large candidate set for placement. The union of DHT routes may result in a low-quality set of discovered nodes that requires an expensive node selection algorithm. Finally, the intersection of DHT routes relies on route convergence, which prevents the placement of services with a large fan-in.
PDF
Pietzuch, P, Shneidman, J., Ledlie, J., Welsh, M., Seltzer, M., Roussopoulos, M.
Proceedings of the International Workshop on Peer to Peer Systems (IPTPS’05), Ithaca, NY, February 2005.
algorithms, p2p, networking
2004
An Architecture A Day Keeps the Hacker Away
Abstract
System security as it is practiced today is a losing battle. In this paper, we outline a possible comprehensive solution for binary-based attacks, using virtual machines, machine descriptions, and randomization to achieve broad heterogeneity at the machine level. This heterogeneity increases the "cost" of broad-based binary attacks to a sufficiently high level that they cease to become feasible. The convergence of several recent technologies appears to make our approach achievable at a reasonable cost, with only moderate run-time overhead.
PDF
Slides (PDF)
Holland, D., Lim, A., Seltzer, M.
Proceedings of the 2004 Workshop on Architectural Support for Security and Anti-Virus," Boston, MA, April 2004.
architecture, synthesis
Open Problems in Data Collection
Abstract
Research in sensor networks, continuous queries (CQ), and other domains has been motivated by powerful applications that aim to aggregate, assimilate, and interact with scores of sensor networks in parallel. Numerous system ingredients are necessary to make these applications possible. Sensor network research is building some of these components from the bottom up, dealing with issues such as wireless connectivity and battery life. CQ, peer-to-peer (P2P), and other research areas are building top down, examining in-network services, naming, decentralized queries, and scale. While many research groups use the same types of applications to motivate their work, many of these applications cannot be built today because of missing bridge research. These challenges include: uniting vastly differing devices and services, managing intermittent connectivity, placing in-network services with QoS and other constraints, developing unified security models, and correlating between sensor networks. This paper distills these new problems and outlines one proposed system that explores solutions to these concerns.
PDF
Ledlie, J., Shneidman, J., Welsh, M., Roussopoulos, M. Seltzer, M.
Networks Proceedings of the 2004 SIGOPS European Workshop, September 2004, Leuven, Belgium.
networking, sensor networks, p2p
Chip Multithreading Systems Need a New Operating System Scheduler
Abstract
The unpredictable nature of modern workloads, characterized by frequent branches and control transfers, can result in processor pipeline utilization as low as 19%. Chip multithreading (CMT), a processor architecture combining chip multiprocessing and hardware multithreading, is designed to address this issue. Hardware vendors plan to ship CMT systems within the next two years; understanding how such systems will perform is crucial if we are to use them to full advantage.
Our simulation experiments show that a CMT-savvy operating system scheduler could improve application performance by a factor of two. In this paper we describe our initial analysis of application performance on CMT systems and propose a design for a scheduler tailored for the needs of a CMT system.
PDF
Fedorova, A., Small, C., Nussbaum, D., Seltzer, M.
Proceedings of the 2004 SIGOPS EUropean Workshop, September 2004, Leuven, Belgium.
operating systems, scheduling
File classification in self-* storage systems
Abstract
To tune and manage themselves, file and storage systems must understand key properties (e.g., access pattern, lifetime, size) of their various files. This paper describes how systems can automatically learn to classify the properties of files (e.g., read-only access pattern, short-lived, small in size) and predict the properties of new files, as they are created, by exploiting the strong associations between a file's properties and the names and attributes assigned to it. These associations exist, strongly but differently, in each of four real NFS environments studied. Decision tree classifiers can automatically identify and model such associations, providing prediction accuracies that often exceed 90%. Such predictions can be used to select storage policies (e.g., disk allocation schemes and replication factors) for individual files. Further, changes in associations can expose information about applications, helping autonomic system components distinguish growth from fundamental change.
PDF
PostScript
Mesnier, M., Thereska, E., Ellard, D., Ganger, G., Seltzer, M.
Proceedings of the International Conference on Autonomic Computing (ICAC-04), May 2004, New York, NY.
file systems, naming
The Case Against User-level Networking
Abstract
Extensive research on system support for enabling I/O-intensive applications to achieve performance close to the limits imposed by the hardware suggests two main approaches: Low overhead I/O protocols and the flexibility to customize I/O policies to the needs of applications. One way to achieve both is by supporting user-level access to I/O devices, enabling user-level implementations of I/O protocols. User-level networking is an example of this approach, specific to network interface controllers (NICs). In this paper, we argue that the real key to high-performance in I/O-intensive applications is user-level file caching and user-level network buffering, both of which can be achieved without user-level access to NICs.
Avoiding the need to support user-level networking carries two important benefits for overall system design: First, a NIC exporting a privileged kernel interface is simpler to design and implement than one exporting a user-level interface. Second, the kernel is re-instated as a global system resource controller and arbitrator. We develop an analytical model of network storage applications and use it to show that their performance is not affected by the use of a kernel-based API to NICs.
PDF
Magoutis, K., Seltzer, M., Gabber, E.
Proceedings of the Third Annual Workshop on System-Area Networks (SAN-3), February 2004, Madrid Spain.
operating systems, networking
Application Performance on the Direct Access File System
Abstract
The Direct Access File System (DAFS) is a distributed file system built on top of direct-access transports (DAT). Direct- access transports are characterized by using remote direct memory access (RDMA) for data transfer and user-level networking. The motivation behind the DAT-enabled distributed file system architecture is the reduction of the CPU overhead on the I/O data path.
We have created an implementation of DAFS for the FreeBSD platform. In this paper we describe the performance evaluation study of DAFS that we have performed using this software. The goal of this study is to determine whether the architecture of DAFS brings any fundamental performance benefits to applications compared to traditional distributed file systems, such as NFS. We perform comparison of DAFS to a version of NFS optimized to reduce the I/O overhead. In order to thoroughly understand the impact of DAFS on application performance, we consider a diverse range of applications workloads.
We conclude that DAFS can accomplish superior performance for latency-sensitive applications, outperforming NFS by up to a factor of 2. Bandwidth-sensitive applications do equally well on both systems, unless they are CPU-intensive, in which case they perform better on DAFS. We also found that RDMA is a less restrictive mechanism to achieve copy avoidance than that used by the optimized NFS.
PDF
Fedorova, A., Seltzer, M., Magoutis, K., Addetia, S.
Proceedings of Workshop on Software and Performance 2004 (WOSP’04), January 2004, Redwood City, CA.
file systems, networking
2003
New NFS Tracing Tools and Techniques for System Analysis
Abstract
Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF
PostScript
Ellard, D., Seltzer, M.
Proceedings of the 17th Annual Large Installation System Administration Conference (LISA’03), October 2003, San Diego, CA, pp 73-85.
file systems, tools
NFS Tricks and Benchmarking Traps
Abstract
We describe two modifications to the FreeBSD 4.6 NFS server to increase read throughput by improving the read-ahead heuristic to deal with reordered requests and stride access patterns. We show that for some stride access patterns, our new heuristics improve end-to-end NFS throughput by nearly a factor of two. We also show that benchmarking and experimenting with changes to an NFS server can be a subtle and challenging task, and that it is often difficult to distinguish the impact of a new algorithm or heuristic from the quirks of the underlying software and hardware with which they interact. We discuss these quirks and their potential effects.
PDF
PostScript
Slides (PDF)
Ellard, D., Seltzer, M.
Proceedings of the 2003 FREENIX Technical Conference, June 2003, San Antonio, TX, pp 101-114.
file systems
Passive NFS Tracing of Email and Research Workloads
Abstract
We present an analysis of a pair of NFS traces of contemporary email and research workloads. We show that although the research workload resembles previously-studied workloads, the email workload is quite different. We also perform several new analyses that demonstrate the periodic nature of file system activity, the effect of out-of-order NFS calls, and the strong relationship between the name of a file and its size, lifetime, and access
PDF
PostScript
Slides (PDF)
Ellard, D., Ledlie, J., Malkani, P., Seltzer, M
Proceedings of the Second Symposium on File and Storage Technologies, March 2003, San Francisco, CA, pp 203-216.
file systems, tools
Making the Most Out of Direct-Access Network Attached Storage
Abstract
The performance of high-speed network-attached storage applications is often limited by end-system overhead, caused primarily by memory copying and network protocol processing. In this paper, we examine alternative strategies for reducing overhead in such systems. We consider optimizations to remote procedure call (RPC)-based data transfer using either remote direct memory access (RDMA) or network interface support for pre-posting of application receive buffers. We demonstrate that both mechanisms enable file access throughput that saturates a 2Gb/s network link when performing large I/Os on relatively slow, commodity PCs. However, for multi-client workloads dominated by small I/Os, throughput is limited by the per-I/O overhead of processing RPCs in the server. For such workloads, we propose the use of a new network I/O mechanism, Optimistic RDMA (ORDMA). ORDMA is an alternative to RPC that aims to improve server throughput and response time for small I/Os. We measured performance improvements of up to 32% in server throughput and 36% in response time with use of ORDMA in our prototype.
PDF
Magoutis, K, Fedorova, A., Addetia, S., Seltzer, M.
Proceedings of the Second Symposium on File and Storage Technologies, March 2003, San Francisco, CA.
file systems, networking
Scooped Again
Abstract
The Peer-to-Peer (p2p) and Grid infrastructure communities are tackling an overlapping set of problems. In addressing these problems, p2p solutions are usually motivated by elegance or research interest. Grid researchers, under pressure from thousands of scientists with real file sharing and computational needs, are pooling their solutions from a wide range of sources in an attempt to meet user demand. Driven by this need to solve large scientific problems quickly, the Grid is being constructed with the tools at hand: FTP or RPC for data transfer, centralization for scheduling and authentication, and an assumption of correct, obediant nodes. If history is any guide, the World Wide Web depicts viscerally that systems that address user needs can have enormous staying power and affect future research. The Grid infrastructure is a great customer waiting for future p2p products. By no means should we make them our only customers, but we should at least put them on the list. If p2p research does not at least address the Grid, it may eventually be sidelined by defacto distributed algorithms that are less elegant but were used to solve Grid problems. In essense, well have been scooped, again.
PDF
PostScript
Ledlie, J., Shneidman, J., Seltzer, M., Huth, J.
Proceedings of the Second International Workshop on Peer-to-Peer Systems (IPTPS-03), Berkeley, CA, February 2003.
networking, p2p
2002
Building a Reliable Mutable File System on Peer-to-peer Storage
Abstract
This paper sketches the design of the Eliot File System (Eliot), a mutable filesystem that maintains the pure im- mutability of its peer-to-peer (P2P) substrate by isolating mutation in an auxiliary metadata service.
The immutability of address-to-content bindings has several advantages in P2P systems. However, mutable filesystems are desirable because they allow clients to update existing files; a necessary property for many applications. In order to facilitate modifications, the filesystem must provide some atom of mutability. Since this atom of mutability is a fundamental characteristic of the filesystem and not the underlying storage substrate, it is a mistake to violate the integrity of the substrate with special cases for mutability. Instead, Eliot employs a separate, generalized metadata service that isolates all mutation and client state in an auxiliary replicated database. Eliot provides fine-granularity file updates with either AFS open/close or NFS-like consistency semantics. Eliot builds a mutable filesystem on a global resource bed of purely immutable P2P block storage.
PDF
PostScript
Stein, C., Tucker, M., Seltzer, M.
Proceedings of the International Workshop on Reliable Peer-to-peer Distributed Systems, Osaka, Japan, October 2002.
file systems, p2p
Self-Organization in Peer-to-Peer Systems
Abstract
This paper addresses the problem of forming groups in peer-to-peer (P2P) systems and examines what dependability means in decentralized distributed systems. Much of the literature in this field assumes that the participants form a local picture of global state, yet little research has been done discussing how this state remains stable as nodes enter and leave the system. We assume that nodes remain in the system long enough to benefit from retaining state, but not sufficiently long that the dynamic nature of the problem can be ignored. We look at the components that describe a system's dependability and argue that next-generation decentralized systems must explicitly delineate the information dispersal mechanisms (e.g., probe, event-driven, broadcast), the capabilities assumed about constituent nodes (bandwidth, uptime, re-entry distributions), and distribution of information demands (needles in a haystack vs. hay in a haystack). We evaluate two systems based on these criteria: Chord and a heterogeneous-node hierarchical grouping scheme. The former gives a greater than 1 failed request rate under normal P2P conditions and a prototype of the latter a similar rate under more strenuous conditions with an order of magnitude more organizational messages. This analysis suggests several methods to greatly improve the prototype.
PDF
PostScript
Ledlie, J., Taylor, J., Serban, L., Seltzer, M.
Proceedings of the 10th ACM SIGOPS European Workshop, Saint-Emilion, France, September 2002.
networking, p2p
Structure and Performance of the Direct Access File System
Abstract
The Direct Access File System (DAFS) is an emerging industrial standard for network-attached storage. DAFS takes advantage of new user-level network interface standards. This enables a user-level file system structure in which client-side functionality for remote data access resides in a library rather than in the kernel. This structure addresses longstanding performance problems stemming from weak integration of buffering layers in the network transport, kernel-based file systems and applications. The benefits of this architecture include lightweight, portable and asynchronous access to network storage and improved application control over data movement, caching and prefetching.
This paper explores the fundamental performance characteristics of a user-level file system structure based on DAFS. It presents experimental results from an open-source DAFS prototype and compares its performance to a kernel-based NFS implementation optimized for zero-copy data transfer. The results show that both systems can deliver file access throughput in excess of 100 MB/s, saturating network links with similar raw bandwidth. Lower client overhead in the DAFS configuration can improve application performance by up to 40% over optimized NFS when application processing and I/O demands are well-balanced.
PDF
Magoutis, K., Addetia, S., Fedorova, A., Seltzer, M., Chase, J., Gallatin, D., Kisley, R., Wickremesinghe, R., Gabber, E.
Proceedings of the 2002 USENIX Technical Conference, June 2002, Monterey, CA, 1–14.
file systems, networking
On the Design of a New CPU Architecture for Pedagogical Purposes
Abstract
Ant-32 is a new processor architecture designed specifically to address the pedagogical needs of teaching many subjects, including assembly language programming, machine architecture, compilers, operating systems, and VLSI design. This paper discusses our motivation for creating Ant-32 and the philosophy we used to guide our design decisions and gives a high level decsription of the resulting design.
PDF
PostScript
Ellard, D., Holland, D., Murphy, N, Seltzer, M.
Proceedings of the Workshop on Computer Architecture Education, May, 2002, Anchorage, Alaska.
architecture, education
A New Instructional Operating System
Abstract
his paper presents a new instructional operating system, OS/161, and simulated execution environment, System/161, for use in teaching an introductory undergraduate operating systems course. We describe the new system, the assignments used in our course, and our experience teaching using the new system.
PDF
PostScript
Holland, D., Lim, A., and Seltzer, M.
Proceedings of the 2002 SIGCSE Conference, February 2002, Covington, KY, 111–115.
operating systems, education
2001
Unifying File System Protection
(PDF)
Stein, C., Howard, J., Seltzer, M.
Proceedings of the 2001 USENIX Technical Conference, June 2001, Boston, MA, 79–90.
file systems, security
Research Issues in No-Futz Computing
Abstract
At the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), the attendees reached consensus that the most important issue facing the OS research community was "No-Futz" computing; eliminating the ongoing "futzing" that characterizes most systems today. To date, little research has been accomplished in this area. Our goal in writing this paper is to focus the research community on the challenges we face if we are to design systems that are truly futz-free, or even low-futz.
PDF
PostScript
Holland, D., Josephson, W., Magoutis, K., Seltzer, M., Stein, C.
Proceedings of the 2001 Workshop on Hot Topics in Operating Systems (HotOS VII), Elmau Germany, May 2001.
operating systems
HBench:JGC - An Application-Specific Benchmark Suite for Evaluating JVM Garbage Collector Performance
Abstract
As Java becomes a viable platform for server applications, performance becomes a greater concern. An important aspect of Java Virtual Machine performance is its dynamic memory management system (garbage collection or GC). Traditional GC benchmarking often focuses on a set of fixed applications. As a result, when an actual application's memory behavior differs from that of the standard benchmarks, the benchmark results do not help the user judge which GC implementation suits her application the best. In this paper, we present HBench:JGC, an application-specific benchmarking suite, based on the idea that a system's performance be measured in the context of a specific application. HBench:JGC employs a methodology that characterizes the application memory usage and the GC implementation independently and carefully combines both characterizations to form a single metric that reflects a particular application's performance in the presence of a particular GC implementation. We evaluate our approach on Sun Microsystems's JDK1.2.2 classic JVM with a sequential mark-sweep GC. Our results demonstrate HBench:JGC's unique predictive power and its ability to provide meaningful metrics that lead to a better understanding of GC performance.
PDF
Zhang, X., Seltzer, M.
Proceedings of the 6th USENIX Conference on Object-Oriented Technology (COOTS 2001), February 2001, San Antonio, TX.
benchmarking
2000
Journaling versus Soft Updates: Asynchronous Meta-data Protection in File Systems
Abstract
The UNIX Fast File System (FFS) is probably the most widely-used file system for performance comparisons. However, such comparisons frequently overlook many of the performance enhancements that have been added over the past decade. In this paper, we explore the two most commonly used approaches for improving the performance of meta-data operations and recovery: journaling and Soft Updates. Journaling systems use an auxiliary log to record meta-data operations and Soft Updates uses ordered writes to ensure meta-data consistency.
The commercial sector has moved en masse to journaling file systems, as evidenced by their presence on nearly every server platform available today: Solaris, AIX, Digital UNIX, HP-UX, Irix, and Windows NT. On all but Solaris, the default file system uses journaling. In the meantime, Soft Updates holds the promise of providing stronger reliability guarantees than journaling, with faster recovery and superior performance in certain boundary cases.
HTML
PDF
PostScript
Slides (PDF)
Slides (PostScript)
Seltzer, M., Ganger, G., McKusick, M., Smith, K., Soules, C., Stein, C.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 71–84.
file systems
Isolation with Flexibility: A Resource Management Framework for Central Servers
Abstract
Proportional-share resource management is becoming increasingly important in today's computing environments. In particular, the growing use of the computational resources of central service providers argues for a proportional-share approach that allows resource principals to obtain allocations that reflect their relative importance. In such environments, resource principals must be isolated from one another to prevent the activities of one principal from impinging on the resource rights of others. However, such isolation limits the flexibility with which resource allocations can be modified to reflect the actual needs of applications. We present extensions to the lottery-scheduling resource management framework that increase its flexibility while preserving its ability to provide secure isolation. To demonstrate how this extended framework safely overcomes the limits imposed by existing proportional-share schemes, we have implemented a prototype system that uses the framework to manage CPU time, physical memory, and disk bandwidth. We present the results of experiments that evaluate the prototype, and we show that our framework has the potential to enable server applications to achieve significant gains in performance.
Addendum
As discussed in our 2000 USENIX paper, lottery scheduling's currency abstraction imposes lower limits on the resource allocations that clients of a system can receive. In our USENIX paper, we proposed one method for overcoming these lower limits. In this addendum to the paper, we discuss a limitation of our original solution to the lower-limits problem, and we propose an alternate solution that overcomes the shortcomings of the original solution.
PDF
PostScript
Slides (PDF)
Addendum (PDF)
Sullivan., D., Seltzer, M.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 337–-350.
os, scheduling
Operating System Support for Multi-User, Remote Graphical Interaction
Abstract
The emergence of thin client computing and multi-user, remote, graphical interaction revives a range of operating system research issues long dormant, and introduces new directions as well. This paper investigates the effect of operating system design and implementation on the performance of thin client service and interactive applications. We contend that the key performance metric for this type of system and its applications is user-perceived latency and we give a structured approach for investigating operating system design with this criterion in mind. In particular, we apply our approach to a quantitative comparison and analysis of Windows NT, Terminal Server Edition (TSE), and Linux with the X Windows System, two popular implementations of thin client service.
We find that the processor and memory scheduling algorithms in both operating systems are not tuned for thin client service. Under heavy CPU and memory load, we observed user-perceived latencies up to 100 times beyond the threshold of human perception. Even in the idle state, these systems induce unnecessary latency. TSE performs particularly poorly despite scheduler modifications to improve interactive responsiveness. We also show that TSE's network protocol outperforms X by up to six times, and also makes use of a bitmap cache which is essential for handling dynamic elements of modern user interfaces and can reduce network load in these cases by up to 2000%.
PDF
Wong., A., Seltzer, M.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 183–196.
operating systems, networking
Improving Interactive System Performance Using TIPME
Abstract
On the vast majority of today's computers, the dominant form of computation is GUI-based user interaction. In such an environment, the user's perception is the final arbiter of performance. Human-factors research shows that a user's perception of performance is affected by unexpectedly long delays. However, most performance-tuning techniques currently rely on throughput-sensitive benchmarks. While these techniques improve the average performance of the system, they do little to detect or eliminate response-time variabilities--in particular, unexpectedly long delays.
We introduce a measurement infrastructure that allows us to improve user-perceived performance by helping us to identify and eliminate the causes of the unexpected long response times that users find unacceptable. We describe TIPME (The Interactive Performance Monitoring Environment), a collection of measurement tools that allowed us to quickly and easily diagnose interactive performance "bugs" in a mature operating system. We present two case studies that demonstrate the effectiveness of our measurement infrastructure. Each of the performance problems we identify drastically affects variability in response time in a mature system, demonstrating that current tuning techniques do not address this class of performance problems.
PDF
PostScript
Endo, Y., Seltzer, M.
Proceedings of the 2000 ACM Sigmetrics Conference, June 2000, Santa Clara, CA.
benchmarking
HBench:Java: An Application-Specific Benchmark for JVMs
Abstract
Java applications represent a broad class of programs, ranging from programs running on embedded products to high-performance server applications. Standard Java benchmarks ignore this fact and assume a fixed workload. When an actual application's behavior differs from that included in a standard benchmark, the benchmark results are useless, if not misleading. In this paper, we present HBench:Java, an application-specific benchmarking framework, based on the concept that a system's performance must be measured in the context of the application of interest. HBench:Java employs a methodology that uses vectors to characterize the application and the underlying JVM and carefully combines the two vectors to form a single metric that reflects a specific application's performance on a particular JVM such that the performance of multiple JVMs can be realistically compared. Our performance results demonstrate HBench:Java's superiority over traditional benchmarking approaches in predicting real application performance and its ability to pinpoint performance problems.
PDF
Zhang, X., Seltzer, M.
Proceedings of the ACM 2000 Java Grande Conference, June 2000, San Francisco, CA.
benchmarking
1999
Evaluating Windows NT Terminal Server Performance
Abstract
With the introduction of Windows NT, Terminal Server Edition (TSE), Microsoft finally brings to Windows the ``thin-client'' computing model the X Window System has offered Unix for a decade. TSE's two most salient features are the provision of multi-user login service and the provision of that service remotely, over a network link. These features distinguish TSE from previous Microsoft operating systems not only by functionality, but also by how its performance ought to be measured. Because TSE's primary service is interactive, user-perceived latency is more important than ever. In this paper, we examine the resource consumption and latency characteristics of shared usage on a TSE system. We find that the introduction of remote, multi-user access has added to the minimal level of resource consumption, that the efficiency of TSE's RDP protocol is generally good but degrades on dynamic user interface elements, and that TSE can exhibit poor latency performance when subjected to high processor, memory, and network load.
PDF
PostScript
Wong, A., Seltzer, M.
Proceedings of the 3rd USENIX Windows NT Symposium, July, 1999, Seattle, WA, 145–154.
benchmarking, ui
HACC: An Architecture for Cluster-Based Web Server
Abstract
This paper presents the design, implementation, and performance of the Harvard Array of Clustered Computers (HACC), a cluster-based design for scalable, cost-effective web servers. HACC is designed for locality enhancement. Requests that arrive at the cluster are distributed among the nodes so as to enhance the locality of reference that occurs on individual nodes in the cluster. By improving locality on individual cluster nodes, we can reduce their working set sizes and achieve superior performance for less cost than conventional approaches. We implemented HACC on Windows NT 4.0 and evaluated its performance for both static documents and workloads of dynamically generated documents adapted from logs of commercial web servers. Our performance results show that HACC's locality enhancement can improve performance by up to 121% for our stochastically generated static file case, by up to 40% for our trace-based static file case, and by up to 52% for our trace-based dynamic document case, compared to an IP-Sprayer approach to building cluster-based web servers.
PDF
Zhang, X., Barrientos, M., Chen, J., Seltzer, M.
Proceedings of the 3rd USENIX Windows NT Symposium, July, 1999, Seattle, WA, 155–164.
storage, p2p
Berkeley DB
Abstract
Berkeley DB is an Open Source embedded database system with a number of key advantages over comparable systems. It is simple to use, supports concurrent access by multiple users, and provides industrial-strength transaction support, including surviving system and disk crashes. This paper describes the design and technical features of Berkeley DB, the distribution, and its license.
PDF
Olson, M., Bostic, K., Seltzer, M.
Proceedings of the 1999 FREENIX Conference, June, 1999, Monterey, CA.
databases, kvstore
Tickets and Currencies Revisted: Extensions to Multi-Resource Lottery Scheduling
Abstract
Lottery scheduling's ticket and currency abstractions provide a resource management framework that allows for both flexible allocation and insulation between groups of processes. We propose extensions to this framework that enable greater flexibility while preserving the ability to isolate groups of processes. In particular, we present a mechanism that allows processes to modify their own resource rights by exchanging resource-specific tickets with other processes. Ticket exchanges limit the effects of the changed allocations to the participants in the exchange, and they allow applications to coordinate with each other in ways that are mutually beneficial. Application-specific "negotiators" can be used to initiate exchanges based on an application's quality-of-service requirements and the current state of the system. We also propose flexible access controls for currencies through extensible "brokers" that solve such problems as the inability of users isolated by currencies to renice background jobs. Finally, we suggest using extensibility to allow users to install specialized allocation mechanisms for their processes. Together, these extensions enable an application-centered approach to resource management that is both secure and effective.
HTML
PDF
PostScript
Slides (PostScript)
Sullivan, D., Haas, R., Seltzer, M.
Proceedings of the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), March, 1999, Rio Rico, AZ.
os, scheduling
The Case for Application-Specific Benchmarking
Abstract
Most performance analysis today uses either microbenchmarks or standard macrobenchmarks (e.g., SPEC, LADDIS, the Andrew benchmark). However, the results of such benchmarks provide little information to indicate how well a particular system will handle a particular application. Such results are, at best, useless and, at worst, misleading. In this paper, we argue for an application-directed approach to benchmarking, using performance metrics that reflect the expected behavior of a particular application across a range of hardware or software platforms. We present three different approaches to application-specific measurement, one using vectors that characterize both the underlying system and an application, one using trace-driven techniques, and a hybrid approach. We argue that such techniques should become the new standard.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Seltzer, M., Krinsky, D., Smith, K., Zhang, X.
Proceedings of the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), March, 1999, Rio Rico, AZ.
benchmarking
Challenges in Embedded Database System Administration
Abstract
Database configuration and maintenance have historically been complex tasks, often requiring expert knowledge of database design and application behavior. In an embedded environment, it is not feasible to require such expertise and ongoing database maintenance. This paper discusses the database administration challenges posed by embedded systems and describes how the Berkeley DB architecture addresses these challenges.
HTML
Seltzer, M., Olson, M.
Proceedings of the 1999 USENIX Workshop on Embedded Systems, Cambridge, MA, March 1999.
databases
The ANT Architecture — An Architecture for CS1
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncracies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts. Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF
PostScript
Ellard, D. J., Ellard, P. A., Megquier, J. M., Chen, J. B., Seltzer, M. I.
The IEEE Computer Society Technical Committee on Computer Architecture Newsletter, February, 1999, 25–27.
architecture, education
1998
MiSFIT: Constructing Safe Extensible Systems
Abstract
The boundary between application and system is becoming increasingly permeable. Extensible applications, such as web browsers, database systems, and operating systems, demonstrate the value of allowing end-users to extend and modify the behavior of what was formerly considered to be a static, inviolate system. Unfortunately, flexibility often comes with a cost: systems unprotected from misbehaved end-user extensions are fragile and prone to instability.
Object-oriented programming models are a good fit for the development of this kind of system. An extension can be designed as a refinement to an existing class and loaded into a running system. In our model, when code is downloaded into the system, it is used to replace a virtual function on an existing C++ object. Because our tool is source-language-neutral, it can be used to build safe, extensible systems written in other languages as well.
There are three methods commonly used to make end-user extensions safe: restrict the extension language (e.g., Java), interpret the extension language (e.g., Tcl), or combine run-time checks with a trusted environment. The third technique is the one discussed here; it offers the twin benefits of the flexibility to implement extensions in an unsafe language, such as C++, and the performance of compiled code.
MiSFIT, the Minimal i386 Software Fault Isolation Tool, can be used as a component of a tool set for building safe extensible systems in C++. MiSFIT transforms C++ code, compiled by the Gnu C++ compiler, into safe binary code. Combined with a runtime support library, the overhead of MiSFIT is an order of magnitude lower than the overhead of interpreted Java, and permits safe extensible systems to be written in C++.
PDF
Small, C., Seltzer, M.
IEEE Concurrency, (6), 3, July–Sep 1998, 34–41.
operating systems, tools, pl
The Mug Shot Search
Abstract
Mug-shot search is the classic example of the general problem of searching a large facial image database when starting out with only a mental image of the sought-after face. We have implemented a prototype content-based image retrieval system that integrates composite face creation methods with a face-recognition technique (Eigenfaces) so that a user can both create faces and search for them automatically in a database.
Although the Eigenface method has been studied extensively for its ability to perform face identification tasks (in which the input to the system is an on-line facial image to identify), little research has been done to determine how effective it is when applied to the mug shot search problem (in which there is no on-line input image at the outset, and in which the task is similarity retrieval rather than face-recognition). With our prototype system, we have conducted a pilot user study that examines the usefulness of Eigenfaces applied to this problem. The study shows that the Eigenface method, though helpful, is an imperfect model of human perception of similarity between faces. Using a novel evaluation methodology, we have made progress at identifying specific search strategies that, given an imperfect correlation between the system and human similarity metrics, use whatever correlation does exist to the best advantage. The study also indicates that the use of facial composites as query images is advantageous compared to restricting users to database images for their queries.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Slides (PDF)
Baker, E., Seltzer, M.
Proceedings of the 1998 Vision Interfaces Conference, Vancouver, Canada, June 1998, 421–430.
algorithms, ui
The ANT Architecture — An Architecture for CS1
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncrasies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts.
PDF
PostScript
Ellard, D., Ellard, Pl, Megquier, J., Chen, JB, Seltzer, M.
Proceedings of the Workshop on Computer Architecture Education, 1998.
architecture, education
1997
Web Facts and Fantasy
Abstract
There is a great deal of research about improving Web server performance and building better, faster servers, but little research in characterizing servers and the load imposed upon them. While some tremendously popular and busy sites, such as netscape.com, playboy.com, and altavista.com, receive several million hits per day, most servers are never subjected to loads of this magnitude. This paper presents the analysis of internet Web server logs for a variety of different types of sites. We present a taxonomy of the different types of Web sites and characterize their access patterns and, more importantly, their growth. We then use our server logs to address some common perceptions about the Web. We show that, on a variety of sites, contrary to popular belief, the use of CGI does not appear to be increasing and that long latencies are not necessarily due to server loading. We then show that, as expected, persistent connections are generally useful, but that dynamic time-out intervals may be unnecessarily complex and that allowing multiple persistent connections per client may actually hinder resource utilization compared to allowing only a single persistent connection.
HTML
PDF
PostScript
Manley, S., Seltzer, M.
Proceedings of the Symposium on Internet Technologies and Systems, Monterey, CA, December 1997, 125-134.
networking, web
Measuring Windows NT — Possibilities and Limitations
Abstract
The majority of today's computing takes place on interactive systems that use a Graphical User Interface (GUI). Performance of these systems is unique in that "good performance" is a reflection of a user's perception. In this paper, we explain why this unique environment requires a new methodological aproach. We describe a measurement/diagnostic tool currently under development and evaluate the feasibility of implementing such a tool under Windows NT. We then present several issues that must be resolved in order for Windows NT to become a popular research platform for this type of work.
PDF
Endo, Y., Seltzer M.
Proceedings of the First USENIX Workshop on NT, Seattle, WA, August 1997.
benchmarking, operating systems
Operating System Benchmarking in the Wake of Lmbench: Case Study of the Performance of NetBSD on the Intel Architecture
Abstract
The lmbench suite of operating system microbenchmarks provides a set of portable programs for use in cross-platform comparisons. We have augmented the lmbench suite to increase its flexibility and precision, and to improve its methodological and statistical operation. This enables the detailed study of interactions between the operating system and the hardware architecture. We describe modifications to lmbench, and then use our new benchmark suite, hbench:OS, to examine how the performance of operating system primitives under NetBSD has scaled with the processor evolution of the Intel x86 architecture. Our analysis shows that off-chip memory system design continues to influence operating system performance in a significant way and that key design decisions (such as suboptimal choices of DRAM and cache technology, and memory-bus and cache coherency protocols) can essentially nullify the performance benefits of the aggressive execution core and sophisticated on-chip memory system of a modern processor such as the Intel Pentium Pro.
HTML
PDF
PostScript
Additional documentation
Brown, A., Seltzer, M.
Proceedings of the 1997 Sigmetrics Conference, Seattle, WA, June 1997, 214-224.
benchmarking, os
File System Aging
Abstract
Benchmarks are important because they provide a means for users and researchers to characterize how their workloads will perform on different systems and different system architectures. The field of file system design is no different from other areas of research in this regard, and a variety of file system benchmarks are in use, representing a wide range of the different user workloads that may be run on a file system. A realistic benchmark, however, is only one of the tools that is required in order to understand how a file system design will perform in the real world. The benchmark must also be executed on a realistic file system. While the simplest approach maybe to measure the performance of an empty file system, this represents a state that is seldom encountered by real users. In order to study file systems in more representative conditions, we present a methodology for aging a test file system by replaying a workload similar to that experienced by a real file system over a period of many months, or even years. Our aging tools allow the same aging workload to be applied to multiple versions of the same file system, allowing scientific evaluation of the relative merits of competing file system designs.
In addition to describing our aging tools, we demonstrate their use by applying them to evaluate two enhancements to the file layout policies of the UNIX fast file system.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Slides (PDF)
Smith, K., Seltzer, M.
Proceedings of the 1997 Sigmetrics Conference, Seattle, WA, June 1997, 203-213.
file systems
Self-Monitoring and Self-Adapting Operating Systems
Abstract
Extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. Extensibility enables a system to efficiently support a broader class of applications than is currently supported. This paper discusses the key challenge in making extensible systems practical: determining which parts of the system need to be extended and how. The determination of which parts of the system need to be extended requires self-monitoring, capturing a significant quantity of data about the performance of the system. Determining how to extend the system requires self-adaptation. In this paper, we describe how an extensible operating system (VINO) can use in situ simulation to explore the efficacy of policy changes. This automatic exploration is applicable to other extensible operating systems and can make these systems self-adapting to workload demands.
PDF
Slides (PDF)
Seltzer, M., Small, C.
Proceedings of the 1997 Workshop on Hot Operating Systems, Cape Cod, MA, May 5-6, 1997, 124-129.
operating systems
1996
Dealing with Disaster: Surviving Misbehaving Kernel Extensions
Abstract
Today's extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. The advantage of this approach is that it provides improved application flexibility and performance; the disadvantage is that buggy or malicious code can jeopardize the integrity of the kernel. It has been demonstrated that it is feasible to use safe languages, software fault isolation, or virtual memory protection to safeguard the main kernel. However, such protection mechanisms do not address the full range of problems, such as resource hoarding, that can arise when application code is introduced into the kernel.
In this paper, we present an analysis of extension mechanisms in the VINO kernel. VINO uses software fault isolation as its safety mechanism and a lightweight transaction system to cope with resource-hoarding. We explain how these two mechanisms are sufficient to protect against a large class of errant or malicious extensions, and we quantify the overhead that this protection introduces.
We find that while the overhead of these techniques is high relative to the cost of the extensions themselves, it is low relative to the benefits that extensibility brings.
HTML
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M., Endo, Y., Small, C., Smith, K.
Proceedings of the Second Symposium on Operating System Design and Implementation, Seattle, WA, October 1996, 213-227.
operating systems
Understanding Latency in GUI-based Applications
Endo, Y., Wang, Z., Chen, B., Seltzer, M.
Proceedings of the Second Symposium on Operating System Design and Implementation, Seattle, WA, October 1996, 195-199.
benchmarking, ui
Symbiotic System Software: Fast Operating Systems for Fast Applications
(PDF)
Seltzer., M., Small, C., Smith, M.
Proceedings of the First Workshop on Compiler Support for System Software, Tuscon, AZ, Feb 1996.
operating systems
World-Wide Web Cache Consistency
Abstract
The bandwidth demands of the World Wide Web continue to grow at a hyper-exponential rate. Given this rocketing growth, caching of web objects as a means to reduce network bandwidth consumption is likely to be a necessity in the very near future. Unfortunately, many Web caches do not satisfactorily maintain cache consistency. This paper presents a survey of contemporary cache consistency mechanisms in use on the Internet today and examines recent research in Web cache consistency. Using trace-driven simulation, we show that a weak cache consistency protocol (the one used in the Alex ftp cache) reduces network bandwidth consumption and server load more than either time-to-live fields or an invalidation protocol and can be tuned to return stale data less than 5% of the time.
PDF
PostScript
Gwertzman, J., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 141-152.
caching, web
Comparison of OS Extension Technologies
Abstract
The current trend in operating systems research is to allow applications to dynamically extend the kernel to improve application performance or extend functionality, but the most effective approach to extensibility remains unclear. Some systems use safe languages to permit code to be downloaded directly into the kernel; other systems provide in-kernel interpreters to execute extension code; still others use software techniques to ensure the safety of kernel extensions. The key characteristics that distinguish these systems are the philosophy behind extensibility and the technology used to implement extensibility. This paper presents a taxonomy of the types of extensions that might be desirable in an extensible operating system, evaluates the performance cost of various extension techniques currently being employed, and compares the cost of adding a kernel extension to the benefit of having the extension in the kernel. Our results show that compiled technologies (e.g. Modula-3 and software fault isolation) are good candidates for implementing general-purpose kernel extensions, but that the overhead of interpreted languages is sufficiently high that they are inappropriate for this use.
PDF
PostScript
Small, C., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 41-54.
operating systems, transactions
A Comparison of FFS Disk Allocation Policies
Abstract
The 4.4BSD file system includes a new algorithm for allocating disk blocks to files. The goal of this algorithm is to improve file clustering, increasing the amount of sequential I/O when reading or writing files, thereby improving file system performance. In this paper we study the effectiveness of this algorithm at reducing file system fragmentation. We have created a program that artificially ages a file system by replaying a workload similar to that experienced by a real file system. We used this program to evaluate the effectiveness of the new disk allocation algorithm by replaying ten months of activity on two file systems that differed only in the disk allocation algorithms that they used. At the end of the ten month simulation, the file system using the new allocation algorithm had approximately half the fragmentation of a similarly aged file system that used the traditional disk allocation algorithm. Measuring the performance difference between the two file systems by reading and writing the same set of files on the two systems showed that this decrease in fragmentation improved file write throughput by 20% and read throughput by 32%. In certain test cases, the new allocation algorithm provided a performance improvement of greater than 50%.
PDF
Supplementary Materials
Smith, K., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 15-26.
file systems
The Measured Performance of Personal Computer Operating Systems
Abstract
This paper presents a comparative study of the performance of three operating systems that run on the personal computer architecture derived from the IBM-PC. The operating systems, Windows for Workgroups (tm), Windows NT (tm), and NetBSD (a freely available UNIX (tm) variant) cover a broad range of system functionality and user requirements, from a single address space model to full protection with preemptive multi-tasking. Our measurements were enabled by hardware counters in Intel's Pentium (tm) processor that permit measurement of a broad range of processor events including instruction counts and on-chip cache miss counts. We used both microbenchmarks, which expose specific differences between the systems, and application workloads, which provide an indication of expected end-to-end performance. Our microbenchmark results show that accessing system functionality is often more expensive in Windows than in the other two systems due to frequent changes in machine mode and the use of system call hooks. When running native applications, Windows NT is more efficient than Windows, but it incurs overhead similar to that of a microkernel since its application interface(the Win32 API) is implemented as a user-level server. Overall, system functionality can be accessed most efficiently in NetBSD; we attribute this to its monolithic structure, and to the absence of the complications created by backwards compatibility in the other systems. Measurements of application performance show that although the impact of these differences is significant in terms of instruction counts and other hardware events (often a factor of 2 to 7 difference between the systems), overall performance is sometimes determined by the functionality provided by specific subsystems, such as the graphics subsystem or the file system buffer cache.
PDF
PostScript
Supplementary Materials
Transactions on Computer Systems version (PostScript)
Chen, B., Endo, Y., Chan, K., Mazieres, D., Dias, A., Seltzer, M., Smith, M.
Proceedings of the 15th ACM Symposium on Operating Systems Principles, Copper Mountain, Colorado, December 3-6, 1995. Also in ACM Transactions on Computer Systems, January 1996, 3-40.
benchmarking, operating systems
1995
Structuring the Kernel as a Toolkit of Extensible, Reusable Components
Abstract
Applications often require functionality that is implemented in the kernel, but is not directly available to the user level. While extensible operating systems allow kernel functionality to be augmented, we believe that the emphasis on extensibility is misplaced. Applications should be able to reuse kernel code directly and the emphasis should be placed on designing a kernel with that reuse in mind. The advantage of structuring the kernel as a set of reusable, extensible tools is that applications can avoid re-implementing functionality that is already present in the kernel. This will lead to smaller applications, fewer lines of total code, and a more unified computing environment that will be easier to maintain and perform better.
PDF
PostScript
Small, C., Seltzer, M.
Proceedings of the International Workshop on Object Orientation in Operating Systems, Lund, Sweden, August 1995, 134-137.
operating systems
The Case for Geographical Push-Caching
Abstract
Most existing wide-area caching schemes are client initiated. Decisions on when and where to cache information are made without the benefit of the server's global knowledge of the situation. We believe that the server should play a role in making these caching decisions, and we propose geographical push-caching as a way of bringing the server back into the loop. The World Wide Web is an excellent example of a wide-area system that will benefit from geographical push-caching, and we present an architecture that allows a Web server to autonomously replicate HTML pages.
PDF
PostScript
Gwertzman, J., Seltzer., M.
Proceedings of the Fifth Annual Workshop on Hot Operating Systems, Orcas Island, WA, May 1995, 51-55.
caching, web
File System Logging versus Clustering: A Performance Comparison
Abstract
The Log-structured File System (LFS), introduced in 1991, has received much attention for its potential order-of-magnitude improvement in file system performance. Early research results showed that small file performance could scale with processor speed and that cleaning costs could be kept low, allowing LFS to write at an effective bandwidth of 62 to 83% of the maximum. Later work showed that the presence of synchronous disk operations could degrade performance by as much as 62% and that cleaning overhead could become prohibitive in transaction processing workloads, reducing performance by as much as 40%. The same work showed that the addition of clustered reads and writes in the Berkeley Fast File System (FFS) made it competitive with LFS in large-file handling and software development environments as approximated by the Andrew benchmark.
These seemingly inconsistent results have caused confusion in the file system research community. This paper presents a detailed performance comparison of the 4.4BSD Log-structured File system and the 4.4BSD Fast File System. Ignoring cleaner overhead, our results show that the order-of-magnitude improvement in performance claimed for LFS applies only to meta-data intensive activities, specifically the creation of files one-kilobyte or less and deletion of files 64 kilobytes or less.
For small files, both systems provide comparable read performance, but LFS offers superior performance on writes. For large files (one megabyte and larger), the performance of the two file systems is comparable. When FFS is tuned for writing, its large-file write performance is approximately 15% better than LFS, but its write performance is 25% worse. When FFS is optimized for reading, its large-file read and write performance is comparable to LFS.
Both LFS and FFS can suffer performance degradation, due to cleaning and disk fragmentation respectively. We find that active FFS file systems function at approximately 85-95% of their maximum performance after two to three years. We examine LFS cleaner performance in a transaction-processing environment and find that cleaner overhead reduces LFS performance by more than 33% when the disk is 50% full.
PDF
PostScript
Supplementary Materials
Seltzer, M., Smith, K., Balakrishnan, H., Chang, J., McMains, S., Padmanabhan, V.
Proceedings of the 1995 Winter USENIX Technical Conference, New Orleans, LA, January 1995, 249-264.
file systems, benchmarking
Heuristic Cleaning Algorithms for Log-Structured File Systems
Abstract
Research results show that while Log-Structured File Systems (LFS) offer the potential for dramatically improved file system performance, the cleaner can seriously degrade performance, by as much as 40% in transaction processing workloads. Our goal is to examine trace data from live file systems and use those to derive simple heuristics that will permit the cleaner to run without interfering with normal file access. Our results show that trivial heuristics perform very well, allowing 97% of all cleaning on the most heavily loaded system we studied to be done in the background.
PDF
PostScript
Blackwell, T., Harris., J., Seltzer, M.
Proceedings of the 1995 Winter USENIX Technical Conference, New Orleans, LA, January 1995, 277-288.
algorithms, file systems
1994
An Experimental Flow Controlled Multicast ATM Switch
(PDF)
Blackwell, T., Chan, K., Chang, K., Charuhas, T., Karp, B., Kung, H. T., Lin, D., Morris, R., Seltzer, M., Smith, M., Young, C., Bahgat, O., Chaar, M., Chapman, A., Depelteau, G., Grimble, K., Huang, S., Hung, P., Kemp, M., McLaughlin, I., Ng, T., Vincent, J., and Watchor, J.
Proceedings of the First Annual Conference on Telecommunications Research and Development in Massachusetts, Vol. 6, October 1994, 33-38.
networking
Evolving Line Drawings
Abstract
This paper explores the application of interactive genetic algorithms to the creation of line drawings. We have built a system that mates or mutates drawings selected by the user to create a new generation of drawings. The initial population from which the user makes selections may be generated randomly or input manually. The process of selection and procreation is repeated many times to evolve a drawing. A wide variety of complex sketches with highlighting and shading can be evolved from very simple drawings. This technique has potential for augmenting and enhancing the power of traditional computer-aided drawing tools, and for expanding the repertoire of the computer-assisted artist.
HTML
PDF
PostScript
Slides (HTML)
Slides (PDF)
Baker, E., Seltzer, M.
Proceedings of Graphics Interface ’94, Banff, Canada, May 1994, 91-100.
visualization, algorithms
1993
Transaction Support in a Log-Structured File System
Abstract
Transaction Support in a Log-Structured File System
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M.
Proceedings of the Ninth International Conference on Data Engineering, Vienna, Austria, April 1993, 503-510.
file systems, transactions
An Implementation of a Log-Structured File System for UNIX
Abstract
Research results demonstrate that a log-structured file system offers the potential for dramatically improved write performance, faster recovery time, and faster file creation and deletion than traditional UNIX file systems. This paper presents a redesign and implementation of the Sprite log-structured file system that is more robust and integrated into the vnode interface. Measurements show its performance to be superior to the 4BSD Fast File System in a variety of benchmarks and not significantly less than FFS in any test. Unfortunately, an enhanced version of FFS (with read and write clustering) provides comparable and sometimes superior performance to our LFS. However, LFS can be extended to provide additional functionality such as embedded transactions and versioning, not easily implemented in traditional file systems.
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M., Bostic, K., McKusick., M., Staelin, C.
Proceedings of the 1993 Winter USENIX Conference, San Diego, CA January 1993, 307-326.
file systems
1992
File System Performance and Transaction Support
(PDF)
Seltzer, M.,
Ph.D. Dissertation, University of California, Berkeley, December 1992.
file system, transaction support, read-optimized, write-optimized, log-structured file system
Non-Volatile Memory for Fast, Reliable File Systems
Abstract
Given the decreasing cost of non-volatile RAM (NVRAM), by the late 1990's it will be feasible for most workstations to include a megabyte or more of NVRAM, enabling the design of higher-performance, more reliable systems. We present the trace-driven simulation and analysis of two uses of NVRAM to improve I/O performance in distributed file systems: non-volatile file caches on client workstations to reduce write traffic to file servers, and write buffers for write-optimized file systems to reduce server disk accesses. Our results show that a megabyte of NVRAM on diskless clients reduces the amount of file data written to the server by 40 to 50%. Increasing the amount of NVRAM shows rapidly diminishing returns, and the particular NVRAM block replacement policy makes little difference to write traffic. Closely integrating the NVRAM with the volatile cache provides the best total traffic reduction. At today's prices, volatile memory provides a better performance improvement per dollar than NVRAM for client caching, but as volatile cache sizes increase and NVRAM becomes cheaper, NVRAM will become cost effective. On the server side, providing a one-half megabyte write-buffer per file system reduces disk accesses by about 20% on most of the measured log-structured file systems (LFS), and by 90% on one heavily-used file system that includes transaction-processing workloads.
PDF
PostScript
Baker, M., Asami, S., Deprit, E., Ousterhout, J., Seltzer, M.
Proceedings of ASPLOS-V, Boston, MA, October 1992, 10-22.
file systems, nvm
LIBTP: Portable, Modular Transactions for UNIX
Abstract
Transactions provide a useful programming paradigm for maintaining logical consistency, arbitrating concurrent access, and managing recovery. In traditional UNIX systems, the only easy way of using transactions is to purchase a database system. Such systems are often slow, costly, and may not provide the exact functionality desired. This paper presents the design, implementation, and performance of LIBTP, a simple, non-proprietary transaction library using the 4.4BSD database access routines (db(3)). On a conventional transaction processing style benchmark, its performance is approximately 85% that of the database access routines without transaction protection, 200% of that using fsync(2) to commit modifications to disk, and 125% that of a commercial relational database system.
PDF
PostScript
Seltzer, M., Olson, M.
Proceedings 1992 Winter USENIX Conference, San Francisco, CA, January 1992, 9-26.
databases, transactions
1991
Read Optimized File Systems: A Performance Evaluation
Abstract
This paper presents a performance comparison of several file system allocation policies. The file systems are designed to provide high bandwidth between disks and main memory by taking advantage of parallelism in an underlying disk array, cateringv to large units of transfer, and minimizing the bandwidth dedicated to the transfer of meta data. All of the file systems described use a multiblock allocation strategy that allows both large and small files to be allocated efficiently. Simulation results show that these multiblock policies result in systems that are able to utilize a large percentage of the underlying disk bandwidth; more than 90% in sequential cases. As general purpose systems are called upon to support more data intensive applications such as databases and supercomputing, these policies offer an opportunity to provide superior performance to a larger class of users.
PDF
PostScript
Seltzer, M., Stonebraker, M.
Proceedings 7th Annual International Conference on Data Engineering, Kobe, Japan, April 1991, 602-611.
file systems, benchmarking
A New Hashing Package for UNIX
Abstract
UNIX support of disk oriented hashing was originally provided by dbm [ATI79] and subsequently improved upon in ndbm [BSD86]. In AT&T System V, in-memory hashed storage and access support was added in the hsearch library routines [ATT85]. The result is a system with two incompatible hashing schemes, each with its own set of shortcomings. This paper presents the design and performance characteristics of a new hashing package providing a superset of the functionality provided by dbm and hsearch. The new package uses linear hashing to provide efficient support of both memory based and disk based hash tables with performance superior to both dbm and hsearch under most conditions.
PDF
PostScript
Seltzer, M., Yigit, O.
Proceedings 1991 Winter USENIX Conference, Dallas, TX, January 1991, 173-184.
algorithms, data structures
1990
Transaction Support in Read Optimized and Write Optimized File Systems
Abstract
This paper provides a comparative analysis of five implementations of transaction support. The first of the methods is the traditional approach of implementing transaction processing within a data manager on top of a read optimized file system. The second also assumes a traditional file system but embeds transaction support inside the file system. The third model considers a traditional data manager on top of a write optimized file system. The last two models both embed transaction support inside a write optimized file system, each using a different logging mechanism. Our results show that in a transaction processing environment, a write optimized file system often yields better performance than one optimized for reads. In addition, we show that file system embedded transaction managers can perform as well as data managers when transaction throughput is limited by I/O bandwidth. Finally, even when the CPU is the critical resource, the difference in performance between a data manager and an embedded system is much smaller than previous work has shown.
PDF
PostScript
Seltzer, M., Stonebraker, M.
Proceedings 16th International Conference on Very Large Data Bases, Brisbane, Australia, August 1990, 174-185.
file systems, transactions
Disk Scheduling Revisited
Abstract
Since the invention of the movable head disk, people have improved I/O performance by intelligent scheduling of disk accesses. We have applied these techniques to systems with large memories and potentially long disk queues. By viewing the entire buffer cache as a write buffer, we can improve disk bandwidth utilization by applying some traditional disk scheduling techniques. We have analyzed these techniques, which attempt to optimize head movement and guarantee fairness in response time, in the presence of long disk queues. We then propose two algorithms which take rotational latency into account, achieving disk bandwidth utilizations of nearly four times a simple first come first serve algorithm. One of these two algorithms, a weighted shortest total time first, is particularly applicable to a file server environment because it guarantees that all requests get to disk within a specified time window.
PDF
PostScript
Seltzer, M., Chen, P., Ousterhout, J.
Proceedings 1990 Winter USENIX Conference, Washington, D.C., January 1990, 313-324.
storage
Patterns
R, provenance, data provenance, data science
Rclean: A Tool for Writing Cleaner, More Transparent Code (PDF)
Lau, M., Pasquier T., Seltzer, M.,
JOSS: The Journal of Open Source Software
R, provenance, data provenance, data science, statistical analysis
A user-centered, learning asthma smartphone application for patients and providers (PDF)
Gaynor, M., Schneider, D., Seltzer, M., Crannage, E., Barron, M., Waterman, J., Oberle, A.,
Learning Health Systems
user-centered design, health, asthma, health app
Unicorn: Runtime Provenance-Based Detector for Advanced Persistent Threats (PDF)
Han, X., Pasquier, T., Bates, A., Mickens, J., Seltzer, M.,
Network and Distributed System Security Symposium (NDSS)
provenance, intrusion detection, CamFlow, machine learning
Improving Data Scientist Efficiency with Provenance (PDF)
Hu, J., Joung, J., Jacobs, M., Gajos, K., Seltzer, M.,
International Conference on Software Engineering
provenance, data science, noWorkflow, incremental execution
2019
Optimal Sparse Decision Trees (PDF)
Hu, X., Rudin, C., Seltzer, M.,
Conference on Neural Information Processing Systems (NeurIPS)
decision trees, interpretable machine learning, machine learning
ProvMark: A provenance expressiveness benchmarking system (PDF)
Chan, S., Cheney, J., Bhatotia, P., Pasquier, T., Gehani, A., Irshad, H., Carata, L., Seltzer, M.,
International Middleware Conference
provenance, benchmarking, CamFlow
Trials and Tribulations in Synthesizing Operating Systems (PDF)
Hu, J., Lu, E., Holland, D., Kawaguchi, M., Chong, S., Seltzer, M.,
Workshop on Programing Languages and Operating Systems (co-located with SOSP)
program synthesis, operating systems
Visonpaper -- From Here to Provtopia (PDF)
Pasquier, T., Eyers, D., Seltzer, M.,
Towards Polystores that manage multiple Databases, Privacy, Security and/or Policy Issues for Heterogenous Data (POLY, co-located with VLDB 2019)</h5
provenance, compliance, GDPR
2018
Incentivizing Deep Fixes in Software Economies
(PDF)
Rao, M., Bacon, D.F., Parkes, D., Seltzer, M.
IEEE Transactions on Software Engineering. (June 2018, 21 pages) doi: 10.1109/TSE.2018.2842188
software engineering, bug fixing, econCS
Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using CrossReferencing Logs
(PDF)
Huang, Y., Pavlovic, M., Marathe, V., Seltzer, M., Harris, T., Byan, S.
Proceedings of the 2018 USENIX Annual Technical Conference, Boston MA, June 2018.
key value store, NVM, logging, logs
Sharing and Preserving Computational Analyses for Posterity with encapsulator
(PDF)
Pasquier, T., Lau, M., Han, X., Fong, E., Lerner, B., Boose, E., Crosas, M., Ellison, A., Seltzer, M.
IEEE Computing in Science and Engineering 20(111), July 2018. doi: or,” IEEE Computing in Science and Engineering 20(111), July 2018. doi: 10
provenance, reproducibility
Provenance-based Intrusion Detection: Opportunities
and Challenges
(PDF)
Han, X., Pasquier, T., Seltzer, M.
Proceedings of the Workshop on the Theory and Practice of Provenance (TaPP 2018), London UK, July 2018
provenance, intrusion detection, machine learning
Runtime Analysis of Whole-System Provenance
(PDF)
Pasquier, T., Han, X., Moyer, T., Bates, A., Hermant, O., Eyers, D., Bacon, J., Seltzer, M.
Proceedings of the 2018 Conference on Computer and Communications Security
(CCS '18), Toronto CA, October 2018.
camflow, provenance, data integrity
Learning Certifiably Optimal Rule Lists for Categorical Data
(PDF)
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M., Rudin, C.
Journal of Machine Learning Research 18 (2018) 1-78.
optimization, rule lists, machine learning, data structures
2017
Practical Whole-System Provenance Capture
(PDF)
Pasquier, T., Han, X., Goldstein, M., Moyer, T., Eyers, D., Seltzer, M., and Bacon, J., 2017.
Proceedings of SoCC ’17, Santa Clara, CA, USA, September 24–27, 2017.
provenance, camflow, os
Learning Certifiably Optimal Rule Lists
(PDF)
(video)
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M., Rudin, C.
Proceedings of the 23rd ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining (KDD), August 2017, 35-44.
optimization, rule lists, machine learning, data structures
If these data could talk
(PDF)
Pasquier, T., Lau, M., Trisovic, A., Boose, E., Couturier, B., Crosas, M., Ellison, A., Gibson, V., Jones, C., and Seltzer, M.
Nature Scientific Data, vol. 4, 2017.
provenance, reproducibility
Data Provenance to Audit Compliance with Privacy Policy
(PDF)
Pasquier, T., Singh, J., Powles, J., Eyers, D., Seltzer, M., Bacon, J.
Internet of Things, Journal of Personal and Ubiquitous Computing, published online Aug. 15, 2017.
provenance, privacy, compliance
Scalable Bayesian Rule Lists
(PDF)
Yang, H., Rudin, C., Seltzer, M.
Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, PMLR 70, 2017.
algorithms, rule lists, machine learning, mcmc
FRAPpuccino: Fault-detection through Runtime Analysis of Provenance
(PDF)
Han, X., Pasquier, T., Ranjan, T., Goldstein, M., and Seltzer, M.
Proceedings of the Workshop on Hot Topics in Cloud Computing (HotCloud’17), USENIX Association, Santa Clara, CA, July 2017.
provenance, fault detection, intrusion detection, security
Persistent Memcached: Bringing Legacy Code to Byte-Addressable Persistent Memory
(PDF)
Marathe, V., Seltzer, M., Byan, S., Harris, T.
Proceedings of USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 17) USENIX Association, Santa Clara, CA, July 2017.
persistent memory, nvm, storage, kvstore
A Crowdsourcing Approach to Collecting Tutorial Videos — Toward Personalized Learning-at-Scale
(PDF)
Whitehill, J., Seltzer, M.
Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale (L@S)
education
Sorting Shapes the Performance of Graph-Structured Systems
(PDF)
Daniel Wyatt Margo
Ph.D. Dissertation, Harvard John A. Paulson School of Engineering and Applied Sciences, March 27, 2017.
graphs, partitioning, performance, kronecker
2015
Towards General-Purpose Neural Network Computing
(PDF)
Eldridge, S., Appavoo, J., Joshi, A., Waterland, A., Seltzer, M.
Proceedings of the 13th International Conference on Parallel
Architectures and Compilation Techniques (PACT 2015), Petrozavodsk Russia, September 2015.
ASC, automatically scalable computing, neural networks
Recent advances in computer architecture: the opportunities and challenges for provenance.
(PDF)
Balakrishnan, Nikilesh, Thomas Bytheway, Lucian Carata, Oliver RA Chick, James Snee, Sherif Akoush, Ripduman Sohan, Margo Seltzer, and Andy Hopper
7th USENIX Workshop on the Theory and Practice of Provenance (TaPP 15). 2015.
provenance, architecture
A Scalable Distributed Graph Partitioner
(PDF)
Margo, D., Seltzer, M
Proceedings of the 41st International Conference on Very Large Data Bases, Kohala Coast, Hawaii, August 2015, pp 1478-1489.
graphs, algorithms
LLAMA: Efficient Graph Analytics Using Large Multiversioned Arrays
(PDF)
Macko, P., Margo, D., Marathe, V., Seltzer, M.
Proceedings of the 31st IEEE International Conference on Data Engineering (ICDE 2015), Seoul Korea, April 2015.
graphs, algorithms, data structures, storage
2014
Accelerating MCMC via parallel predictive prefetching
(PDF)
Angelino, E., Kohler, E., Waterland, A., Seltzer, M., Adams, M.
Proceedings of the 2014 Conference on Uncertainty in Artificial Intelligence (UAI '14), Quebec City, Quebec Canada, July 2014.
algorithms, mcmc, asc
Proceedings of the AAAI 2014 Workshop on Incentives and Trust in E-Communities (WIT-EC'14)
(PDF)
Rao, M., Parkes, D., Seltzer, M., and Bacon, D.
Quebec City, Quebec Canada, July 2014.
incentives, econcs
Programmable Smart Machines: A Hybrid Neuromorphic approach to General Purpose Computation
(PDF)
Appavoo, J., Waterland, A., Eldridge, S., Zhao, K,. Joshi, A, Homer, S, Seltzer, M.
Proceedings of the first workshop on Neuromorphic Architectures
(NeuroArch) collocated with ISCA, June 2014.
ASC, automatically scalable computation, neuromorphic
A Primer on Provenance
(PDF)
Carata, L, Akoush, S., Balakrishnan, N., Bytheway, T., Sohan, R., Seltzer, M., Hopper, A.
ACM Queue 12(3), April 2014.
provenance
ASC: Automatically Scalable Computation
(PDF)
Waterland, A., Angelino, E., Adams, R., Appavoo, J., Seltzer, M.
Proceedings of the 2014 Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '14) (IEEE Top Pick), Salt Lake City Utah, March 2014.
ASC, automatically scalable computation, architecture, machine learning, parallelization, dynamical system
2013
Applying KISS to Healthcare Information Technology
(PDF)
Herzlinger, R., Seltzer, M., Gaynor, M.
Computer 46(11), IEEE, November 2013, 72--74.
healthcare technology
Evaluation of Filesystem Provenance Visualization Tools
Borkin, M., Yeh, C., Boyd, M., Macko, P., Gajos, K., Seltzer, M., Pfister, H.
Proceedings of the 2013 International Conference on Information Visualization (Vis 2013), Atlanta GA, October 2013.
provenance, visualization
Local Clustering in Provenance Graphs
(PDF)
Macko, P., Margo, D., Seltzer, M.
Proceedings of the 2013 International Conference on Information and Knowledge Management (CIKM 2013), Burlingame CA, October 2013.
provenance, algorithms, metrics
Performance Introspection of Graph Databases
Abstract
The explosion of graph data in social and biological networks, recommendation systems, provenance databases, etc. makes graph storage and processing of paramount importance. We present a performance introspection framework for graph databases, PIG, which provides both a toolset and methodology for understanding graph database performance. PIG consists of a hierarchical collection of benchmarks that compose to produce performance models; the models provide a way to illuminate the strengths and weaknesses of a particular implementation. The suite has three layers of benchmarks: primitive operations, composite access patterns, and graph algorithms. While the framework could be used to compare different graph database systems, its primary goal is to help explain the observed performance of a particular system. Such introspection allows one to evaluate the degree to which systems exploit their knowledge of graph access patterns. We present both the PIG methodology and infrastructure and then demonstrate its efficacy by analyzing the popular Neo4j and DEX graph databases.
PDF
Slides (PDF)
Macko, P., Margo, D., Seltzer, M.
Proceedings of the 2013 SYSTOR Conference, Haifa Israel, July 2013.
graphs, benchmarking
Computational Caches
Abstract
Caching is a well-known technique for speeding up computation. We cache data from file systems and databases; we cache dynamically generated code blocks; we cache page translations in TLBs. We propose to cache the act of computation, so that we can apply it later and in different contexts. We use a state-space model of computation to support such caching, involving two interrelated parts: speculatively memoized predicted/resultant state pairs that we use to accelerate sequential computation, and trained probabilistic models that we use to generate predicted states from which to speculatively execute. The key techniques that make this approach feasible are designing probabilistic models that automatically focus on regions of program execution state space in which prediction is tractable and identifying state space equivalence classes so that predictions need not be exact.
PDF
Slides (PDF)
Waterland, A., Angelino, E., Cubuk, E., Kaziras, E., Adams, R., Appavoo, J., Seltzer, M.
Proceedings of the 2013 SYSTOR Conference, Haifa Israel, July 2013.
asc, caching
Flash Caching on the Storage Client
Abstract
Flash memory has recently become popular as a caching medium. Most uses to date are on the storage server side. We investigate a different structure: flash as a cache on the client side of a networked storage environment. We use trace-driven simulation to explore the design space. We consider a wide range of configurations and policies to determine the potential client-side caches might offer and how best to arrange them.
Our results show that the flash cache writeback policy does not significantly affect performance. Write-through is sufficient; this greatly simplifies cache consistency handling. We also find that the chief benefit of the flash cache is its size, not its persistence. Cache persistence of- fers additional performance benefits at system restart at essentially no runtime cost. Finally, for some workloads a large flash cache allows using miniscule amounts of RAM for file caching (e.g., 256 KB) leaving more mem- ory available for application use.
PDF
Slides (PDF)
Holland, D., Angelino, E., Wald, G., Seltzer, M.
Proceedings of the 2013 USENIX Annual Technical Conference, San Jose, CA, June 2013.
caching, storage, nvm
2012
2011
A General-Purpose Provenance Library
Abstract
Most provenance capture takes place inside particular tools – a workflow engine, a database, an operating system, or an application. However, most users have an existing toolset – a collection of different tools that work well for their needs and with which they are comfortable. Currently, such users have limited ability to collect provenance without disrupting their work and changing environments, which most users are hesitant to do. Even users who are willing to adopt new tools, may realize limited benefit from provenance in those tools if they do not integrate with their entire environment, which may include multiple languages and frameworks.
We present the Core Provenance Library (CPL), a portable, multi-lingual library that application programmers can easily incorporate into a variety of tools to collect and integrate provenance. Although the manual instrumentation adds extra work for application programmers, we show that in most cases, the work is minimal, and the resulting system solves several problems that plague more constrained provenance collection systems.
PDF
Slides (PDF)
Macko, P., Seltzer, M.
Proceedings of the Fourth Workshop on the Theory and Practice of Provenance (TaPP 2012), Boston MA, June 2012.
provenance, software
Provenance Integration Requires Reconciliation
Abstract
While there has been a great deal of research on provenance systems, there has been little discussion about challenges that arise when making different provenance systems interoperate. In fact, most of the literature focuses on provenance systems in isolation and does not discuss interoperability – what it means, its requirements, and how to achieve it. We designed the Provenance-Aware Storage System to be a general- purpose substrate on top of which it would be “easy” to add other provenance-aware systems in a way that would provide “seamless integration” for the provenance captured at each level. While the system did exactly what we wanted on toy problems, when we began integrating StarFlow, a Python-based workflow/provenance system, we discovered that integration is far trickier and more subtle than anyone has suggested in the literature. This work describes our experience undertaking the integration of StarFlow and PASS, identifying several important additions to existing provenance models necessary for interoperability among provenance systems.
PDF
Slides (PDF)
Angelino, E., Braun, U., Holland, D., Macko, P., Margo, D., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance
Provenance Map Orbiter: Interactive Exploration of Large Provenance Graphs
Abstract
Provenance systems can produce enormous provenance graphs that can be used for a variety of tasks from deter- mining the inputs to a particular process to debugging entire workflow executions or tracking difficult-to-find dependencies. Visualization can be a useful tool to sup- port such tasks, but graphs of such scale (thousands to millions of nodes) are notoriously difficult to visualize. This paper presents the Provenance Map Orbiter, a tool for interactively exploring large provenance graphs using graph summarization and semantic zoom. It presents its users with a high-level abstracted view of the graph and the ability to incrementally drill down to the details.
PDF
Macko, P., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance, graphs, visualization
Collecting Provenance via the Xen Hypervisor
Abstract
The Provenance Aware Storage Systems project (PASS) currently collects system-level provenance by intercepting system calls in the Linux kernel and storing the provenance in a stackable filesystem. While this approach is reasonably efficient, it suffers from two significant drawbacks: each new revision of the kernel requires reintegration of PASS changes, the stability of which must be continually tested; also, the use of a stackable filesystem makes it difficult to collect provenance on root volumes, especially during early boot. In this paper we describe an approach to collecting system-level provenance from virtual guest machines running under the Xen hypervisor. We make the case that our approach alleviates the aforementioned difficulties and promotes adoption of provenance collection within cloud comput- ing platforms.
PDF
Slides (PDF)
Macko, P., Chiarini, M., Seltzer, M.
Proceedings of the Third Workshop on the Theory and Practice of Provenance (TaPP 2011), Heraklion Greece, June 2011.
provenance, virtualization
Dimetrodon: Processor-level Preventive Thermal Management via Idle Cycle Injection
Abstract
Processor-level dynamic thermal management techniques have long targeted worst-case thermal margins. We examine the thermal-performance trade-offs in average-case, preventive thermal management by actively degrading application performance to achieve long-term thermal control. We propose Dimetrodon, the use of idle cycle injection, a flexible, per-thread technique, as a preventive thermal management mechanism and demonstrate its efficiency compared to hardware techniques in a commodity operating system on real hardware under throughput and latency-sensitive real-world workloads. Compared to hardware techniques that also lack flexibility, Dimetrodon achieves favorable trade-offs for temperature reductions up to 30% due to rapid heat dissipation during short idle intervals.
PDF
Peter Bailis, Vijay Janapa Reddi, Sanjay Gandhi, David Brooks, and Margo Seltzer
Proceeeding of the 2011 Design Automation Conference (DAC 2011), San Diego, CA, June 2011. Seltzer
architecture, scheduling, energy
Benchmarking File System Benchmarking: It *IS* Rocket Science
Abstract
The quality of file system benchmarking has not improved in over a decade of intense research spanning hundreds of publications. Researchers repeatedly use a wide range of poorly designed benchmarks, and in most cases, develop their own ad-hoc benchmarks. Our community lacks a definition of what we want to benchmark in a file system. We propose several dimensions of file system benchmarking and review the wide range of tools and techniques in widespread use. We experimentally show that even the simplest of benchmarks can be fragile, producing performance results spanning orders of magnitude. It is our hope that this paper will spur serious debate in our community, leading to action that can improve how we evaluate our file and storage systems.
PDF
Vasiliy Tarasov, Saumitra Hanage, Erez Zadok, Margo Seltzer
Proceedings of the 2011 Workshop on Hot Topics in Operating Systems (HOTOS XIII), Napa, CA, May 2011.
file systems, benchmarking, storage
Multicore OSes: Looking Forward from 1991, er, 2011
Abstract
Upcoming multicore processors, with hundreds of cores or more in a single chip, require a degree of parallel scalability that is not currently available in today’s system software. Based on prior experience in the supercomputing sector, the likely trend for multicore processors is away from shared memory and toward sharednothing architectures based on message passing. In light of this, the lightweight messages and channels programming model, found among other places in Erlang, is likely the best way forward. This paper discusses what adopting this model entails, describes the architecture of an OS based on this model, and outlines a few likely implementation challenges.
PDF
Slides (PDF)
David Holland, Margo Seltzer
Proceedings of the 2011 Workshop on Hot Topics in Operating Systems (HOTOS XIII), Napa, CA, May 2011.
os, operating systems
Mining the Web for Medical Hypotheses: A Proof-of-Concept System
Abstract
As the prevalence of blogs, discussion forums, and online news services continues to grow, so too does the portion of this Web content that relates to health and medicine. We propose that everyday, medically-oriented Web content is a valuable and viable data source for medical hypothesis generation and testing, despite its being noisy. In this paper, we present a proof-of-concept system supporting this notion. We construct a corpus comprising news articles relating to the drugs Vioxx, Naproxen and Ibuprofen, that were published between 1998-2002. Using this corpus, we show that there was a significant link between Vioxx and the concept “Myocardial Infarction” well before the drug was withdrawn from the market in 2004. Indeed, within the Vioxx-related content, the concept ranks amongst the top 3.3% in terms of importance. When compared with the Naproxen and Ibuprofen control literatures, the term occurs significantly more frequently in the Vioxx- related content.
PDF
Diana Maclean, Margo Seltzer
Proceedings of the International Conference on Health Informatics, Rome Italy, January 2011.
medical, data mining
2010
Tracking Back References in a Write-Anywhere File System
Abstract
Many file systems reorganize data on disk, for example to defragment storage, shrink volumes, or migrate data between different classes of storage. Advanced file system features such as snapshots, writable clones, and deduplication make these tasks complicated, as moving a single block may require finding and updating dozens, or even hundreds, of pointers to it.
We present Backlog, an efficient implementation of explicit back references, to address this problem. Back references are file system meta-data that map physical block numbers to the data objects that use them. We show that by using LSM-Trees and exploiting the write-anywhere behavior of modern file systems such as NetApp R WAFL R or btrfs, we can maintain back reference meta-data with minimal overhead (one extra disk I/O per 102 block operations) and provide excel- lent query performance for the common case of queries covering ranges of physically adjacent blocks.
PDF
Peter Macko, Margo Seltzer, Keith A. Smith
Proceedings of the 8th Conference on File and Storage Technologies (FAST'10), San Jose, CA, February 2010.
storage, file systems
Provenance for the Cloud
Abstract
The cloud is poised to become the next computing environment for both data storage and computation due to its pay-as-you-go and provision-as-you-go models. Cloud storage is already being used to back up desktop user data, host shared scientific data, store web application data, and to serve web pages. Today's cloud stores, however, are missing an important ingredient: provenance.
Provenance is metadata that describes the history of an object. We make the case that provenance is crucial for data stored on the cloud and identify the properties of provenance that enable its utility. We then examine current cloud offerings and design and implement three protocols for maintaining data/provenance in current cloud stores. The protocols represent different points in the de- sign space and satisfy different subsets of the provenance properties. Our evaluation indicates that the overheads of all three protocols are comparable to each other and reasonable in absolute terms. Thus, one can select a protocol based upon the properties it provides without sacrificing performance. While it is feasible to provide provenance as a layer on top of today's cloud offerings, we conclude by presenting the case for incorporating provenance as a core cloud feature, discussing the issues in doing so.
PDF
Kira-Kumar Muniswamy-Reddy, Peter Macko, Margo Seltzer
Proceedings of the 8th Conference on File and Storage Technologies (FAST'10), San Jose, CA, February 2010.
cloud, provenance
Towards Query Interoperability: PASSing PLUS
Abstract
We describe our experiences importing PASS provenance into PLUS. Although both systems import and export provenance that conforms to the Open Provenance Model (OPM), the two systems vary greatly with respect to the granularity of provenance captured, how much semantic knowledge the system contributes, and the completeness of provenance capture. We encountered several problems reconciling provenance between the two systems and use that experience to specify a Common Provenance Framework, that provides a higher degree of interoperability between provenance systems. In each case, the problems stem from the fact that OPM interoperability is a weaker requirement than query interoperability. Our goal in presenting this work is to generate discussion about differing degrees of interoperability and the requirements thereof.
PDF
Slides (PDF)
Uri Braun, Margo Seltzer, Adriane Chapman, Barbara Blaustein, M. David Allen, Len Seligman
Proceedings of the 2nd Workshop on the Theory and Practice of Provenance (TaPP'10) San Jose, CA, February 2010.
provenance
Provenance as first class cloud data
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Muniswamy-Reddy, K. and Seltzer, M.
Operating Systems Review, ACM 43, 4 (Jan. 2010), 11-16.
provenance, cloud
2009
Provenance: a future history.
Abstract
Science, industry, and society are being revolutionized by radical new capabilities for information sharing, distributed computation, and collaboration offered by the World Wide Web. This revolution promises dramatic benefits but also poses serious risks due to the fluid nature of digital information. One important cross-cutting issue is managing and recording provenance, or metadata about the origin, context, or history of data. We posit that provenance will play a central role in emerging advanced digital infrastructures. In this paper, we outline the current state of provenance research and practice, identify hard open research problems involving provenance semantics, formal modeling, and security, and articulate a vision for the future of provenance.
PDF
Cheney, J., Chong, S., Foster, N., Seltzer, M., and Vansummeren, S.
Proceeding of the 24th ACM SIGPLAN Conference Companion on Object Oriented Programming Systems Languages and Applications (Orlando, Florida, USA, October 25 - 29, 2009). OOPSLA '09. ACM, New York, NY, 957-964.
provenance
Provenance as First-Class Cloud Data
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Muniswamy-Reddy, K., Seltzer, M.
3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (LADIS'09), October 2009.
provenance, cloud
Layering in Provenance Systems
Abstract
Digital provenance describes the ancestry or history of a digital object. Most existing provenance systems, however, operate at only one level of abstraction: the system call layer, a workflow specification, or the high-level constructs of a particular application. The provenance collectable in each of these layers is different, and all of it can be important. Single-layer systems fail to account for the different levels of abstraction at which users need to reason about their data and processes. These systems cannot integrate data provenance across layers and cannot answer questions that require an integrated view of the provenance.
We have designed a provenance collection structure facilitating the integration of provenance across multiple levels of abstraction, including a workflow engine, a web browser, and an initial runtime Python provenance tracking wrapper. We layer these components atop provenance-aware network storage (NFS) that builds upon a Provenance-Aware Storage System (PASS). We discuss the challenges of building systems that integrate provenance across multiple layers of abstraction, present how we augmented systems in each layer to integrate provenance, and present use cases that demonstrate how provenance spanning multiple layers provides functionality not available in existing systems. Our evaluation shows that the overheads imposed by layering provenance systems are reasonable.
HTML
PDF
Slides (PDF)
Muniswamy-Reddy, K., Braun, U., Holland, D., Macko, P., Maclean, D., Margo, D., Seltzer, M., Smogor, R.
Proceedings of the 2009 USENIX Annual Technical Conference, San Diego, CA, June 2009.
provenance, os
Hierarchical File Systems Are Dead
Abstract
For over forty years, we have assumed hierarchical file system namespaces. These namespaces were a rudimentary attempt at simple organization. As users have begun to interact with increasing amounts of data and are increasingly demanding search capability, such a simple hierarchical model has outlasted its usefulness. For this reason, we should design file systems whose organizations map to the ways we access and manipulate data now. We present a new file system architecture in which we replace the hierarchical namespace with a tagged, search-based one.
PDF
Slides (PDF)
Seltzer, M., Murphy, M.
Proceedings of the 12th Workshop on Hot Topics in Operating Systems (HOTOS'09), Monte Verita, Switzerland, May 2009.
file systems, storage
The Case for Browser Provenance
(PDF)
Margo, D., Seltzer, M.
1st Workshop on the Theory and Practice of Provenance (TaPP'09), February 2009.
provenance, ui
Making a Cloud Provenance-Aware
(PDF)
Muniswamy-Reddy, K., Seltzer, M.
1st Workshop on the Theory and Practice of Provenance (TaPP'09), February 2009.
provenance, cloud
2008
Securing Provenance
(PDF)
Braun, U., Shinnar, A., Seltzer, M.
Proceedings of the 3rd USENIX Workshop on Hot Topics in Security (HotSec), San Jose, CA, July 2008.
provenance, security
Choosing a Data Model and Query Language for Provenance
(PDF)
Holland, D., Braun, U., Maclean, D., Muniswamy-Reddy, K., Seltzer, M.
Proceedings of the 2nd International Provenance and Annotation Workshop, Salt Lake City, UT, Jun 2008.
provenance, pl
2007
Improving Performance Isolation on Chip Multiprocessors via an Operating System Scheduler
Abstract
We describe a new operating system scheduling algorithm that improves performance isolation on chip multiprocessors (CMP). Poor performance isolation occurs when an application’s performance is determined by the behaviour of its co-runners, i.e., other applications simultaneously running with it. This performance dependency is caused by unfair, co- runner-dependent cache allocation on CMPs. Poor performance isolation interferes with the operating system’s control over priority enforcement and hinders QoS provisioning. Previous solutions required modifications to the hardware. We present a new software solution. Our cache-fair algorithm ensures that the application runs as quickly as it would under fair cache allocation, regardless of how the cache is actually allocated. If the thread executes fewer instructions per cycle than it would under fair cache allocation, the scheduler increases that thread’s CPU timeslice. This way, the thread’s overall performance does not suffer because it is allowed to use the CPU longer. We describe our implementation of the algorithm in SolarisTM 10, and show that it significantly improves performance isolation for SPEC CPU, SPEC JBB and TPC-C.
PDF
Fedorova, A., Seltzer, M., Smith, M.D.
Proceedings of the Sixteenth International Conference on Parallel Architectures and Compilation Techniques (PACT), Brasov, Romania, September 2007.
operating systems, scheduling
Can a System Virtualize Processors?
(PDF, Slides)
Stein, L., Holland, D., Seltzer, M., Zhang, Z.
Proceedings of the First EuroSys Workshop on Virtualization for HPC, Lisbon, Portugal, March 2007.
virtualization
PASS-ing the Provenance Challenge
(PDF)
Holland, D., Seltzer, M., Braun, U., Muniswamy-Reddy, K.
Special Edition of Concurrency and Computation: Practice and Experience Wiley and Sons, 2007.
provenance
Network Coordinates in the Wild
Abstract
Network coordinates provide a mechanism for selecting and placing servers efficiently in a large distributed system. This approach works well as long as the coordinates continue to accurately reflect network topology. We conducted a long-term study of a subset of a million-plus node coordinate system and found that it exhibited some of the problems for which network coordinates are frequently criticized, for example, inaccuracy and fragility in the presence of violations of the triangle inequality. Fortunately, we show that several simple techniques remedy many of these problems. Using the Azureus BitTorrent network as our testbed, we show that live, large-scale network coordinate systems behave differently than their tame PlanetLab and simulation-based counterparts. We find higher relative errors, more triangle inequality violations, and higher churn. We present and evaluate a number of techniques that, when applied to Azureus, efficiently produce accurate and stable network coordinates
HTML
PDF
Ledlie, J., Gardner, P., Seltzer, M.
Proceedings of the Conference on Network System Design and Implementation, Boston MA, April 2007.
networking
2006
Data Management for Internet-Scale Single-Sign-On
(PDF)
Sharon Perl, Margo Seltzer
2006 USENIX Workshop on Real, Large Distributed Systems (Worlds '06)
single sign-on, berkeley-db, BDB-HA, replication, high-availability
A Non-Work-Conserving Operating System Scheduler For SMT Processors
(PDF)
Fedorova, A., Seltzer, M., Smith, M.D.
Proceedings of the Workshop on the Interaction between Operating Systems and Computer Architecture (WIOSCA 2006), Boston MA, June 2006.
operating systems, scheduling
Provenance-Aware Storage Systems
Abstract
A Provenance-Aware Storage System (PASS) is a storage system that automatically collects and maintains prove- nance or lineage, the complete history or ancestry of an item. We discuss the advantages of treating provenance as meta-data collected and maintained by the storage system, rather than as manual annotations stored in a separately administered database. We describe a PASS implementation, discussing the challenges it presents, performance cost it incurs, and the new functionality it enables. We show that with reasonable overhead, we can provide useful functionality not available in today's file systems or provenance management systems.
HTML
PDF
Muniswamy-Reddy, K., Holland, D., Braun, U., Seltzer, M.
Proceedings of the 2006 USENIX Annual Technical Conference, Boston, MA, June 2006.
provenance, storage, file systems
Issues in Automatic Provenance Collection
Abstract
Automatic provenance collection describes systems that observe processes and data transformations inferring, collecting, and maintaining provenance about them. Automatic collection is a powerful tool for analysis of ob jects and processes, providing a level of transparency and pervasiveness not found in more conventional provenance systems. Unfortunately, automatic collection is also difficult. We discuss the challenges we encountered and the issues we exposed as we developed an automatic provenance collector that runs at the operating system level.
PDF
Braun, U., Garfinkel, S., Holland, D., Muniswamy-Reddy, K., Seltzer, M.,
Proceedings of the 2006 International Provenance and Annotation Workshop, Chicago, IL, May 2006.
provenance
EGG: An Extensible and Economics-inspired Open Grid Computing Platform
Abstract
The Egg project provides a vision and implementation of how heterogeneous computational requirements will be supported within a single grid and a compelling reason to explain why computational grids will thrive. Environment computing, which allows a user to specify properties that a compute environment must satisfy in order to support the users computation, provides a how. Economic principles, allowing resource owners, users, and other stakeholders to make value and policy statements, provides a why. The Egg project introduces a language for defining software environments (egg shell), a general type for grid objects (the cache), and a currency (the egg). The Egg platform resembles an economically driven Internet-wide Unix system with egg shell playing the role of a scripting language and caches playing the role of a global file system, including an initial collection of devices.
PDF
Slides (PDF)
Brunelle, J., Hurst, P., Huth, J., Kang, L., Ng, C., Parkes, D., Seltzer, M., Shank, J., Youssef, S.
Proceedings of the 2006 Grid Asia, Singapore, May 2006.
econcs
Network-Aware Operator Placement for Stream-Processing Systems
Abstract
To use their pool of resources efficiently, distributed stream-processing systems push query operators to nodes within the network. Currently, these operators, ranging from simple filters to custom business logic, are placed manually at intermediate nodes along the transmission path to meet application-specific performance goals. Determining placement locations is challenging because network and node conditions change over time and because streams may interact with each other, opening venues for reuse and repositioning of operators.
This paper describes a stream-based overlay network (SBON), a layer between a stream-processing system and the physical network that manages operator placement for stream-processing systems. Our design is based on a cost space, an abstract representation of the network and on-going streams, which permits decentralized, large-scale multi-query optimization decisions. We present an evaluation of the SBON approach through simulation, experiments on PlanetLab, and an integration with Borealis, an existing stream-processing engine. Our results show that an SBON consistently improves network utilization, provides low stream latency, and enables dynamic optimization at low engineering cost.
PDF
Pietzuch, P., Ledlie, J., Shneidman, J., Roussopoulos, M., Welsh, M., Seltzer, M.
Proceedings fo the 22nd International Conference on Data Engineering (ICDE ’06), Atlanta, GA, April 2006.
networking
2005
Supporting Network Coordinates on PlanetLab
Abstract
Large-scale distributed applications need latency information to make network-aware routing decisions. Collecting these measurements, however, can impose a high burden. Network coordinates are a scalable and efficient way to supply nodes with up-to-date latency estimates. We present our experience of maintaining network coordinates on PlanetLab. We present two different APIs for accessing coordinates: a per-application library, which takes advantage of application-level traffic, and a stand-alone service, which is shared across applications. Our results show that statistical filtering of latency samples improves accuracy and stability and that a small number of neighbors is sufficient when updating coordinates.
PDF
Pietzuch, P., Ledlie, J., Seltzer, M.
Proceedings of the Second Workshop on Real, Large Distributed Systems (WORLDS’05), San Francisco, CA, December 2005.
networking
Beyond Relational Databases
Abstract
This article discusses how data management needs vary across applications, pointing out that one needs to match database solutions with data management needs.
PDF
Seltzer, M.
ACM Queue, 3,3 April 2005
databases, kvstore
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design
Abstract
We investigated how operating system design should be adapted for multithreaded chip multiprocessors (CMT) -- a new generation of processors that exploit thread-level parallelism to mask the memory latency in modern workloads. We determined that the L2 cache is a critical shared resource on CMT and that an insufficient amount of L2 cache can undermine the ability to hide memory latency on these processors. To use the L2 cache as efficiently as possible, we propose an L2-conscious scheduling algorithm and quantify its performance potential. Using this algorithm it is possible to reduce miss ratios in the L2 cache by 25-37% and improve processor throughput by 27-45%.
PDF
Fedorova, A., Seltzer, M., Small, C., Nussbaum, D.
Proceedings of the 2005 Annual Technical Conference, Anaheim, CA April 2005.
operating systems, caching, scheduling
A Cost-Space Approach to Distributed Query Optimization in Stream-Based Overlays
Abstract
Distributed stream-based applications, such as continuous query systems, have network scale and time characteristics that challenge traditional distributed query optimization. The optimization sub-problems of plan generation and service placement should be integrated to meet these challenges. These tasks have typically been treated as independent sub-problems because of the complexity of their integration. We suggest cost spaces as one way to mitigate this complexity. We further consider how cost spaces can be used to allow tractable multi-query optimization.
PDF
Shneidman, J., Pietzuch, P., Welsh, M., Seltzer, M., Roussopoulos, M.
Proceedings of the 1st IEEE International Workshop on Networking Meets Databases (NetDB’05), Tokyo, Japan, April 2005.
algorithms, networking, p2p
Provenance Aware Sensor Data Storage
Abstract
Sensor network data has both historical and real-time value. Making historical sensor data useful, in particular, requires storage, naming, and indexing. Sensor data presents new challenges in these areas. Such data is location-specific but also distributed; it is collected in a particular physical location and may be most useful there, but it has additional value when com- bined with other sensor data collections in a larger distributed sys- tem. Thus, arranging location-sensitive peer-to-peer storage is one challenge. Sensor data sets do not have obvious names, so naming them in a globally useful fashion is another challenge. The last challenge arises from the need to index these sensor data sets to make them searchable. The key to sensor data identity is prove- nance, the full history or lineage of the data. We show how prove- nance addresses the naming and indexing issues and then present a research agenda for constructing distributed, indexed repositories of sensor data.
PDF
Slides (PDF)
Ledlie, J., Ng, C., Holland, D., Muniswamy-Reddy, K., Braun, U., Seltzer, M.
Proceedings of the 1st IEEE International Workshop on Networking Meets Databases (NetDB05) Tokyo, Japan, April 2005.
provenance, sensor networks, iot, naming
Distributed, Secure Load Balancing with Skew, Heterogeneity, and Churn
Abstract
Numerous proposals exist for load balancing in peer-to-peer (p2p) networks. Some focus on namespace balancing, making the distance between nodes as uniform as possible. This technique works well under ideal conditions, but not under those found empirically. Instead, researchers have found heavy-tailed query distributions (skew), high rates of node join and leave (churn), and wide variation in node network and storage capacity (heterogeneity). Other approaches tackle these less-than-ideal conditions, but give up on important security properties. We propose an algorithm that both facilitates good performance and does not dilute security. Our algorithm, k-Choices, achieves load balance by greedily matching nodes' target workloads with actual applied workloads through limited sampling, and limits any fundamental decrease in security by basing each node's set of potential identifiers on a single certificate. Our algorithm compares favorably to four others in trace-driven simulations. We have implemented our algorithm and found that it improved aggregate throughput by 20% in a widely heterogeneous system in our experiments.
PDF
Slides (PDF)
Ledlie, J., Seltzer, M.
Proceedings of the 2005 INFOCOM, March 2005.
algorithms, p2p, load balancing
Evaluating DHT Service Placement in Stream-Based Overlays
Abstract
Stream-based overlay networks (SBONs) are one approach to implementing large-scale stream processing systems. A fundamental consideration in an SBON is that of service placement, which determines the physical location of in-network processing services or operators, in such a way that network resources are used efficiently. Service placement consists of two components: node discovery, which selects a candidate set of nodes on which services might be placed, and node selection, which chooses the particular node to host a service. By viewing the placement problem as the composition of these two processes we can trade-off quality and efficiency between them. A bad discovery scheme can yield a good placement, but at the cost of an expensive selection mechanism.
Recent work on operator placement proposes to leverage routing paths in a distributed hash table (DHT) to obtain a set of candidate nodes for service placement. We evaluate the appropriateness of using DHT routing paths for service placement in an SBON, when aiming to minimize network usage. For this, we consider two DHT-based algorithms for node discovery, which use either the union or intersection of DHT routing paths in the SBON, and compare their performance to other techniques. We show that current DHT-based schemes are actually rather poor node discovery algorithms, when minimizing network utilization. An efficient DHT may not traverse enough hops to obtain a sufficiently large candidate set for placement. The union of DHT routes may result in a low-quality set of discovered nodes that requires an expensive node selection algorithm. Finally, the intersection of DHT routes relies on route convergence, which prevents the placement of services with a large fan-in.
PDF
Pietzuch, P, Shneidman, J., Ledlie, J., Welsh, M., Seltzer, M., Roussopoulos, M.
Proceedings of the International Workshop on Peer to Peer Systems (IPTPS’05), Ithaca, NY, February 2005.
algorithms, p2p, networking
2004
An Architecture A Day Keeps the Hacker Away
Abstract
System security as it is practiced today is a losing battle. In this paper, we outline a possible comprehensive solution for binary-based attacks, using virtual machines, machine descriptions, and randomization to achieve broad heterogeneity at the machine level. This heterogeneity increases the "cost" of broad-based binary attacks to a sufficiently high level that they cease to become feasible. The convergence of several recent technologies appears to make our approach achievable at a reasonable cost, with only moderate run-time overhead.
PDF
Slides (PDF)
Holland, D., Lim, A., Seltzer, M.
Proceedings of the 2004 Workshop on Architectural Support for Security and Anti-Virus," Boston, MA, April 2004.
architecture, synthesis
Open Problems in Data Collection
Abstract
Research in sensor networks, continuous queries (CQ), and other domains has been motivated by powerful applications that aim to aggregate, assimilate, and interact with scores of sensor networks in parallel. Numerous system ingredients are necessary to make these applications possible. Sensor network research is building some of these components from the bottom up, dealing with issues such as wireless connectivity and battery life. CQ, peer-to-peer (P2P), and other research areas are building top down, examining in-network services, naming, decentralized queries, and scale. While many research groups use the same types of applications to motivate their work, many of these applications cannot be built today because of missing bridge research. These challenges include: uniting vastly differing devices and services, managing intermittent connectivity, placing in-network services with QoS and other constraints, developing unified security models, and correlating between sensor networks. This paper distills these new problems and outlines one proposed system that explores solutions to these concerns.
PDF
Ledlie, J., Shneidman, J., Welsh, M., Roussopoulos, M. Seltzer, M.
Networks Proceedings of the 2004 SIGOPS European Workshop, September 2004, Leuven, Belgium.
networking, sensor networks, p2p
Chip Multithreading Systems Need a New Operating System Scheduler
Abstract
The unpredictable nature of modern workloads, characterized by frequent branches and control transfers, can result in processor pipeline utilization as low as 19%. Chip multithreading (CMT), a processor architecture combining chip multiprocessing and hardware multithreading, is designed to address this issue. Hardware vendors plan to ship CMT systems within the next two years; understanding how such systems will perform is crucial if we are to use them to full advantage.
Our simulation experiments show that a CMT-savvy operating system scheduler could improve application performance by a factor of two. In this paper we describe our initial analysis of application performance on CMT systems and propose a design for a scheduler tailored for the needs of a CMT system.
PDF
Fedorova, A., Small, C., Nussbaum, D., Seltzer, M.
Proceedings of the 2004 SIGOPS EUropean Workshop, September 2004, Leuven, Belgium.
operating systems, scheduling
File classification in self-* storage systems
Abstract
To tune and manage themselves, file and storage systems must understand key properties (e.g., access pattern, lifetime, size) of their various files. This paper describes how systems can automatically learn to classify the properties of files (e.g., read-only access pattern, short-lived, small in size) and predict the properties of new files, as they are created, by exploiting the strong associations between a file's properties and the names and attributes assigned to it. These associations exist, strongly but differently, in each of four real NFS environments studied. Decision tree classifiers can automatically identify and model such associations, providing prediction accuracies that often exceed 90%. Such predictions can be used to select storage policies (e.g., disk allocation schemes and replication factors) for individual files. Further, changes in associations can expose information about applications, helping autonomic system components distinguish growth from fundamental change.
PDF
PostScript
Mesnier, M., Thereska, E., Ellard, D., Ganger, G., Seltzer, M.
Proceedings of the International Conference on Autonomic Computing (ICAC-04), May 2004, New York, NY.
file systems, naming
The Case Against User-level Networking
Abstract
Extensive research on system support for enabling I/O-intensive applications to achieve performance close to the limits imposed by the hardware suggests two main approaches: Low overhead I/O protocols and the flexibility to customize I/O policies to the needs of applications. One way to achieve both is by supporting user-level access to I/O devices, enabling user-level implementations of I/O protocols. User-level networking is an example of this approach, specific to network interface controllers (NICs). In this paper, we argue that the real key to high-performance in I/O-intensive applications is user-level file caching and user-level network buffering, both of which can be achieved without user-level access to NICs.
Avoiding the need to support user-level networking carries two important benefits for overall system design: First, a NIC exporting a privileged kernel interface is simpler to design and implement than one exporting a user-level interface. Second, the kernel is re-instated as a global system resource controller and arbitrator. We develop an analytical model of network storage applications and use it to show that their performance is not affected by the use of a kernel-based API to NICs.
PDF
Magoutis, K., Seltzer, M., Gabber, E.
Proceedings of the Third Annual Workshop on System-Area Networks (SAN-3), February 2004, Madrid Spain.
operating systems, networking
Application Performance on the Direct Access File System
Abstract
The Direct Access File System (DAFS) is a distributed file system built on top of direct-access transports (DAT). Direct- access transports are characterized by using remote direct memory access (RDMA) for data transfer and user-level networking. The motivation behind the DAT-enabled distributed file system architecture is the reduction of the CPU overhead on the I/O data path.
We have created an implementation of DAFS for the FreeBSD platform. In this paper we describe the performance evaluation study of DAFS that we have performed using this software. The goal of this study is to determine whether the architecture of DAFS brings any fundamental performance benefits to applications compared to traditional distributed file systems, such as NFS. We perform comparison of DAFS to a version of NFS optimized to reduce the I/O overhead. In order to thoroughly understand the impact of DAFS on application performance, we consider a diverse range of applications workloads.
We conclude that DAFS can accomplish superior performance for latency-sensitive applications, outperforming NFS by up to a factor of 2. Bandwidth-sensitive applications do equally well on both systems, unless they are CPU-intensive, in which case they perform better on DAFS. We also found that RDMA is a less restrictive mechanism to achieve copy avoidance than that used by the optimized NFS.
PDF
Fedorova, A., Seltzer, M., Magoutis, K., Addetia, S.
Proceedings of Workshop on Software and Performance 2004 (WOSP’04), January 2004, Redwood City, CA.
file systems, networking
2003
New NFS Tracing Tools and Techniques for System Analysis
Abstract
Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF
PostScript
Ellard, D., Seltzer, M.
Proceedings of the 17th Annual Large Installation System Administration Conference (LISA’03), October 2003, San Diego, CA, pp 73-85.
file systems, tools
NFS Tricks and Benchmarking Traps
Abstract
We describe two modifications to the FreeBSD 4.6 NFS server to increase read throughput by improving the read-ahead heuristic to deal with reordered requests and stride access patterns. We show that for some stride access patterns, our new heuristics improve end-to-end NFS throughput by nearly a factor of two. We also show that benchmarking and experimenting with changes to an NFS server can be a subtle and challenging task, and that it is often difficult to distinguish the impact of a new algorithm or heuristic from the quirks of the underlying software and hardware with which they interact. We discuss these quirks and their potential effects.
PDF
PostScript
Slides (PDF)
Ellard, D., Seltzer, M.
Proceedings of the 2003 FREENIX Technical Conference, June 2003, San Antonio, TX, pp 101-114.
file systems
Passive NFS Tracing of Email and Research Workloads
Abstract
We present an analysis of a pair of NFS traces of contemporary email and research workloads. We show that although the research workload resembles previously-studied workloads, the email workload is quite different. We also perform several new analyses that demonstrate the periodic nature of file system activity, the effect of out-of-order NFS calls, and the strong relationship between the name of a file and its size, lifetime, and access
PDF
PostScript
Slides (PDF)
Ellard, D., Ledlie, J., Malkani, P., Seltzer, M
Proceedings of the Second Symposium on File and Storage Technologies, March 2003, San Francisco, CA, pp 203-216.
file systems, tools
Making the Most Out of Direct-Access Network Attached Storage
Abstract
The performance of high-speed network-attached storage applications is often limited by end-system overhead, caused primarily by memory copying and network protocol processing. In this paper, we examine alternative strategies for reducing overhead in such systems. We consider optimizations to remote procedure call (RPC)-based data transfer using either remote direct memory access (RDMA) or network interface support for pre-posting of application receive buffers. We demonstrate that both mechanisms enable file access throughput that saturates a 2Gb/s network link when performing large I/Os on relatively slow, commodity PCs. However, for multi-client workloads dominated by small I/Os, throughput is limited by the per-I/O overhead of processing RPCs in the server. For such workloads, we propose the use of a new network I/O mechanism, Optimistic RDMA (ORDMA). ORDMA is an alternative to RPC that aims to improve server throughput and response time for small I/Os. We measured performance improvements of up to 32% in server throughput and 36% in response time with use of ORDMA in our prototype.
PDF
Magoutis, K, Fedorova, A., Addetia, S., Seltzer, M.
Proceedings of the Second Symposium on File and Storage Technologies, March 2003, San Francisco, CA.
file systems, networking
Scooped Again
Abstract
The Peer-to-Peer (p2p) and Grid infrastructure communities are tackling an overlapping set of problems. In addressing these problems, p2p solutions are usually motivated by elegance or research interest. Grid researchers, under pressure from thousands of scientists with real file sharing and computational needs, are pooling their solutions from a wide range of sources in an attempt to meet user demand. Driven by this need to solve large scientific problems quickly, the Grid is being constructed with the tools at hand: FTP or RPC for data transfer, centralization for scheduling and authentication, and an assumption of correct, obediant nodes. If history is any guide, the World Wide Web depicts viscerally that systems that address user needs can have enormous staying power and affect future research. The Grid infrastructure is a great customer waiting for future p2p products. By no means should we make them our only customers, but we should at least put them on the list. If p2p research does not at least address the Grid, it may eventually be sidelined by defacto distributed algorithms that are less elegant but were used to solve Grid problems. In essense, well have been scooped, again.
PDF
PostScript
Ledlie, J., Shneidman, J., Seltzer, M., Huth, J.
Proceedings of the Second International Workshop on Peer-to-Peer Systems (IPTPS-03), Berkeley, CA, February 2003.
networking, p2p
2002
Building a Reliable Mutable File System on Peer-to-peer Storage
Abstract
This paper sketches the design of the Eliot File System (Eliot), a mutable filesystem that maintains the pure im- mutability of its peer-to-peer (P2P) substrate by isolating mutation in an auxiliary metadata service.
The immutability of address-to-content bindings has several advantages in P2P systems. However, mutable filesystems are desirable because they allow clients to update existing files; a necessary property for many applications. In order to facilitate modifications, the filesystem must provide some atom of mutability. Since this atom of mutability is a fundamental characteristic of the filesystem and not the underlying storage substrate, it is a mistake to violate the integrity of the substrate with special cases for mutability. Instead, Eliot employs a separate, generalized metadata service that isolates all mutation and client state in an auxiliary replicated database. Eliot provides fine-granularity file updates with either AFS open/close or NFS-like consistency semantics. Eliot builds a mutable filesystem on a global resource bed of purely immutable P2P block storage.
PDF
PostScript
Stein, C., Tucker, M., Seltzer, M.
Proceedings of the International Workshop on Reliable Peer-to-peer Distributed Systems, Osaka, Japan, October 2002.
file systems, p2p
Self-Organization in Peer-to-Peer Systems
Abstract
This paper addresses the problem of forming groups in peer-to-peer (P2P) systems and examines what dependability means in decentralized distributed systems. Much of the literature in this field assumes that the participants form a local picture of global state, yet little research has been done discussing how this state remains stable as nodes enter and leave the system. We assume that nodes remain in the system long enough to benefit from retaining state, but not sufficiently long that the dynamic nature of the problem can be ignored. We look at the components that describe a system's dependability and argue that next-generation decentralized systems must explicitly delineate the information dispersal mechanisms (e.g., probe, event-driven, broadcast), the capabilities assumed about constituent nodes (bandwidth, uptime, re-entry distributions), and distribution of information demands (needles in a haystack vs. hay in a haystack). We evaluate two systems based on these criteria: Chord and a heterogeneous-node hierarchical grouping scheme. The former gives a greater than 1 failed request rate under normal P2P conditions and a prototype of the latter a similar rate under more strenuous conditions with an order of magnitude more organizational messages. This analysis suggests several methods to greatly improve the prototype.
PDF
PostScript
Ledlie, J., Taylor, J., Serban, L., Seltzer, M.
Proceedings of the 10th ACM SIGOPS European Workshop, Saint-Emilion, France, September 2002.
networking, p2p
Structure and Performance of the Direct Access File System
Abstract
The Direct Access File System (DAFS) is an emerging industrial standard for network-attached storage. DAFS takes advantage of new user-level network interface standards. This enables a user-level file system structure in which client-side functionality for remote data access resides in a library rather than in the kernel. This structure addresses longstanding performance problems stemming from weak integration of buffering layers in the network transport, kernel-based file systems and applications. The benefits of this architecture include lightweight, portable and asynchronous access to network storage and improved application control over data movement, caching and prefetching.
This paper explores the fundamental performance characteristics of a user-level file system structure based on DAFS. It presents experimental results from an open-source DAFS prototype and compares its performance to a kernel-based NFS implementation optimized for zero-copy data transfer. The results show that both systems can deliver file access throughput in excess of 100 MB/s, saturating network links with similar raw bandwidth. Lower client overhead in the DAFS configuration can improve application performance by up to 40% over optimized NFS when application processing and I/O demands are well-balanced.
PDF
Magoutis, K., Addetia, S., Fedorova, A., Seltzer, M., Chase, J., Gallatin, D., Kisley, R., Wickremesinghe, R., Gabber, E.
Proceedings of the 2002 USENIX Technical Conference, June 2002, Monterey, CA, 1–14.
file systems, networking
On the Design of a New CPU Architecture for Pedagogical Purposes
Abstract
Ant-32 is a new processor architecture designed specifically to address the pedagogical needs of teaching many subjects, including assembly language programming, machine architecture, compilers, operating systems, and VLSI design. This paper discusses our motivation for creating Ant-32 and the philosophy we used to guide our design decisions and gives a high level decsription of the resulting design.
PDF
PostScript
Ellard, D., Holland, D., Murphy, N, Seltzer, M.
Proceedings of the Workshop on Computer Architecture Education, May, 2002, Anchorage, Alaska.
architecture, education
A New Instructional Operating System
Abstract
his paper presents a new instructional operating system, OS/161, and simulated execution environment, System/161, for use in teaching an introductory undergraduate operating systems course. We describe the new system, the assignments used in our course, and our experience teaching using the new system.
PDF
PostScript
Holland, D., Lim, A., and Seltzer, M.
Proceedings of the 2002 SIGCSE Conference, February 2002, Covington, KY, 111–115.
operating systems, education
2001
Unifying File System Protection
(PDF)
Stein, C., Howard, J., Seltzer, M.
Proceedings of the 2001 USENIX Technical Conference, June 2001, Boston, MA, 79–90.
file systems, security
Research Issues in No-Futz Computing
Abstract
At the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), the attendees reached consensus that the most important issue facing the OS research community was "No-Futz" computing; eliminating the ongoing "futzing" that characterizes most systems today. To date, little research has been accomplished in this area. Our goal in writing this paper is to focus the research community on the challenges we face if we are to design systems that are truly futz-free, or even low-futz.
PDF
PostScript
Holland, D., Josephson, W., Magoutis, K., Seltzer, M., Stein, C.
Proceedings of the 2001 Workshop on Hot Topics in Operating Systems (HotOS VII), Elmau Germany, May 2001.
operating systems
HBench:JGC - An Application-Specific Benchmark Suite for Evaluating JVM Garbage Collector Performance
Abstract
As Java becomes a viable platform for server applications, performance becomes a greater concern. An important aspect of Java Virtual Machine performance is its dynamic memory management system (garbage collection or GC). Traditional GC benchmarking often focuses on a set of fixed applications. As a result, when an actual application's memory behavior differs from that of the standard benchmarks, the benchmark results do not help the user judge which GC implementation suits her application the best. In this paper, we present HBench:JGC, an application-specific benchmarking suite, based on the idea that a system's performance be measured in the context of a specific application. HBench:JGC employs a methodology that characterizes the application memory usage and the GC implementation independently and carefully combines both characterizations to form a single metric that reflects a particular application's performance in the presence of a particular GC implementation. We evaluate our approach on Sun Microsystems's JDK1.2.2 classic JVM with a sequential mark-sweep GC. Our results demonstrate HBench:JGC's unique predictive power and its ability to provide meaningful metrics that lead to a better understanding of GC performance.
PDF
Zhang, X., Seltzer, M.
Proceedings of the 6th USENIX Conference on Object-Oriented Technology (COOTS 2001), February 2001, San Antonio, TX.
benchmarking
2000
Journaling versus Soft Updates: Asynchronous Meta-data Protection in File Systems
Abstract
The UNIX Fast File System (FFS) is probably the most widely-used file system for performance comparisons. However, such comparisons frequently overlook many of the performance enhancements that have been added over the past decade. In this paper, we explore the two most commonly used approaches for improving the performance of meta-data operations and recovery: journaling and Soft Updates. Journaling systems use an auxiliary log to record meta-data operations and Soft Updates uses ordered writes to ensure meta-data consistency.
The commercial sector has moved en masse to journaling file systems, as evidenced by their presence on nearly every server platform available today: Solaris, AIX, Digital UNIX, HP-UX, Irix, and Windows NT. On all but Solaris, the default file system uses journaling. In the meantime, Soft Updates holds the promise of providing stronger reliability guarantees than journaling, with faster recovery and superior performance in certain boundary cases.
HTML
PDF
PostScript
Slides (PDF)
Slides (PostScript)
Seltzer, M., Ganger, G., McKusick, M., Smith, K., Soules, C., Stein, C.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 71–84.
file systems
Isolation with Flexibility: A Resource Management Framework for Central Servers
Abstract
Proportional-share resource management is becoming increasingly important in today's computing environments. In particular, the growing use of the computational resources of central service providers argues for a proportional-share approach that allows resource principals to obtain allocations that reflect their relative importance. In such environments, resource principals must be isolated from one another to prevent the activities of one principal from impinging on the resource rights of others. However, such isolation limits the flexibility with which resource allocations can be modified to reflect the actual needs of applications. We present extensions to the lottery-scheduling resource management framework that increase its flexibility while preserving its ability to provide secure isolation. To demonstrate how this extended framework safely overcomes the limits imposed by existing proportional-share schemes, we have implemented a prototype system that uses the framework to manage CPU time, physical memory, and disk bandwidth. We present the results of experiments that evaluate the prototype, and we show that our framework has the potential to enable server applications to achieve significant gains in performance.
Addendum
As discussed in our 2000 USENIX paper, lottery scheduling's currency abstraction imposes lower limits on the resource allocations that clients of a system can receive. In our USENIX paper, we proposed one method for overcoming these lower limits. In this addendum to the paper, we discuss a limitation of our original solution to the lower-limits problem, and we propose an alternate solution that overcomes the shortcomings of the original solution.
PDF
PostScript
Slides (PDF)
Addendum (PDF)
Sullivan., D., Seltzer, M.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 337–-350.
os, scheduling
Operating System Support for Multi-User, Remote Graphical Interaction
Abstract
The emergence of thin client computing and multi-user, remote, graphical interaction revives a range of operating system research issues long dormant, and introduces new directions as well. This paper investigates the effect of operating system design and implementation on the performance of thin client service and interactive applications. We contend that the key performance metric for this type of system and its applications is user-perceived latency and we give a structured approach for investigating operating system design with this criterion in mind. In particular, we apply our approach to a quantitative comparison and analysis of Windows NT, Terminal Server Edition (TSE), and Linux with the X Windows System, two popular implementations of thin client service.
We find that the processor and memory scheduling algorithms in both operating systems are not tuned for thin client service. Under heavy CPU and memory load, we observed user-perceived latencies up to 100 times beyond the threshold of human perception. Even in the idle state, these systems induce unnecessary latency. TSE performs particularly poorly despite scheduler modifications to improve interactive responsiveness. We also show that TSE's network protocol outperforms X by up to six times, and also makes use of a bitmap cache which is essential for handling dynamic elements of modern user interfaces and can reduce network load in these cases by up to 2000%.
PDF
Wong., A., Seltzer, M.
Proceedings of the 2000 USENIX Technical Conference, June 2000, San Diego, CA, 183–196.
operating systems, networking
Improving Interactive System Performance Using TIPME
Abstract
On the vast majority of today's computers, the dominant form of computation is GUI-based user interaction. In such an environment, the user's perception is the final arbiter of performance. Human-factors research shows that a user's perception of performance is affected by unexpectedly long delays. However, most performance-tuning techniques currently rely on throughput-sensitive benchmarks. While these techniques improve the average performance of the system, they do little to detect or eliminate response-time variabilities--in particular, unexpectedly long delays.
We introduce a measurement infrastructure that allows us to improve user-perceived performance by helping us to identify and eliminate the causes of the unexpected long response times that users find unacceptable. We describe TIPME (The Interactive Performance Monitoring Environment), a collection of measurement tools that allowed us to quickly and easily diagnose interactive performance "bugs" in a mature operating system. We present two case studies that demonstrate the effectiveness of our measurement infrastructure. Each of the performance problems we identify drastically affects variability in response time in a mature system, demonstrating that current tuning techniques do not address this class of performance problems.
PDF
PostScript
Endo, Y., Seltzer, M.
Proceedings of the 2000 ACM Sigmetrics Conference, June 2000, Santa Clara, CA.
benchmarking
HBench:Java: An Application-Specific Benchmark for JVMs
Abstract
Java applications represent a broad class of programs, ranging from programs running on embedded products to high-performance server applications. Standard Java benchmarks ignore this fact and assume a fixed workload. When an actual application's behavior differs from that included in a standard benchmark, the benchmark results are useless, if not misleading. In this paper, we present HBench:Java, an application-specific benchmarking framework, based on the concept that a system's performance must be measured in the context of the application of interest. HBench:Java employs a methodology that uses vectors to characterize the application and the underlying JVM and carefully combines the two vectors to form a single metric that reflects a specific application's performance on a particular JVM such that the performance of multiple JVMs can be realistically compared. Our performance results demonstrate HBench:Java's superiority over traditional benchmarking approaches in predicting real application performance and its ability to pinpoint performance problems.
PDF
Zhang, X., Seltzer, M.
Proceedings of the ACM 2000 Java Grande Conference, June 2000, San Francisco, CA.
benchmarking
1999
Evaluating Windows NT Terminal Server Performance
Abstract
With the introduction of Windows NT, Terminal Server Edition (TSE), Microsoft finally brings to Windows the ``thin-client'' computing model the X Window System has offered Unix for a decade. TSE's two most salient features are the provision of multi-user login service and the provision of that service remotely, over a network link. These features distinguish TSE from previous Microsoft operating systems not only by functionality, but also by how its performance ought to be measured. Because TSE's primary service is interactive, user-perceived latency is more important than ever. In this paper, we examine the resource consumption and latency characteristics of shared usage on a TSE system. We find that the introduction of remote, multi-user access has added to the minimal level of resource consumption, that the efficiency of TSE's RDP protocol is generally good but degrades on dynamic user interface elements, and that TSE can exhibit poor latency performance when subjected to high processor, memory, and network load.
PDF
PostScript
Wong, A., Seltzer, M.
Proceedings of the 3rd USENIX Windows NT Symposium, July, 1999, Seattle, WA, 145–154.
benchmarking, ui
HACC: An Architecture for Cluster-Based Web Server
Abstract
This paper presents the design, implementation, and performance of the Harvard Array of Clustered Computers (HACC), a cluster-based design for scalable, cost-effective web servers. HACC is designed for locality enhancement. Requests that arrive at the cluster are distributed among the nodes so as to enhance the locality of reference that occurs on individual nodes in the cluster. By improving locality on individual cluster nodes, we can reduce their working set sizes and achieve superior performance for less cost than conventional approaches. We implemented HACC on Windows NT 4.0 and evaluated its performance for both static documents and workloads of dynamically generated documents adapted from logs of commercial web servers. Our performance results show that HACC's locality enhancement can improve performance by up to 121% for our stochastically generated static file case, by up to 40% for our trace-based static file case, and by up to 52% for our trace-based dynamic document case, compared to an IP-Sprayer approach to building cluster-based web servers.
PDF
Zhang, X., Barrientos, M., Chen, J., Seltzer, M.
Proceedings of the 3rd USENIX Windows NT Symposium, July, 1999, Seattle, WA, 155–164.
storage, p2p
Berkeley DB
Abstract
Berkeley DB is an Open Source embedded database system with a number of key advantages over comparable systems. It is simple to use, supports concurrent access by multiple users, and provides industrial-strength transaction support, including surviving system and disk crashes. This paper describes the design and technical features of Berkeley DB, the distribution, and its license.
PDF
Olson, M., Bostic, K., Seltzer, M.
Proceedings of the 1999 FREENIX Conference, June, 1999, Monterey, CA.
databases, kvstore
Tickets and Currencies Revisted: Extensions to Multi-Resource Lottery Scheduling
Abstract
Lottery scheduling's ticket and currency abstractions provide a resource management framework that allows for both flexible allocation and insulation between groups of processes. We propose extensions to this framework that enable greater flexibility while preserving the ability to isolate groups of processes. In particular, we present a mechanism that allows processes to modify their own resource rights by exchanging resource-specific tickets with other processes. Ticket exchanges limit the effects of the changed allocations to the participants in the exchange, and they allow applications to coordinate with each other in ways that are mutually beneficial. Application-specific "negotiators" can be used to initiate exchanges based on an application's quality-of-service requirements and the current state of the system. We also propose flexible access controls for currencies through extensible "brokers" that solve such problems as the inability of users isolated by currencies to renice background jobs. Finally, we suggest using extensibility to allow users to install specialized allocation mechanisms for their processes. Together, these extensions enable an application-centered approach to resource management that is both secure and effective.
HTML
PDF
PostScript
Slides (PostScript)
Sullivan, D., Haas, R., Seltzer, M.
Proceedings of the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), March, 1999, Rio Rico, AZ.
os, scheduling
The Case for Application-Specific Benchmarking
Abstract
Most performance analysis today uses either microbenchmarks or standard macrobenchmarks (e.g., SPEC, LADDIS, the Andrew benchmark). However, the results of such benchmarks provide little information to indicate how well a particular system will handle a particular application. Such results are, at best, useless and, at worst, misleading. In this paper, we argue for an application-directed approach to benchmarking, using performance metrics that reflect the expected behavior of a particular application across a range of hardware or software platforms. We present three different approaches to application-specific measurement, one using vectors that characterize both the underlying system and an application, one using trace-driven techniques, and a hybrid approach. We argue that such techniques should become the new standard.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Seltzer, M., Krinsky, D., Smith, K., Zhang, X.
Proceedings of the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), March, 1999, Rio Rico, AZ.
benchmarking
Challenges in Embedded Database System Administration
Abstract
Database configuration and maintenance have historically been complex tasks, often requiring expert knowledge of database design and application behavior. In an embedded environment, it is not feasible to require such expertise and ongoing database maintenance. This paper discusses the database administration challenges posed by embedded systems and describes how the Berkeley DB architecture addresses these challenges.
HTML
Seltzer, M., Olson, M.
Proceedings of the 1999 USENIX Workshop on Embedded Systems, Cambridge, MA, March 1999.
databases
The ANT Architecture — An Architecture for CS1
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncracies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts. Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF
PostScript
Ellard, D. J., Ellard, P. A., Megquier, J. M., Chen, J. B., Seltzer, M. I.
The IEEE Computer Society Technical Committee on Computer Architecture Newsletter, February, 1999, 25–27.
architecture, education
1998
MiSFIT: Constructing Safe Extensible Systems
Abstract
The boundary between application and system is becoming increasingly permeable. Extensible applications, such as web browsers, database systems, and operating systems, demonstrate the value of allowing end-users to extend and modify the behavior of what was formerly considered to be a static, inviolate system. Unfortunately, flexibility often comes with a cost: systems unprotected from misbehaved end-user extensions are fragile and prone to instability.
Object-oriented programming models are a good fit for the development of this kind of system. An extension can be designed as a refinement to an existing class and loaded into a running system. In our model, when code is downloaded into the system, it is used to replace a virtual function on an existing C++ object. Because our tool is source-language-neutral, it can be used to build safe, extensible systems written in other languages as well.
There are three methods commonly used to make end-user extensions safe: restrict the extension language (e.g., Java), interpret the extension language (e.g., Tcl), or combine run-time checks with a trusted environment. The third technique is the one discussed here; it offers the twin benefits of the flexibility to implement extensions in an unsafe language, such as C++, and the performance of compiled code.
MiSFIT, the Minimal i386 Software Fault Isolation Tool, can be used as a component of a tool set for building safe extensible systems in C++. MiSFIT transforms C++ code, compiled by the Gnu C++ compiler, into safe binary code. Combined with a runtime support library, the overhead of MiSFIT is an order of magnitude lower than the overhead of interpreted Java, and permits safe extensible systems to be written in C++.
PDF
Small, C., Seltzer, M.
IEEE Concurrency, (6), 3, July–Sep 1998, 34–41.
operating systems, tools, pl
The Mug Shot Search
Abstract
Mug-shot search is the classic example of the general problem of searching a large facial image database when starting out with only a mental image of the sought-after face. We have implemented a prototype content-based image retrieval system that integrates composite face creation methods with a face-recognition technique (Eigenfaces) so that a user can both create faces and search for them automatically in a database.
Although the Eigenface method has been studied extensively for its ability to perform face identification tasks (in which the input to the system is an on-line facial image to identify), little research has been done to determine how effective it is when applied to the mug shot search problem (in which there is no on-line input image at the outset, and in which the task is similarity retrieval rather than face-recognition). With our prototype system, we have conducted a pilot user study that examines the usefulness of Eigenfaces applied to this problem. The study shows that the Eigenface method, though helpful, is an imperfect model of human perception of similarity between faces. Using a novel evaluation methodology, we have made progress at identifying specific search strategies that, given an imperfect correlation between the system and human similarity metrics, use whatever correlation does exist to the best advantage. The study also indicates that the use of facial composites as query images is advantageous compared to restricting users to database images for their queries.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Slides (PDF)
Baker, E., Seltzer, M.
Proceedings of the 1998 Vision Interfaces Conference, Vancouver, Canada, June 1998, 421–430.
algorithms, ui
The ANT Architecture — An Architecture for CS1
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncrasies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts.
PDF
PostScript
Ellard, D., Ellard, Pl, Megquier, J., Chen, JB, Seltzer, M.
Proceedings of the Workshop on Computer Architecture Education, 1998.
architecture, education
1997
Web Facts and Fantasy
Abstract
There is a great deal of research about improving Web server performance and building better, faster servers, but little research in characterizing servers and the load imposed upon them. While some tremendously popular and busy sites, such as netscape.com, playboy.com, and altavista.com, receive several million hits per day, most servers are never subjected to loads of this magnitude. This paper presents the analysis of internet Web server logs for a variety of different types of sites. We present a taxonomy of the different types of Web sites and characterize their access patterns and, more importantly, their growth. We then use our server logs to address some common perceptions about the Web. We show that, on a variety of sites, contrary to popular belief, the use of CGI does not appear to be increasing and that long latencies are not necessarily due to server loading. We then show that, as expected, persistent connections are generally useful, but that dynamic time-out intervals may be unnecessarily complex and that allowing multiple persistent connections per client may actually hinder resource utilization compared to allowing only a single persistent connection.
HTML
PDF
PostScript
Manley, S., Seltzer, M.
Proceedings of the Symposium on Internet Technologies and Systems, Monterey, CA, December 1997, 125-134.
networking, web
Measuring Windows NT — Possibilities and Limitations
Abstract
The majority of today's computing takes place on interactive systems that use a Graphical User Interface (GUI). Performance of these systems is unique in that "good performance" is a reflection of a user's perception. In this paper, we explain why this unique environment requires a new methodological aproach. We describe a measurement/diagnostic tool currently under development and evaluate the feasibility of implementing such a tool under Windows NT. We then present several issues that must be resolved in order for Windows NT to become a popular research platform for this type of work.
PDF
Endo, Y., Seltzer M.
Proceedings of the First USENIX Workshop on NT, Seattle, WA, August 1997.
benchmarking, operating systems
Operating System Benchmarking in the Wake of Lmbench: Case Study of the Performance of NetBSD on the Intel Architecture
Abstract
The lmbench suite of operating system microbenchmarks provides a set of portable programs for use in cross-platform comparisons. We have augmented the lmbench suite to increase its flexibility and precision, and to improve its methodological and statistical operation. This enables the detailed study of interactions between the operating system and the hardware architecture. We describe modifications to lmbench, and then use our new benchmark suite, hbench:OS, to examine how the performance of operating system primitives under NetBSD has scaled with the processor evolution of the Intel x86 architecture. Our analysis shows that off-chip memory system design continues to influence operating system performance in a significant way and that key design decisions (such as suboptimal choices of DRAM and cache technology, and memory-bus and cache coherency protocols) can essentially nullify the performance benefits of the aggressive execution core and sophisticated on-chip memory system of a modern processor such as the Intel Pentium Pro.
HTML
PDF
PostScript
Additional documentation
Brown, A., Seltzer, M.
Proceedings of the 1997 Sigmetrics Conference, Seattle, WA, June 1997, 214-224.
benchmarking, os
File System Aging
Abstract
Benchmarks are important because they provide a means for users and researchers to characterize how their workloads will perform on different systems and different system architectures. The field of file system design is no different from other areas of research in this regard, and a variety of file system benchmarks are in use, representing a wide range of the different user workloads that may be run on a file system. A realistic benchmark, however, is only one of the tools that is required in order to understand how a file system design will perform in the real world. The benchmark must also be executed on a realistic file system. While the simplest approach maybe to measure the performance of an empty file system, this represents a state that is seldom encountered by real users. In order to study file systems in more representative conditions, we present a methodology for aging a test file system by replaying a workload similar to that experienced by a real file system over a period of many months, or even years. Our aging tools allow the same aging workload to be applied to multiple versions of the same file system, allowing scientific evaluation of the relative merits of competing file system designs.
In addition to describing our aging tools, we demonstrate their use by applying them to evaluate two enhancements to the file layout policies of the UNIX fast file system.
HTML
PDF
PostScript
Slides (PostScript)
Slides (HTML)
Slides (PDF)
Smith, K., Seltzer, M.
Proceedings of the 1997 Sigmetrics Conference, Seattle, WA, June 1997, 203-213.
file systems
Self-Monitoring and Self-Adapting Operating Systems
Abstract
Extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. Extensibility enables a system to efficiently support a broader class of applications than is currently supported. This paper discusses the key challenge in making extensible systems practical: determining which parts of the system need to be extended and how. The determination of which parts of the system need to be extended requires self-monitoring, capturing a significant quantity of data about the performance of the system. Determining how to extend the system requires self-adaptation. In this paper, we describe how an extensible operating system (VINO) can use in situ simulation to explore the efficacy of policy changes. This automatic exploration is applicable to other extensible operating systems and can make these systems self-adapting to workload demands.
PDF
Slides (PDF)
Seltzer, M., Small, C.
Proceedings of the 1997 Workshop on Hot Operating Systems, Cape Cod, MA, May 5-6, 1997, 124-129.
operating systems
1996
Dealing with Disaster: Surviving Misbehaving Kernel Extensions
Abstract
Today's extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. The advantage of this approach is that it provides improved application flexibility and performance; the disadvantage is that buggy or malicious code can jeopardize the integrity of the kernel. It has been demonstrated that it is feasible to use safe languages, software fault isolation, or virtual memory protection to safeguard the main kernel. However, such protection mechanisms do not address the full range of problems, such as resource hoarding, that can arise when application code is introduced into the kernel.
In this paper, we present an analysis of extension mechanisms in the VINO kernel. VINO uses software fault isolation as its safety mechanism and a lightweight transaction system to cope with resource-hoarding. We explain how these two mechanisms are sufficient to protect against a large class of errant or malicious extensions, and we quantify the overhead that this protection introduces.
We find that while the overhead of these techniques is high relative to the cost of the extensions themselves, it is low relative to the benefits that extensibility brings.
HTML
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M., Endo, Y., Small, C., Smith, K.
Proceedings of the Second Symposium on Operating System Design and Implementation, Seattle, WA, October 1996, 213-227.
operating systems
Understanding Latency in GUI-based Applications
Endo, Y., Wang, Z., Chen, B., Seltzer, M.
Proceedings of the Second Symposium on Operating System Design and Implementation, Seattle, WA, October 1996, 195-199.
benchmarking, ui
Symbiotic System Software: Fast Operating Systems for Fast Applications
(PDF)
Seltzer., M., Small, C., Smith, M.
Proceedings of the First Workshop on Compiler Support for System Software, Tuscon, AZ, Feb 1996.
operating systems
World-Wide Web Cache Consistency
Abstract
The bandwidth demands of the World Wide Web continue to grow at a hyper-exponential rate. Given this rocketing growth, caching of web objects as a means to reduce network bandwidth consumption is likely to be a necessity in the very near future. Unfortunately, many Web caches do not satisfactorily maintain cache consistency. This paper presents a survey of contemporary cache consistency mechanisms in use on the Internet today and examines recent research in Web cache consistency. Using trace-driven simulation, we show that a weak cache consistency protocol (the one used in the Alex ftp cache) reduces network bandwidth consumption and server load more than either time-to-live fields or an invalidation protocol and can be tuned to return stale data less than 5% of the time.
PDF
PostScript
Gwertzman, J., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 141-152.
caching, web
Comparison of OS Extension Technologies
Abstract
The current trend in operating systems research is to allow applications to dynamically extend the kernel to improve application performance or extend functionality, but the most effective approach to extensibility remains unclear. Some systems use safe languages to permit code to be downloaded directly into the kernel; other systems provide in-kernel interpreters to execute extension code; still others use software techniques to ensure the safety of kernel extensions. The key characteristics that distinguish these systems are the philosophy behind extensibility and the technology used to implement extensibility. This paper presents a taxonomy of the types of extensions that might be desirable in an extensible operating system, evaluates the performance cost of various extension techniques currently being employed, and compares the cost of adding a kernel extension to the benefit of having the extension in the kernel. Our results show that compiled technologies (e.g. Modula-3 and software fault isolation) are good candidates for implementing general-purpose kernel extensions, but that the overhead of interpreted languages is sufficiently high that they are inappropriate for this use.
PDF
PostScript
Small, C., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 41-54.
operating systems, transactions
A Comparison of FFS Disk Allocation Policies
Abstract
The 4.4BSD file system includes a new algorithm for allocating disk blocks to files. The goal of this algorithm is to improve file clustering, increasing the amount of sequential I/O when reading or writing files, thereby improving file system performance. In this paper we study the effectiveness of this algorithm at reducing file system fragmentation. We have created a program that artificially ages a file system by replaying a workload similar to that experienced by a real file system. We used this program to evaluate the effectiveness of the new disk allocation algorithm by replaying ten months of activity on two file systems that differed only in the disk allocation algorithms that they used. At the end of the ten month simulation, the file system using the new allocation algorithm had approximately half the fragmentation of a similarly aged file system that used the traditional disk allocation algorithm. Measuring the performance difference between the two file systems by reading and writing the same set of files on the two systems showed that this decrease in fragmentation improved file write throughput by 20% and read throughput by 32%. In certain test cases, the new allocation algorithm provided a performance improvement of greater than 50%.
PDF
Supplementary Materials
Smith, K., Seltzer, M.
Proceedings of the 1996 USENIX Technical Conference, San Diego, CA January 1996, 15-26.
file systems
The Measured Performance of Personal Computer Operating Systems
Abstract
This paper presents a comparative study of the performance of three operating systems that run on the personal computer architecture derived from the IBM-PC. The operating systems, Windows for Workgroups (tm), Windows NT (tm), and NetBSD (a freely available UNIX (tm) variant) cover a broad range of system functionality and user requirements, from a single address space model to full protection with preemptive multi-tasking. Our measurements were enabled by hardware counters in Intel's Pentium (tm) processor that permit measurement of a broad range of processor events including instruction counts and on-chip cache miss counts. We used both microbenchmarks, which expose specific differences between the systems, and application workloads, which provide an indication of expected end-to-end performance. Our microbenchmark results show that accessing system functionality is often more expensive in Windows than in the other two systems due to frequent changes in machine mode and the use of system call hooks. When running native applications, Windows NT is more efficient than Windows, but it incurs overhead similar to that of a microkernel since its application interface(the Win32 API) is implemented as a user-level server. Overall, system functionality can be accessed most efficiently in NetBSD; we attribute this to its monolithic structure, and to the absence of the complications created by backwards compatibility in the other systems. Measurements of application performance show that although the impact of these differences is significant in terms of instruction counts and other hardware events (often a factor of 2 to 7 difference between the systems), overall performance is sometimes determined by the functionality provided by specific subsystems, such as the graphics subsystem or the file system buffer cache.
PDF
PostScript
Supplementary Materials
Transactions on Computer Systems version (PostScript)
Chen, B., Endo, Y., Chan, K., Mazieres, D., Dias, A., Seltzer, M., Smith, M.
Proceedings of the 15th ACM Symposium on Operating Systems Principles, Copper Mountain, Colorado, December 3-6, 1995. Also in ACM Transactions on Computer Systems, January 1996, 3-40.
benchmarking, operating systems
1995
Structuring the Kernel as a Toolkit of Extensible, Reusable Components
Abstract
Applications often require functionality that is implemented in the kernel, but is not directly available to the user level. While extensible operating systems allow kernel functionality to be augmented, we believe that the emphasis on extensibility is misplaced. Applications should be able to reuse kernel code directly and the emphasis should be placed on designing a kernel with that reuse in mind. The advantage of structuring the kernel as a set of reusable, extensible tools is that applications can avoid re-implementing functionality that is already present in the kernel. This will lead to smaller applications, fewer lines of total code, and a more unified computing environment that will be easier to maintain and perform better.
PDF
PostScript
Small, C., Seltzer, M.
Proceedings of the International Workshop on Object Orientation in Operating Systems, Lund, Sweden, August 1995, 134-137.
operating systems
The Case for Geographical Push-Caching
Abstract
Most existing wide-area caching schemes are client initiated. Decisions on when and where to cache information are made without the benefit of the server's global knowledge of the situation. We believe that the server should play a role in making these caching decisions, and we propose geographical push-caching as a way of bringing the server back into the loop. The World Wide Web is an excellent example of a wide-area system that will benefit from geographical push-caching, and we present an architecture that allows a Web server to autonomously replicate HTML pages.
PDF
PostScript
Gwertzman, J., Seltzer., M.
Proceedings of the Fifth Annual Workshop on Hot Operating Systems, Orcas Island, WA, May 1995, 51-55.
caching, web
File System Logging versus Clustering: A Performance Comparison
Abstract
The Log-structured File System (LFS), introduced in 1991, has received much attention for its potential order-of-magnitude improvement in file system performance. Early research results showed that small file performance could scale with processor speed and that cleaning costs could be kept low, allowing LFS to write at an effective bandwidth of 62 to 83% of the maximum. Later work showed that the presence of synchronous disk operations could degrade performance by as much as 62% and that cleaning overhead could become prohibitive in transaction processing workloads, reducing performance by as much as 40%. The same work showed that the addition of clustered reads and writes in the Berkeley Fast File System (FFS) made it competitive with LFS in large-file handling and software development environments as approximated by the Andrew benchmark.
These seemingly inconsistent results have caused confusion in the file system research community. This paper presents a detailed performance comparison of the 4.4BSD Log-structured File system and the 4.4BSD Fast File System. Ignoring cleaner overhead, our results show that the order-of-magnitude improvement in performance claimed for LFS applies only to meta-data intensive activities, specifically the creation of files one-kilobyte or less and deletion of files 64 kilobytes or less.
For small files, both systems provide comparable read performance, but LFS offers superior performance on writes. For large files (one megabyte and larger), the performance of the two file systems is comparable. When FFS is tuned for writing, its large-file write performance is approximately 15% better than LFS, but its write performance is 25% worse. When FFS is optimized for reading, its large-file read and write performance is comparable to LFS.
Both LFS and FFS can suffer performance degradation, due to cleaning and disk fragmentation respectively. We find that active FFS file systems function at approximately 85-95% of their maximum performance after two to three years. We examine LFS cleaner performance in a transaction-processing environment and find that cleaner overhead reduces LFS performance by more than 33% when the disk is 50% full.
PDF
PostScript
Supplementary Materials
Seltzer, M., Smith, K., Balakrishnan, H., Chang, J., McMains, S., Padmanabhan, V.
Proceedings of the 1995 Winter USENIX Technical Conference, New Orleans, LA, January 1995, 249-264.
file systems, benchmarking
Heuristic Cleaning Algorithms for Log-Structured File Systems
Abstract
Research results show that while Log-Structured File Systems (LFS) offer the potential for dramatically improved file system performance, the cleaner can seriously degrade performance, by as much as 40% in transaction processing workloads. Our goal is to examine trace data from live file systems and use those to derive simple heuristics that will permit the cleaner to run without interfering with normal file access. Our results show that trivial heuristics perform very well, allowing 97% of all cleaning on the most heavily loaded system we studied to be done in the background.
PDF
PostScript
Blackwell, T., Harris., J., Seltzer, M.
Proceedings of the 1995 Winter USENIX Technical Conference, New Orleans, LA, January 1995, 277-288.
algorithms, file systems
1994
An Experimental Flow Controlled Multicast ATM Switch
(PDF)
Blackwell, T., Chan, K., Chang, K., Charuhas, T., Karp, B., Kung, H. T., Lin, D., Morris, R., Seltzer, M., Smith, M., Young, C., Bahgat, O., Chaar, M., Chapman, A., Depelteau, G., Grimble, K., Huang, S., Hung, P., Kemp, M., McLaughlin, I., Ng, T., Vincent, J., and Watchor, J.
Proceedings of the First Annual Conference on Telecommunications Research and Development in Massachusetts, Vol. 6, October 1994, 33-38.
networking
Evolving Line Drawings
Abstract
This paper explores the application of interactive genetic algorithms to the creation of line drawings. We have built a system that mates or mutates drawings selected by the user to create a new generation of drawings. The initial population from which the user makes selections may be generated randomly or input manually. The process of selection and procreation is repeated many times to evolve a drawing. A wide variety of complex sketches with highlighting and shading can be evolved from very simple drawings. This technique has potential for augmenting and enhancing the power of traditional computer-aided drawing tools, and for expanding the repertoire of the computer-assisted artist.
HTML
PDF
PostScript
Slides (HTML)
Slides (PDF)
Baker, E., Seltzer, M.
Proceedings of Graphics Interface ’94, Banff, Canada, May 1994, 91-100.
visualization, algorithms
1993
Transaction Support in a Log-Structured File System
Abstract
Transaction Support in a Log-Structured File System
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M.
Proceedings of the Ninth International Conference on Data Engineering, Vienna, Austria, April 1993, 503-510.
file systems, transactions
An Implementation of a Log-Structured File System for UNIX
Abstract
Research results demonstrate that a log-structured file system offers the potential for dramatically improved write performance, faster recovery time, and faster file creation and deletion than traditional UNIX file systems. This paper presents a redesign and implementation of the Sprite log-structured file system that is more robust and integrated into the vnode interface. Measurements show its performance to be superior to the 4BSD Fast File System in a variety of benchmarks and not significantly less than FFS in any test. Unfortunately, an enhanced version of FFS (with read and write clustering) provides comparable and sometimes superior performance to our LFS. However, LFS can be extended to provide additional functionality such as embedded transactions and versioning, not easily implemented in traditional file systems.
PDF
PostScript
Slides (PostScript)
Slides (PDF)
Seltzer, M., Bostic, K., McKusick., M., Staelin, C.
Proceedings of the 1993 Winter USENIX Conference, San Diego, CA January 1993, 307-326.
file systems
1992
File System Performance and Transaction Support
(PDF)
Seltzer, M.,
Ph.D. Dissertation, University of California, Berkeley, December 1992.
file system, transaction support, read-optimized, write-optimized, log-structured file system
Non-Volatile Memory for Fast, Reliable File Systems
Abstract
Given the decreasing cost of non-volatile RAM (NVRAM), by the late 1990's it will be feasible for most workstations to include a megabyte or more of NVRAM, enabling the design of higher-performance, more reliable systems. We present the trace-driven simulation and analysis of two uses of NVRAM to improve I/O performance in distributed file systems: non-volatile file caches on client workstations to reduce write traffic to file servers, and write buffers for write-optimized file systems to reduce server disk accesses. Our results show that a megabyte of NVRAM on diskless clients reduces the amount of file data written to the server by 40 to 50%. Increasing the amount of NVRAM shows rapidly diminishing returns, and the particular NVRAM block replacement policy makes little difference to write traffic. Closely integrating the NVRAM with the volatile cache provides the best total traffic reduction. At today's prices, volatile memory provides a better performance improvement per dollar than NVRAM for client caching, but as volatile cache sizes increase and NVRAM becomes cheaper, NVRAM will become cost effective. On the server side, providing a one-half megabyte write-buffer per file system reduces disk accesses by about 20% on most of the measured log-structured file systems (LFS), and by 90% on one heavily-used file system that includes transaction-processing workloads.
PDF
PostScript
Baker, M., Asami, S., Deprit, E., Ousterhout, J., Seltzer, M.
Proceedings of ASPLOS-V, Boston, MA, October 1992, 10-22.
file systems, nvm
LIBTP: Portable, Modular Transactions for UNIX
Abstract
Transactions provide a useful programming paradigm for maintaining logical consistency, arbitrating concurrent access, and managing recovery. In traditional UNIX systems, the only easy way of using transactions is to purchase a database system. Such systems are often slow, costly, and may not provide the exact functionality desired. This paper presents the design, implementation, and performance of LIBTP, a simple, non-proprietary transaction library using the 4.4BSD database access routines (db(3)). On a conventional transaction processing style benchmark, its performance is approximately 85% that of the database access routines without transaction protection, 200% of that using fsync(2) to commit modifications to disk, and 125% that of a commercial relational database system.
PDF
PostScript
Seltzer, M., Olson, M.
Proceedings 1992 Winter USENIX Conference, San Francisco, CA, January 1992, 9-26.
databases, transactions
1991
Read Optimized File Systems: A Performance Evaluation
Abstract
This paper presents a performance comparison of several file system allocation policies. The file systems are designed to provide high bandwidth between disks and main memory by taking advantage of parallelism in an underlying disk array, cateringv to large units of transfer, and minimizing the bandwidth dedicated to the transfer of meta data. All of the file systems described use a multiblock allocation strategy that allows both large and small files to be allocated efficiently. Simulation results show that these multiblock policies result in systems that are able to utilize a large percentage of the underlying disk bandwidth; more than 90% in sequential cases. As general purpose systems are called upon to support more data intensive applications such as databases and supercomputing, these policies offer an opportunity to provide superior performance to a larger class of users.
PDF
PostScript
Seltzer, M., Stonebraker, M.
Proceedings 7th Annual International Conference on Data Engineering, Kobe, Japan, April 1991, 602-611.
file systems, benchmarking
A New Hashing Package for UNIX
Abstract
UNIX support of disk oriented hashing was originally provided by dbm [ATI79] and subsequently improved upon in ndbm [BSD86]. In AT&T System V, in-memory hashed storage and access support was added in the hsearch library routines [ATT85]. The result is a system with two incompatible hashing schemes, each with its own set of shortcomings. This paper presents the design and performance characteristics of a new hashing package providing a superset of the functionality provided by dbm and hsearch. The new package uses linear hashing to provide efficient support of both memory based and disk based hash tables with performance superior to both dbm and hsearch under most conditions.
PDF
PostScript
Seltzer, M., Yigit, O.
Proceedings 1991 Winter USENIX Conference, Dallas, TX, January 1991, 173-184.
algorithms, data structures
1990
Transaction Support in Read Optimized and Write Optimized File Systems
Abstract
This paper provides a comparative analysis of five implementations of transaction support. The first of the methods is the traditional approach of implementing transaction processing within a data manager on top of a read optimized file system. The second also assumes a traditional file system but embeds transaction support inside the file system. The third model considers a traditional data manager on top of a write optimized file system. The last two models both embed transaction support inside a write optimized file system, each using a different logging mechanism. Our results show that in a transaction processing environment, a write optimized file system often yields better performance than one optimized for reads. In addition, we show that file system embedded transaction managers can perform as well as data managers when transaction throughput is limited by I/O bandwidth. Finally, even when the CPU is the critical resource, the difference in performance between a data manager and an embedded system is much smaller than previous work has shown.
PDF
PostScript
Seltzer, M., Stonebraker, M.
Proceedings 16th International Conference on Very Large Data Bases, Brisbane, Australia, August 1990, 174-185.
file systems, transactions
Disk Scheduling Revisited
Abstract
Since the invention of the movable head disk, people have improved I/O performance by intelligent scheduling of disk accesses. We have applied these techniques to systems with large memories and potentially long disk queues. By viewing the entire buffer cache as a write buffer, we can improve disk bandwidth utilization by applying some traditional disk scheduling techniques. We have analyzed these techniques, which attempt to optimize head movement and guarantee fairness in response time, in the presence of long disk queues. We then propose two algorithms which take rotational latency into account, achieving disk bandwidth utilizations of nearly four times a simple first come first serve algorithm. One of these two algorithms, a weighted shortest total time first, is particularly applicable to a file server environment because it guarantees that all requests get to disk within a specified time window.
PDF
PostScript
Seltzer, M., Chen, P., Ousterhout, J.
Proceedings 1990 Winter USENIX Conference, Washington, D.C., January 1990, 313-324.
storage
Abstract
The explosion of graph data in social and biological networks, recommendation systems, provenance databases, etc. makes graph storage and processing of paramount importance. We present a performance introspection framework for graph databases, PIG, which provides both a toolset and methodology for understanding graph database performance. PIG consists of a hierarchical collection of benchmarks that compose to produce performance models; the models provide a way to illuminate the strengths and weaknesses of a particular implementation. The suite has three layers of benchmarks: primitive operations, composite access patterns, and graph algorithms. While the framework could be used to compare different graph database systems, its primary goal is to help explain the observed performance of a particular system. Such introspection allows one to evaluate the degree to which systems exploit their knowledge of graph access patterns. We present both the PIG methodology and infrastructure and then demonstrate its efficacy by analyzing the popular Neo4j and DEX graph databases.
PDF Slides (PDF)
The explosion of graph data in social and biological networks, recommendation systems, provenance databases, etc. makes graph storage and processing of paramount importance. We present a performance introspection framework for graph databases, PIG, which provides both a toolset and methodology for understanding graph database performance. PIG consists of a hierarchical collection of benchmarks that compose to produce performance models; the models provide a way to illuminate the strengths and weaknesses of a particular implementation. The suite has three layers of benchmarks: primitive operations, composite access patterns, and graph algorithms. While the framework could be used to compare different graph database systems, its primary goal is to help explain the observed performance of a particular system. Such introspection allows one to evaluate the degree to which systems exploit their knowledge of graph access patterns. We present both the PIG methodology and infrastructure and then demonstrate its efficacy by analyzing the popular Neo4j and DEX graph databases.
PDF Slides (PDF)
Abstract
Caching is a well-known technique for speeding up computation. We cache data from file systems and databases; we cache dynamically generated code blocks; we cache page translations in TLBs. We propose to cache the act of computation, so that we can apply it later and in different contexts. We use a state-space model of computation to support such caching, involving two interrelated parts: speculatively memoized predicted/resultant state pairs that we use to accelerate sequential computation, and trained probabilistic models that we use to generate predicted states from which to speculatively execute. The key techniques that make this approach feasible are designing probabilistic models that automatically focus on regions of program execution state space in which prediction is tractable and identifying state space equivalence classes so that predictions need not be exact.
PDF Slides (PDF)
Caching is a well-known technique for speeding up computation. We cache data from file systems and databases; we cache dynamically generated code blocks; we cache page translations in TLBs. We propose to cache the act of computation, so that we can apply it later and in different contexts. We use a state-space model of computation to support such caching, involving two interrelated parts: speculatively memoized predicted/resultant state pairs that we use to accelerate sequential computation, and trained probabilistic models that we use to generate predicted states from which to speculatively execute. The key techniques that make this approach feasible are designing probabilistic models that automatically focus on regions of program execution state space in which prediction is tractable and identifying state space equivalence classes so that predictions need not be exact.
PDF Slides (PDF)
Abstract
Flash memory has recently become popular as a caching medium. Most uses to date are on the storage server side. We investigate a different structure: flash as a cache on the client side of a networked storage environment. We use trace-driven simulation to explore the design space. We consider a wide range of configurations and policies to determine the potential client-side caches might offer and how best to arrange them.
Our results show that the flash cache writeback policy does not significantly affect performance. Write-through is sufficient; this greatly simplifies cache consistency handling. We also find that the chief benefit of the flash cache is its size, not its persistence. Cache persistence of- fers additional performance benefits at system restart at essentially no runtime cost. Finally, for some workloads a large flash cache allows using miniscule amounts of RAM for file caching (e.g., 256 KB) leaving more mem- ory available for application use.
PDF Slides (PDF)
Flash memory has recently become popular as a caching medium. Most uses to date are on the storage server side. We investigate a different structure: flash as a cache on the client side of a networked storage environment. We use trace-driven simulation to explore the design space. We consider a wide range of configurations and policies to determine the potential client-side caches might offer and how best to arrange them.
Our results show that the flash cache writeback policy does not significantly affect performance. Write-through is sufficient; this greatly simplifies cache consistency handling. We also find that the chief benefit of the flash cache is its size, not its persistence. Cache persistence of- fers additional performance benefits at system restart at essentially no runtime cost. Finally, for some workloads a large flash cache allows using miniscule amounts of RAM for file caching (e.g., 256 KB) leaving more mem- ory available for application use.
PDF Slides (PDF)
Abstract
Most provenance capture takes place inside particular tools – a workflow engine, a database, an operating system, or an application. However, most users have an existing toolset – a collection of different tools that work well for their needs and with which they are comfortable. Currently, such users have limited ability to collect provenance without disrupting their work and changing environments, which most users are hesitant to do. Even users who are willing to adopt new tools, may realize limited benefit from provenance in those tools if they do not integrate with their entire environment, which may include multiple languages and frameworks. We present the Core Provenance Library (CPL), a portable, multi-lingual library that application programmers can easily incorporate into a variety of tools to collect and integrate provenance. Although the manual instrumentation adds extra work for application programmers, we show that in most cases, the work is minimal, and the resulting system solves several problems that plague more constrained provenance collection systems. PDF Slides (PDF)
Most provenance capture takes place inside particular tools – a workflow engine, a database, an operating system, or an application. However, most users have an existing toolset – a collection of different tools that work well for their needs and with which they are comfortable. Currently, such users have limited ability to collect provenance without disrupting their work and changing environments, which most users are hesitant to do. Even users who are willing to adopt new tools, may realize limited benefit from provenance in those tools if they do not integrate with their entire environment, which may include multiple languages and frameworks. We present the Core Provenance Library (CPL), a portable, multi-lingual library that application programmers can easily incorporate into a variety of tools to collect and integrate provenance. Although the manual instrumentation adds extra work for application programmers, we show that in most cases, the work is minimal, and the resulting system solves several problems that plague more constrained provenance collection systems. PDF Slides (PDF)
Abstract
While there has been a great deal of research on provenance systems, there has been little discussion about challenges that arise when making different provenance systems interoperate. In fact, most of the literature focuses on provenance systems in isolation and does not discuss interoperability – what it means, its requirements, and how to achieve it. We designed the Provenance-Aware Storage System to be a general- purpose substrate on top of which it would be “easy” to add other provenance-aware systems in a way that would provide “seamless integration” for the provenance captured at each level. While the system did exactly what we wanted on toy problems, when we began integrating StarFlow, a Python-based workflow/provenance system, we discovered that integration is far trickier and more subtle than anyone has suggested in the literature. This work describes our experience undertaking the integration of StarFlow and PASS, identifying several important additions to existing provenance models necessary for interoperability among provenance systems.
PDF Slides (PDF)
While there has been a great deal of research on provenance systems, there has been little discussion about challenges that arise when making different provenance systems interoperate. In fact, most of the literature focuses on provenance systems in isolation and does not discuss interoperability – what it means, its requirements, and how to achieve it. We designed the Provenance-Aware Storage System to be a general- purpose substrate on top of which it would be “easy” to add other provenance-aware systems in a way that would provide “seamless integration” for the provenance captured at each level. While the system did exactly what we wanted on toy problems, when we began integrating StarFlow, a Python-based workflow/provenance system, we discovered that integration is far trickier and more subtle than anyone has suggested in the literature. This work describes our experience undertaking the integration of StarFlow and PASS, identifying several important additions to existing provenance models necessary for interoperability among provenance systems.
PDF Slides (PDF)
Abstract
Provenance systems can produce enormous provenance graphs that can be used for a variety of tasks from deter- mining the inputs to a particular process to debugging entire workflow executions or tracking difficult-to-find dependencies. Visualization can be a useful tool to sup- port such tasks, but graphs of such scale (thousands to millions of nodes) are notoriously difficult to visualize. This paper presents the Provenance Map Orbiter, a tool for interactively exploring large provenance graphs using graph summarization and semantic zoom. It presents its users with a high-level abstracted view of the graph and the ability to incrementally drill down to the details.
PDF
Provenance systems can produce enormous provenance graphs that can be used for a variety of tasks from deter- mining the inputs to a particular process to debugging entire workflow executions or tracking difficult-to-find dependencies. Visualization can be a useful tool to sup- port such tasks, but graphs of such scale (thousands to millions of nodes) are notoriously difficult to visualize. This paper presents the Provenance Map Orbiter, a tool for interactively exploring large provenance graphs using graph summarization and semantic zoom. It presents its users with a high-level abstracted view of the graph and the ability to incrementally drill down to the details.
Abstract
The Provenance Aware Storage Systems project (PASS) currently collects system-level provenance by intercepting system calls in the Linux kernel and storing the provenance in a stackable filesystem. While this approach is reasonably efficient, it suffers from two significant drawbacks: each new revision of the kernel requires reintegration of PASS changes, the stability of which must be continually tested; also, the use of a stackable filesystem makes it difficult to collect provenance on root volumes, especially during early boot. In this paper we describe an approach to collecting system-level provenance from virtual guest machines running under the Xen hypervisor. We make the case that our approach alleviates the aforementioned difficulties and promotes adoption of provenance collection within cloud comput- ing platforms.
PDF Slides (PDF)
The Provenance Aware Storage Systems project (PASS) currently collects system-level provenance by intercepting system calls in the Linux kernel and storing the provenance in a stackable filesystem. While this approach is reasonably efficient, it suffers from two significant drawbacks: each new revision of the kernel requires reintegration of PASS changes, the stability of which must be continually tested; also, the use of a stackable filesystem makes it difficult to collect provenance on root volumes, especially during early boot. In this paper we describe an approach to collecting system-level provenance from virtual guest machines running under the Xen hypervisor. We make the case that our approach alleviates the aforementioned difficulties and promotes adoption of provenance collection within cloud comput- ing platforms.
PDF Slides (PDF)
Abstract
Processor-level dynamic thermal management techniques have long targeted worst-case thermal margins. We examine the thermal-performance trade-offs in average-case, preventive thermal management by actively degrading application performance to achieve long-term thermal control. We propose Dimetrodon, the use of idle cycle injection, a flexible, per-thread technique, as a preventive thermal management mechanism and demonstrate its efficiency compared to hardware techniques in a commodity operating system on real hardware under throughput and latency-sensitive real-world workloads. Compared to hardware techniques that also lack flexibility, Dimetrodon achieves favorable trade-offs for temperature reductions up to 30% due to rapid heat dissipation during short idle intervals.
PDF
Processor-level dynamic thermal management techniques have long targeted worst-case thermal margins. We examine the thermal-performance trade-offs in average-case, preventive thermal management by actively degrading application performance to achieve long-term thermal control. We propose Dimetrodon, the use of idle cycle injection, a flexible, per-thread technique, as a preventive thermal management mechanism and demonstrate its efficiency compared to hardware techniques in a commodity operating system on real hardware under throughput and latency-sensitive real-world workloads. Compared to hardware techniques that also lack flexibility, Dimetrodon achieves favorable trade-offs for temperature reductions up to 30% due to rapid heat dissipation during short idle intervals.
Abstract
The quality of file system benchmarking has not improved in over a decade of intense research spanning hundreds of publications. Researchers repeatedly use a wide range of poorly designed benchmarks, and in most cases, develop their own ad-hoc benchmarks. Our community lacks a definition of what we want to benchmark in a file system. We propose several dimensions of file system benchmarking and review the wide range of tools and techniques in widespread use. We experimentally show that even the simplest of benchmarks can be fragile, producing performance results spanning orders of magnitude. It is our hope that this paper will spur serious debate in our community, leading to action that can improve how we evaluate our file and storage systems.
PDF
The quality of file system benchmarking has not improved in over a decade of intense research spanning hundreds of publications. Researchers repeatedly use a wide range of poorly designed benchmarks, and in most cases, develop their own ad-hoc benchmarks. Our community lacks a definition of what we want to benchmark in a file system. We propose several dimensions of file system benchmarking and review the wide range of tools and techniques in widespread use. We experimentally show that even the simplest of benchmarks can be fragile, producing performance results spanning orders of magnitude. It is our hope that this paper will spur serious debate in our community, leading to action that can improve how we evaluate our file and storage systems.
Abstract
Upcoming multicore processors, with hundreds of cores or more in a single chip, require a degree of parallel scalability that is not currently available in today’s system software. Based on prior experience in the supercomputing sector, the likely trend for multicore processors is away from shared memory and toward sharednothing architectures based on message passing. In light of this, the lightweight messages and channels programming model, found among other places in Erlang, is likely the best way forward. This paper discusses what adopting this model entails, describes the architecture of an OS based on this model, and outlines a few likely implementation challenges.
PDF Slides (PDF)
Upcoming multicore processors, with hundreds of cores or more in a single chip, require a degree of parallel scalability that is not currently available in today’s system software. Based on prior experience in the supercomputing sector, the likely trend for multicore processors is away from shared memory and toward sharednothing architectures based on message passing. In light of this, the lightweight messages and channels programming model, found among other places in Erlang, is likely the best way forward. This paper discusses what adopting this model entails, describes the architecture of an OS based on this model, and outlines a few likely implementation challenges.
PDF Slides (PDF)
Abstract
As the prevalence of blogs, discussion forums, and online news services continues to grow, so too does the portion of this Web content that relates to health and medicine. We propose that everyday, medically-oriented Web content is a valuable and viable data source for medical hypothesis generation and testing, despite its being noisy. In this paper, we present a proof-of-concept system supporting this notion. We construct a corpus comprising news articles relating to the drugs Vioxx, Naproxen and Ibuprofen, that were published between 1998-2002. Using this corpus, we show that there was a significant link between Vioxx and the concept “Myocardial Infarction” well before the drug was withdrawn from the market in 2004. Indeed, within the Vioxx-related content, the concept ranks amongst the top 3.3% in terms of importance. When compared with the Naproxen and Ibuprofen control literatures, the term occurs significantly more frequently in the Vioxx- related content.
PDF
As the prevalence of blogs, discussion forums, and online news services continues to grow, so too does the portion of this Web content that relates to health and medicine. We propose that everyday, medically-oriented Web content is a valuable and viable data source for medical hypothesis generation and testing, despite its being noisy. In this paper, we present a proof-of-concept system supporting this notion. We construct a corpus comprising news articles relating to the drugs Vioxx, Naproxen and Ibuprofen, that were published between 1998-2002. Using this corpus, we show that there was a significant link between Vioxx and the concept “Myocardial Infarction” well before the drug was withdrawn from the market in 2004. Indeed, within the Vioxx-related content, the concept ranks amongst the top 3.3% in terms of importance. When compared with the Naproxen and Ibuprofen control literatures, the term occurs significantly more frequently in the Vioxx- related content.
Abstract
Many file systems reorganize data on disk, for example to defragment storage, shrink volumes, or migrate data between different classes of storage. Advanced file system features such as snapshots, writable clones, and deduplication make these tasks complicated, as moving a single block may require finding and updating dozens, or even hundreds, of pointers to it.
We present Backlog, an efficient implementation of explicit back references, to address this problem. Back references are file system meta-data that map physical block numbers to the data objects that use them. We show that by using LSM-Trees and exploiting the write-anywhere behavior of modern file systems such as NetApp R WAFL R or btrfs, we can maintain back reference meta-data with minimal overhead (one extra disk I/O per 102 block operations) and provide excel- lent query performance for the common case of queries covering ranges of physically adjacent blocks.
PDF
Many file systems reorganize data on disk, for example to defragment storage, shrink volumes, or migrate data between different classes of storage. Advanced file system features such as snapshots, writable clones, and deduplication make these tasks complicated, as moving a single block may require finding and updating dozens, or even hundreds, of pointers to it.
We present Backlog, an efficient implementation of explicit back references, to address this problem. Back references are file system meta-data that map physical block numbers to the data objects that use them. We show that by using LSM-Trees and exploiting the write-anywhere behavior of modern file systems such as NetApp R WAFL R or btrfs, we can maintain back reference meta-data with minimal overhead (one extra disk I/O per 102 block operations) and provide excel- lent query performance for the common case of queries covering ranges of physically adjacent blocks.
Abstract
The cloud is poised to become the next computing environment for both data storage and computation due to its pay-as-you-go and provision-as-you-go models. Cloud storage is already being used to back up desktop user data, host shared scientific data, store web application data, and to serve web pages. Today's cloud stores, however, are missing an important ingredient: provenance.
Provenance is metadata that describes the history of an object. We make the case that provenance is crucial for data stored on the cloud and identify the properties of provenance that enable its utility. We then examine current cloud offerings and design and implement three protocols for maintaining data/provenance in current cloud stores. The protocols represent different points in the de- sign space and satisfy different subsets of the provenance properties. Our evaluation indicates that the overheads of all three protocols are comparable to each other and reasonable in absolute terms. Thus, one can select a protocol based upon the properties it provides without sacrificing performance. While it is feasible to provide provenance as a layer on top of today's cloud offerings, we conclude by presenting the case for incorporating provenance as a core cloud feature, discussing the issues in doing so.
PDF
The cloud is poised to become the next computing environment for both data storage and computation due to its pay-as-you-go and provision-as-you-go models. Cloud storage is already being used to back up desktop user data, host shared scientific data, store web application data, and to serve web pages. Today's cloud stores, however, are missing an important ingredient: provenance.
Provenance is metadata that describes the history of an object. We make the case that provenance is crucial for data stored on the cloud and identify the properties of provenance that enable its utility. We then examine current cloud offerings and design and implement three protocols for maintaining data/provenance in current cloud stores. The protocols represent different points in the de- sign space and satisfy different subsets of the provenance properties. Our evaluation indicates that the overheads of all three protocols are comparable to each other and reasonable in absolute terms. Thus, one can select a protocol based upon the properties it provides without sacrificing performance. While it is feasible to provide provenance as a layer on top of today's cloud offerings, we conclude by presenting the case for incorporating provenance as a core cloud feature, discussing the issues in doing so.
Abstract
We describe our experiences importing PASS provenance into PLUS. Although both systems import and export provenance that conforms to the Open Provenance Model (OPM), the two systems vary greatly with respect to the granularity of provenance captured, how much semantic knowledge the system contributes, and the completeness of provenance capture. We encountered several problems reconciling provenance between the two systems and use that experience to specify a Common Provenance Framework, that provides a higher degree of interoperability between provenance systems. In each case, the problems stem from the fact that OPM interoperability is a weaker requirement than query interoperability. Our goal in presenting this work is to generate discussion about differing degrees of interoperability and the requirements thereof.
PDF Slides (PDF)
We describe our experiences importing PASS provenance into PLUS. Although both systems import and export provenance that conforms to the Open Provenance Model (OPM), the two systems vary greatly with respect to the granularity of provenance captured, how much semantic knowledge the system contributes, and the completeness of provenance capture. We encountered several problems reconciling provenance between the two systems and use that experience to specify a Common Provenance Framework, that provides a higher degree of interoperability between provenance systems. In each case, the problems stem from the fact that OPM interoperability is a weaker requirement than query interoperability. Our goal in presenting this work is to generate discussion about differing degrees of interoperability and the requirements thereof.
PDF Slides (PDF)
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
Abstract
Science, industry, and society are being revolutionized by radical new capabilities for information sharing, distributed computation, and collaboration offered by the World Wide Web. This revolution promises dramatic benefits but also poses serious risks due to the fluid nature of digital information. One important cross-cutting issue is managing and recording provenance, or metadata about the origin, context, or history of data. We posit that provenance will play a central role in emerging advanced digital infrastructures. In this paper, we outline the current state of provenance research and practice, identify hard open research problems involving provenance semantics, formal modeling, and security, and articulate a vision for the future of provenance.
PDF
Science, industry, and society are being revolutionized by radical new capabilities for information sharing, distributed computation, and collaboration offered by the World Wide Web. This revolution promises dramatic benefits but also poses serious risks due to the fluid nature of digital information. One important cross-cutting issue is managing and recording provenance, or metadata about the origin, context, or history of data. We posit that provenance will play a central role in emerging advanced digital infrastructures. In this paper, we outline the current state of provenance research and practice, identify hard open research problems involving provenance semantics, formal modeling, and security, and articulate a vision for the future of provenance.
Abstract
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
PDF
Digital provenance is meta-data that describes the ancestry or history of a digital object. Most work on provenance focuses on how provenance increases the value of data to consumers. However, provenance is also valuable to storage providers. For example, provenance can provide hints on access patterns, detect anomalous behavior, and provide enhanced user search capabilities. As the next generation storage providers, cloud vendors are in the unique position to capitalize on this opportunity to incorporate provenance as a fundamental storage system primitive. To date, cloud offerings have not yet done so. We provide motivation for providers to treat provenance as first class data in the cloud and based on our experience with provenance in a local storage system, suggest a set of requirements that make provenance feasible and attractive.
Abstract
Digital provenance describes the ancestry or history of a digital object. Most existing provenance systems, however, operate at only one level of abstraction: the system call layer, a workflow specification, or the high-level constructs of a particular application. The provenance collectable in each of these layers is different, and all of it can be important. Single-layer systems fail to account for the different levels of abstraction at which users need to reason about their data and processes. These systems cannot integrate data provenance across layers and cannot answer questions that require an integrated view of the provenance.
We have designed a provenance collection structure facilitating the integration of provenance across multiple levels of abstraction, including a workflow engine, a web browser, and an initial runtime Python provenance tracking wrapper. We layer these components atop provenance-aware network storage (NFS) that builds upon a Provenance-Aware Storage System (PASS). We discuss the challenges of building systems that integrate provenance across multiple layers of abstraction, present how we augmented systems in each layer to integrate provenance, and present use cases that demonstrate how provenance spanning multiple layers provides functionality not available in existing systems. Our evaluation shows that the overheads imposed by layering provenance systems are reasonable.
HTML PDF Slides (PDF)
Digital provenance describes the ancestry or history of a digital object. Most existing provenance systems, however, operate at only one level of abstraction: the system call layer, a workflow specification, or the high-level constructs of a particular application. The provenance collectable in each of these layers is different, and all of it can be important. Single-layer systems fail to account for the different levels of abstraction at which users need to reason about their data and processes. These systems cannot integrate data provenance across layers and cannot answer questions that require an integrated view of the provenance.
We have designed a provenance collection structure facilitating the integration of provenance across multiple levels of abstraction, including a workflow engine, a web browser, and an initial runtime Python provenance tracking wrapper. We layer these components atop provenance-aware network storage (NFS) that builds upon a Provenance-Aware Storage System (PASS). We discuss the challenges of building systems that integrate provenance across multiple layers of abstraction, present how we augmented systems in each layer to integrate provenance, and present use cases that demonstrate how provenance spanning multiple layers provides functionality not available in existing systems. Our evaluation shows that the overheads imposed by layering provenance systems are reasonable.
HTML PDF Slides (PDF)
Abstract
For over forty years, we have assumed hierarchical file system namespaces. These namespaces were a rudimentary attempt at simple organization. As users have begun to interact with increasing amounts of data and are increasingly demanding search capability, such a simple hierarchical model has outlasted its usefulness. For this reason, we should design file systems whose organizations map to the ways we access and manipulate data now. We present a new file system architecture in which we replace the hierarchical namespace with a tagged, search-based one.
PDF Slides (PDF)
For over forty years, we have assumed hierarchical file system namespaces. These namespaces were a rudimentary attempt at simple organization. As users have begun to interact with increasing amounts of data and are increasingly demanding search capability, such a simple hierarchical model has outlasted its usefulness. For this reason, we should design file systems whose organizations map to the ways we access and manipulate data now. We present a new file system architecture in which we replace the hierarchical namespace with a tagged, search-based one.
PDF Slides (PDF)
Abstract
We describe a new operating system scheduling algorithm that improves performance isolation on chip multiprocessors (CMP). Poor performance isolation occurs when an application’s performance is determined by the behaviour of its co-runners, i.e., other applications simultaneously running with it. This performance dependency is caused by unfair, co- runner-dependent cache allocation on CMPs. Poor performance isolation interferes with the operating system’s control over priority enforcement and hinders QoS provisioning. Previous solutions required modifications to the hardware. We present a new software solution. Our cache-fair algorithm ensures that the application runs as quickly as it would under fair cache allocation, regardless of how the cache is actually allocated. If the thread executes fewer instructions per cycle than it would under fair cache allocation, the scheduler increases that thread’s CPU timeslice. This way, the thread’s overall performance does not suffer because it is allowed to use the CPU longer. We describe our implementation of the algorithm in SolarisTM 10, and show that it significantly improves performance isolation for SPEC CPU, SPEC JBB and TPC-C.
PDF
We describe a new operating system scheduling algorithm that improves performance isolation on chip multiprocessors (CMP). Poor performance isolation occurs when an application’s performance is determined by the behaviour of its co-runners, i.e., other applications simultaneously running with it. This performance dependency is caused by unfair, co- runner-dependent cache allocation on CMPs. Poor performance isolation interferes with the operating system’s control over priority enforcement and hinders QoS provisioning. Previous solutions required modifications to the hardware. We present a new software solution. Our cache-fair algorithm ensures that the application runs as quickly as it would under fair cache allocation, regardless of how the cache is actually allocated. If the thread executes fewer instructions per cycle than it would under fair cache allocation, the scheduler increases that thread’s CPU timeslice. This way, the thread’s overall performance does not suffer because it is allowed to use the CPU longer. We describe our implementation of the algorithm in SolarisTM 10, and show that it significantly improves performance isolation for SPEC CPU, SPEC JBB and TPC-C.
Abstract
Network coordinates provide a mechanism for selecting and placing servers efficiently in a large distributed system. This approach works well as long as the coordinates continue to accurately reflect network topology. We conducted a long-term study of a subset of a million-plus node coordinate system and found that it exhibited some of the problems for which network coordinates are frequently criticized, for example, inaccuracy and fragility in the presence of violations of the triangle inequality. Fortunately, we show that several simple techniques remedy many of these problems. Using the Azureus BitTorrent network as our testbed, we show that live, large-scale network coordinate systems behave differently than their tame PlanetLab and simulation-based counterparts. We find higher relative errors, more triangle inequality violations, and higher churn. We present and evaluate a number of techniques that, when applied to Azureus, efficiently produce accurate and stable network coordinates
HTML PDF
Network coordinates provide a mechanism for selecting and placing servers efficiently in a large distributed system. This approach works well as long as the coordinates continue to accurately reflect network topology. We conducted a long-term study of a subset of a million-plus node coordinate system and found that it exhibited some of the problems for which network coordinates are frequently criticized, for example, inaccuracy and fragility in the presence of violations of the triangle inequality. Fortunately, we show that several simple techniques remedy many of these problems. Using the Azureus BitTorrent network as our testbed, we show that live, large-scale network coordinate systems behave differently than their tame PlanetLab and simulation-based counterparts. We find higher relative errors, more triangle inequality violations, and higher churn. We present and evaluate a number of techniques that, when applied to Azureus, efficiently produce accurate and stable network coordinates
HTML PDF
Abstract
A Provenance-Aware Storage System (PASS) is a storage system that automatically collects and maintains prove- nance or lineage, the complete history or ancestry of an item. We discuss the advantages of treating provenance as meta-data collected and maintained by the storage system, rather than as manual annotations stored in a separately administered database. We describe a PASS implementation, discussing the challenges it presents, performance cost it incurs, and the new functionality it enables. We show that with reasonable overhead, we can provide useful functionality not available in today's file systems or provenance management systems.
HTML PDF
A Provenance-Aware Storage System (PASS) is a storage system that automatically collects and maintains prove- nance or lineage, the complete history or ancestry of an item. We discuss the advantages of treating provenance as meta-data collected and maintained by the storage system, rather than as manual annotations stored in a separately administered database. We describe a PASS implementation, discussing the challenges it presents, performance cost it incurs, and the new functionality it enables. We show that with reasonable overhead, we can provide useful functionality not available in today's file systems or provenance management systems.
HTML PDF
Abstract
Automatic provenance collection describes systems that observe processes and data transformations inferring, collecting, and maintaining provenance about them. Automatic collection is a powerful tool for analysis of ob jects and processes, providing a level of transparency and pervasiveness not found in more conventional provenance systems. Unfortunately, automatic collection is also difficult. We discuss the challenges we encountered and the issues we exposed as we developed an automatic provenance collector that runs at the operating system level.
PDF
Automatic provenance collection describes systems that observe processes and data transformations inferring, collecting, and maintaining provenance about them. Automatic collection is a powerful tool for analysis of ob jects and processes, providing a level of transparency and pervasiveness not found in more conventional provenance systems. Unfortunately, automatic collection is also difficult. We discuss the challenges we encountered and the issues we exposed as we developed an automatic provenance collector that runs at the operating system level.
Abstract
The Egg project provides a vision and implementation of how heterogeneous computational requirements will be supported within a single grid and a compelling reason to explain why computational grids will thrive. Environment computing, which allows a user to specify properties that a compute environment must satisfy in order to support the users computation, provides a how. Economic principles, allowing resource owners, users, and other stakeholders to make value and policy statements, provides a why. The Egg project introduces a language for defining software environments (egg shell), a general type for grid objects (the cache), and a currency (the egg). The Egg platform resembles an economically driven Internet-wide Unix system with egg shell playing the role of a scripting language and caches playing the role of a global file system, including an initial collection of devices.
PDF Slides (PDF)
The Egg project provides a vision and implementation of how heterogeneous computational requirements will be supported within a single grid and a compelling reason to explain why computational grids will thrive. Environment computing, which allows a user to specify properties that a compute environment must satisfy in order to support the users computation, provides a how. Economic principles, allowing resource owners, users, and other stakeholders to make value and policy statements, provides a why. The Egg project introduces a language for defining software environments (egg shell), a general type for grid objects (the cache), and a currency (the egg). The Egg platform resembles an economically driven Internet-wide Unix system with egg shell playing the role of a scripting language and caches playing the role of a global file system, including an initial collection of devices.
PDF Slides (PDF)
Abstract
To use their pool of resources efficiently, distributed stream-processing systems push query operators to nodes within the network. Currently, these operators, ranging from simple filters to custom business logic, are placed manually at intermediate nodes along the transmission path to meet application-specific performance goals. Determining placement locations is challenging because network and node conditions change over time and because streams may interact with each other, opening venues for reuse and repositioning of operators.
This paper describes a stream-based overlay network (SBON), a layer between a stream-processing system and the physical network that manages operator placement for stream-processing systems. Our design is based on a cost space, an abstract representation of the network and on-going streams, which permits decentralized, large-scale multi-query optimization decisions. We present an evaluation of the SBON approach through simulation, experiments on PlanetLab, and an integration with Borealis, an existing stream-processing engine. Our results show that an SBON consistently improves network utilization, provides low stream latency, and enables dynamic optimization at low engineering cost.
PDF
This paper describes a stream-based overlay network (SBON), a layer between a stream-processing system and the physical network that manages operator placement for stream-processing systems. Our design is based on a cost space, an abstract representation of the network and on-going streams, which permits decentralized, large-scale multi-query optimization decisions. We present an evaluation of the SBON approach through simulation, experiments on PlanetLab, and an integration with Borealis, an existing stream-processing engine. Our results show that an SBON consistently improves network utilization, provides low stream latency, and enables dynamic optimization at low engineering cost.
Abstract
Large-scale distributed applications need latency information to make network-aware routing decisions. Collecting these measurements, however, can impose a high burden. Network coordinates are a scalable and efficient way to supply nodes with up-to-date latency estimates. We present our experience of maintaining network coordinates on PlanetLab. We present two different APIs for accessing coordinates: a per-application library, which takes advantage of application-level traffic, and a stand-alone service, which is shared across applications. Our results show that statistical filtering of latency samples improves accuracy and stability and that a small number of neighbors is sufficient when updating coordinates.
PDF
Large-scale distributed applications need latency information to make network-aware routing decisions. Collecting these measurements, however, can impose a high burden. Network coordinates are a scalable and efficient way to supply nodes with up-to-date latency estimates. We present our experience of maintaining network coordinates on PlanetLab. We present two different APIs for accessing coordinates: a per-application library, which takes advantage of application-level traffic, and a stand-alone service, which is shared across applications. Our results show that statistical filtering of latency samples improves accuracy and stability and that a small number of neighbors is sufficient when updating coordinates.
Abstract
This article discusses how data management needs vary across applications, pointing out that one needs to match database solutions with data management needs.
PDF
This article discusses how data management needs vary across applications, pointing out that one needs to match database solutions with data management needs.
Abstract
We investigated how operating system design should be adapted for multithreaded chip multiprocessors (CMT) -- a new generation of processors that exploit thread-level parallelism to mask the memory latency in modern workloads. We determined that the L2 cache is a critical shared resource on CMT and that an insufficient amount of L2 cache can undermine the ability to hide memory latency on these processors. To use the L2 cache as efficiently as possible, we propose an L2-conscious scheduling algorithm and quantify its performance potential. Using this algorithm it is possible to reduce miss ratios in the L2 cache by 25-37% and improve processor throughput by 27-45%.
PDF
We investigated how operating system design should be adapted for multithreaded chip multiprocessors (CMT) -- a new generation of processors that exploit thread-level parallelism to mask the memory latency in modern workloads. We determined that the L2 cache is a critical shared resource on CMT and that an insufficient amount of L2 cache can undermine the ability to hide memory latency on these processors. To use the L2 cache as efficiently as possible, we propose an L2-conscious scheduling algorithm and quantify its performance potential. Using this algorithm it is possible to reduce miss ratios in the L2 cache by 25-37% and improve processor throughput by 27-45%.
Abstract
Distributed stream-based applications, such as continuous query systems, have network scale and time characteristics that challenge traditional distributed query optimization. The optimization sub-problems of plan generation and service placement should be integrated to meet these challenges. These tasks have typically been treated as independent sub-problems because of the complexity of their integration. We suggest cost spaces as one way to mitigate this complexity. We further consider how cost spaces can be used to allow tractable multi-query optimization.
PDF
Distributed stream-based applications, such as continuous query systems, have network scale and time characteristics that challenge traditional distributed query optimization. The optimization sub-problems of plan generation and service placement should be integrated to meet these challenges. These tasks have typically been treated as independent sub-problems because of the complexity of their integration. We suggest cost spaces as one way to mitigate this complexity. We further consider how cost spaces can be used to allow tractable multi-query optimization.
Abstract
Sensor network data has both historical and real-time value. Making historical sensor data useful, in particular, requires storage, naming, and indexing. Sensor data presents new challenges in these areas. Such data is location-specific but also distributed; it is collected in a particular physical location and may be most useful there, but it has additional value when com- bined with other sensor data collections in a larger distributed sys- tem. Thus, arranging location-sensitive peer-to-peer storage is one challenge. Sensor data sets do not have obvious names, so naming them in a globally useful fashion is another challenge. The last challenge arises from the need to index these sensor data sets to make them searchable. The key to sensor data identity is prove- nance, the full history or lineage of the data. We show how prove- nance addresses the naming and indexing issues and then present a research agenda for constructing distributed, indexed repositories of sensor data.
PDF Slides (PDF)
Sensor network data has both historical and real-time value. Making historical sensor data useful, in particular, requires storage, naming, and indexing. Sensor data presents new challenges in these areas. Such data is location-specific but also distributed; it is collected in a particular physical location and may be most useful there, but it has additional value when com- bined with other sensor data collections in a larger distributed sys- tem. Thus, arranging location-sensitive peer-to-peer storage is one challenge. Sensor data sets do not have obvious names, so naming them in a globally useful fashion is another challenge. The last challenge arises from the need to index these sensor data sets to make them searchable. The key to sensor data identity is prove- nance, the full history or lineage of the data. We show how prove- nance addresses the naming and indexing issues and then present a research agenda for constructing distributed, indexed repositories of sensor data.
PDF Slides (PDF)
Abstract
Numerous proposals exist for load balancing in peer-to-peer (p2p) networks. Some focus on namespace balancing, making the distance between nodes as uniform as possible. This technique works well under ideal conditions, but not under those found empirically. Instead, researchers have found heavy-tailed query distributions (skew), high rates of node join and leave (churn), and wide variation in node network and storage capacity (heterogeneity). Other approaches tackle these less-than-ideal conditions, but give up on important security properties. We propose an algorithm that both facilitates good performance and does not dilute security. Our algorithm, k-Choices, achieves load balance by greedily matching nodes' target workloads with actual applied workloads through limited sampling, and limits any fundamental decrease in security by basing each node's set of potential identifiers on a single certificate. Our algorithm compares favorably to four others in trace-driven simulations. We have implemented our algorithm and found that it improved aggregate throughput by 20% in a widely heterogeneous system in our experiments.
PDF Slides (PDF)
Numerous proposals exist for load balancing in peer-to-peer (p2p) networks. Some focus on namespace balancing, making the distance between nodes as uniform as possible. This technique works well under ideal conditions, but not under those found empirically. Instead, researchers have found heavy-tailed query distributions (skew), high rates of node join and leave (churn), and wide variation in node network and storage capacity (heterogeneity). Other approaches tackle these less-than-ideal conditions, but give up on important security properties. We propose an algorithm that both facilitates good performance and does not dilute security. Our algorithm, k-Choices, achieves load balance by greedily matching nodes' target workloads with actual applied workloads through limited sampling, and limits any fundamental decrease in security by basing each node's set of potential identifiers on a single certificate. Our algorithm compares favorably to four others in trace-driven simulations. We have implemented our algorithm and found that it improved aggregate throughput by 20% in a widely heterogeneous system in our experiments.
PDF Slides (PDF)
Abstract
Stream-based overlay networks (SBONs) are one approach to implementing large-scale stream processing systems. A fundamental consideration in an SBON is that of service placement, which determines the physical location of in-network processing services or operators, in such a way that network resources are used efficiently. Service placement consists of two components: node discovery, which selects a candidate set of nodes on which services might be placed, and node selection, which chooses the particular node to host a service. By viewing the placement problem as the composition of these two processes we can trade-off quality and efficiency between them. A bad discovery scheme can yield a good placement, but at the cost of an expensive selection mechanism.
Recent work on operator placement proposes to leverage routing paths in a distributed hash table (DHT) to obtain a set of candidate nodes for service placement. We evaluate the appropriateness of using DHT routing paths for service placement in an SBON, when aiming to minimize network usage. For this, we consider two DHT-based algorithms for node discovery, which use either the union or intersection of DHT routing paths in the SBON, and compare their performance to other techniques. We show that current DHT-based schemes are actually rather poor node discovery algorithms, when minimizing network utilization. An efficient DHT may not traverse enough hops to obtain a sufficiently large candidate set for placement. The union of DHT routes may result in a low-quality set of discovered nodes that requires an expensive node selection algorithm. Finally, the intersection of DHT routes relies on route convergence, which prevents the placement of services with a large fan-in.
PDF
Stream-based overlay networks (SBONs) are one approach to implementing large-scale stream processing systems. A fundamental consideration in an SBON is that of service placement, which determines the physical location of in-network processing services or operators, in such a way that network resources are used efficiently. Service placement consists of two components: node discovery, which selects a candidate set of nodes on which services might be placed, and node selection, which chooses the particular node to host a service. By viewing the placement problem as the composition of these two processes we can trade-off quality and efficiency between them. A bad discovery scheme can yield a good placement, but at the cost of an expensive selection mechanism.
Recent work on operator placement proposes to leverage routing paths in a distributed hash table (DHT) to obtain a set of candidate nodes for service placement. We evaluate the appropriateness of using DHT routing paths for service placement in an SBON, when aiming to minimize network usage. For this, we consider two DHT-based algorithms for node discovery, which use either the union or intersection of DHT routing paths in the SBON, and compare their performance to other techniques. We show that current DHT-based schemes are actually rather poor node discovery algorithms, when minimizing network utilization. An efficient DHT may not traverse enough hops to obtain a sufficiently large candidate set for placement. The union of DHT routes may result in a low-quality set of discovered nodes that requires an expensive node selection algorithm. Finally, the intersection of DHT routes relies on route convergence, which prevents the placement of services with a large fan-in.
Abstract
System security as it is practiced today is a losing battle. In this paper, we outline a possible comprehensive solution for binary-based attacks, using virtual machines, machine descriptions, and randomization to achieve broad heterogeneity at the machine level. This heterogeneity increases the "cost" of broad-based binary attacks to a sufficiently high level that they cease to become feasible. The convergence of several recent technologies appears to make our approach achievable at a reasonable cost, with only moderate run-time overhead.
PDF Slides (PDF)
System security as it is practiced today is a losing battle. In this paper, we outline a possible comprehensive solution for binary-based attacks, using virtual machines, machine descriptions, and randomization to achieve broad heterogeneity at the machine level. This heterogeneity increases the "cost" of broad-based binary attacks to a sufficiently high level that they cease to become feasible. The convergence of several recent technologies appears to make our approach achievable at a reasonable cost, with only moderate run-time overhead.
PDF Slides (PDF)
Abstract
Research in sensor networks, continuous queries (CQ), and other domains has been motivated by powerful applications that aim to aggregate, assimilate, and interact with scores of sensor networks in parallel. Numerous system ingredients are necessary to make these applications possible. Sensor network research is building some of these components from the bottom up, dealing with issues such as wireless connectivity and battery life. CQ, peer-to-peer (P2P), and other research areas are building top down, examining in-network services, naming, decentralized queries, and scale. While many research groups use the same types of applications to motivate their work, many of these applications cannot be built today because of missing bridge research. These challenges include: uniting vastly differing devices and services, managing intermittent connectivity, placing in-network services with QoS and other constraints, developing unified security models, and correlating between sensor networks. This paper distills these new problems and outlines one proposed system that explores solutions to these concerns.
PDF
Research in sensor networks, continuous queries (CQ), and other domains has been motivated by powerful applications that aim to aggregate, assimilate, and interact with scores of sensor networks in parallel. Numerous system ingredients are necessary to make these applications possible. Sensor network research is building some of these components from the bottom up, dealing with issues such as wireless connectivity and battery life. CQ, peer-to-peer (P2P), and other research areas are building top down, examining in-network services, naming, decentralized queries, and scale. While many research groups use the same types of applications to motivate their work, many of these applications cannot be built today because of missing bridge research. These challenges include: uniting vastly differing devices and services, managing intermittent connectivity, placing in-network services with QoS and other constraints, developing unified security models, and correlating between sensor networks. This paper distills these new problems and outlines one proposed system that explores solutions to these concerns.
Abstract
The unpredictable nature of modern workloads, characterized by frequent branches and control transfers, can result in processor pipeline utilization as low as 19%. Chip multithreading (CMT), a processor architecture combining chip multiprocessing and hardware multithreading, is designed to address this issue. Hardware vendors plan to ship CMT systems within the next two years; understanding how such systems will perform is crucial if we are to use them to full advantage.
Our simulation experiments show that a CMT-savvy operating system scheduler could improve application performance by a factor of two. In this paper we describe our initial analysis of application performance on CMT systems and propose a design for a scheduler tailored for the needs of a CMT system.
PDF
The unpredictable nature of modern workloads, characterized by frequent branches and control transfers, can result in processor pipeline utilization as low as 19%. Chip multithreading (CMT), a processor architecture combining chip multiprocessing and hardware multithreading, is designed to address this issue. Hardware vendors plan to ship CMT systems within the next two years; understanding how such systems will perform is crucial if we are to use them to full advantage.
Our simulation experiments show that a CMT-savvy operating system scheduler could improve application performance by a factor of two. In this paper we describe our initial analysis of application performance on CMT systems and propose a design for a scheduler tailored for the needs of a CMT system.
Abstract
To tune and manage themselves, file and storage systems must understand key properties (e.g., access pattern, lifetime, size) of their various files. This paper describes how systems can automatically learn to classify the properties of files (e.g., read-only access pattern, short-lived, small in size) and predict the properties of new files, as they are created, by exploiting the strong associations between a file's properties and the names and attributes assigned to it. These associations exist, strongly but differently, in each of four real NFS environments studied. Decision tree classifiers can automatically identify and model such associations, providing prediction accuracies that often exceed 90%. Such predictions can be used to select storage policies (e.g., disk allocation schemes and replication factors) for individual files. Further, changes in associations can expose information about applications, helping autonomic system components distinguish growth from fundamental change.
PDF PostScript
To tune and manage themselves, file and storage systems must understand key properties (e.g., access pattern, lifetime, size) of their various files. This paper describes how systems can automatically learn to classify the properties of files (e.g., read-only access pattern, short-lived, small in size) and predict the properties of new files, as they are created, by exploiting the strong associations between a file's properties and the names and attributes assigned to it. These associations exist, strongly but differently, in each of four real NFS environments studied. Decision tree classifiers can automatically identify and model such associations, providing prediction accuracies that often exceed 90%. Such predictions can be used to select storage policies (e.g., disk allocation schemes and replication factors) for individual files. Further, changes in associations can expose information about applications, helping autonomic system components distinguish growth from fundamental change.
PDF PostScript
Abstract
Extensive research on system support for enabling I/O-intensive applications to achieve performance close to the limits imposed by the hardware suggests two main approaches: Low overhead I/O protocols and the flexibility to customize I/O policies to the needs of applications. One way to achieve both is by supporting user-level access to I/O devices, enabling user-level implementations of I/O protocols. User-level networking is an example of this approach, specific to network interface controllers (NICs). In this paper, we argue that the real key to high-performance in I/O-intensive applications is user-level file caching and user-level network buffering, both of which can be achieved without user-level access to NICs.
Avoiding the need to support user-level networking carries two important benefits for overall system design: First, a NIC exporting a privileged kernel interface is simpler to design and implement than one exporting a user-level interface. Second, the kernel is re-instated as a global system resource controller and arbitrator. We develop an analytical model of network storage applications and use it to show that their performance is not affected by the use of a kernel-based API to NICs.
PDF
Extensive research on system support for enabling I/O-intensive applications to achieve performance close to the limits imposed by the hardware suggests two main approaches: Low overhead I/O protocols and the flexibility to customize I/O policies to the needs of applications. One way to achieve both is by supporting user-level access to I/O devices, enabling user-level implementations of I/O protocols. User-level networking is an example of this approach, specific to network interface controllers (NICs). In this paper, we argue that the real key to high-performance in I/O-intensive applications is user-level file caching and user-level network buffering, both of which can be achieved without user-level access to NICs.
Avoiding the need to support user-level networking carries two important benefits for overall system design: First, a NIC exporting a privileged kernel interface is simpler to design and implement than one exporting a user-level interface. Second, the kernel is re-instated as a global system resource controller and arbitrator. We develop an analytical model of network storage applications and use it to show that their performance is not affected by the use of a kernel-based API to NICs.
Abstract
The Direct Access File System (DAFS) is a distributed file system built on top of direct-access transports (DAT). Direct- access transports are characterized by using remote direct memory access (RDMA) for data transfer and user-level networking. The motivation behind the DAT-enabled distributed file system architecture is the reduction of the CPU overhead on the I/O data path.
We have created an implementation of DAFS for the FreeBSD platform. In this paper we describe the performance evaluation study of DAFS that we have performed using this software. The goal of this study is to determine whether the architecture of DAFS brings any fundamental performance benefits to applications compared to traditional distributed file systems, such as NFS. We perform comparison of DAFS to a version of NFS optimized to reduce the I/O overhead. In order to thoroughly understand the impact of DAFS on application performance, we consider a diverse range of applications workloads.
We conclude that DAFS can accomplish superior performance for latency-sensitive applications, outperforming NFS by up to a factor of 2. Bandwidth-sensitive applications do equally well on both systems, unless they are CPU-intensive, in which case they perform better on DAFS. We also found that RDMA is a less restrictive mechanism to achieve copy avoidance than that used by the optimized NFS.
PDF
The Direct Access File System (DAFS) is a distributed file system built on top of direct-access transports (DAT). Direct- access transports are characterized by using remote direct memory access (RDMA) for data transfer and user-level networking. The motivation behind the DAT-enabled distributed file system architecture is the reduction of the CPU overhead on the I/O data path.
We have created an implementation of DAFS for the FreeBSD platform. In this paper we describe the performance evaluation study of DAFS that we have performed using this software. The goal of this study is to determine whether the architecture of DAFS brings any fundamental performance benefits to applications compared to traditional distributed file systems, such as NFS. We perform comparison of DAFS to a version of NFS optimized to reduce the I/O overhead. In order to thoroughly understand the impact of DAFS on application performance, we consider a diverse range of applications workloads.
We conclude that DAFS can accomplish superior performance for latency-sensitive applications, outperforming NFS by up to a factor of 2. Bandwidth-sensitive applications do equally well on both systems, unless they are CPU-intensive, in which case they perform better on DAFS. We also found that RDMA is a less restrictive mechanism to achieve copy avoidance than that used by the optimized NFS.
Abstract
Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF PostScript
Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF PostScript
Abstract
We describe two modifications to the FreeBSD 4.6 NFS server to increase read throughput by improving the read-ahead heuristic to deal with reordered requests and stride access patterns. We show that for some stride access patterns, our new heuristics improve end-to-end NFS throughput by nearly a factor of two. We also show that benchmarking and experimenting with changes to an NFS server can be a subtle and challenging task, and that it is often difficult to distinguish the impact of a new algorithm or heuristic from the quirks of the underlying software and hardware with which they interact. We discuss these quirks and their potential effects.
PDF PostScript Slides (PDF)
We describe two modifications to the FreeBSD 4.6 NFS server to increase read throughput by improving the read-ahead heuristic to deal with reordered requests and stride access patterns. We show that for some stride access patterns, our new heuristics improve end-to-end NFS throughput by nearly a factor of two. We also show that benchmarking and experimenting with changes to an NFS server can be a subtle and challenging task, and that it is often difficult to distinguish the impact of a new algorithm or heuristic from the quirks of the underlying software and hardware with which they interact. We discuss these quirks and their potential effects.
PDF PostScript Slides (PDF)
Abstract
We present an analysis of a pair of NFS traces of contemporary email and research workloads. We show that although the research workload resembles previously-studied workloads, the email workload is quite different. We also perform several new analyses that demonstrate the periodic nature of file system activity, the effect of out-of-order NFS calls, and the strong relationship between the name of a file and its size, lifetime, and access
PDF PostScript Slides (PDF)
We present an analysis of a pair of NFS traces of contemporary email and research workloads. We show that although the research workload resembles previously-studied workloads, the email workload is quite different. We also perform several new analyses that demonstrate the periodic nature of file system activity, the effect of out-of-order NFS calls, and the strong relationship between the name of a file and its size, lifetime, and access
PDF PostScript Slides (PDF)
Abstract
The performance of high-speed network-attached storage applications is often limited by end-system overhead, caused primarily by memory copying and network protocol processing. In this paper, we examine alternative strategies for reducing overhead in such systems. We consider optimizations to remote procedure call (RPC)-based data transfer using either remote direct memory access (RDMA) or network interface support for pre-posting of application receive buffers. We demonstrate that both mechanisms enable file access throughput that saturates a 2Gb/s network link when performing large I/Os on relatively slow, commodity PCs. However, for multi-client workloads dominated by small I/Os, throughput is limited by the per-I/O overhead of processing RPCs in the server. For such workloads, we propose the use of a new network I/O mechanism, Optimistic RDMA (ORDMA). ORDMA is an alternative to RPC that aims to improve server throughput and response time for small I/Os. We measured performance improvements of up to 32% in server throughput and 36% in response time with use of ORDMA in our prototype.
PDF
The performance of high-speed network-attached storage applications is often limited by end-system overhead, caused primarily by memory copying and network protocol processing. In this paper, we examine alternative strategies for reducing overhead in such systems. We consider optimizations to remote procedure call (RPC)-based data transfer using either remote direct memory access (RDMA) or network interface support for pre-posting of application receive buffers. We demonstrate that both mechanisms enable file access throughput that saturates a 2Gb/s network link when performing large I/Os on relatively slow, commodity PCs. However, for multi-client workloads dominated by small I/Os, throughput is limited by the per-I/O overhead of processing RPCs in the server. For such workloads, we propose the use of a new network I/O mechanism, Optimistic RDMA (ORDMA). ORDMA is an alternative to RPC that aims to improve server throughput and response time for small I/Os. We measured performance improvements of up to 32% in server throughput and 36% in response time with use of ORDMA in our prototype.
Abstract
The Peer-to-Peer (p2p) and Grid infrastructure communities are tackling an overlapping set of problems. In addressing these problems, p2p solutions are usually motivated by elegance or research interest. Grid researchers, under pressure from thousands of scientists with real file sharing and computational needs, are pooling their solutions from a wide range of sources in an attempt to meet user demand. Driven by this need to solve large scientific problems quickly, the Grid is being constructed with the tools at hand: FTP or RPC for data transfer, centralization for scheduling and authentication, and an assumption of correct, obediant nodes. If history is any guide, the World Wide Web depicts viscerally that systems that address user needs can have enormous staying power and affect future research. The Grid infrastructure is a great customer waiting for future p2p products. By no means should we make them our only customers, but we should at least put them on the list. If p2p research does not at least address the Grid, it may eventually be sidelined by defacto distributed algorithms that are less elegant but were used to solve Grid problems. In essense, well have been scooped, again.
PDF PostScript
The Peer-to-Peer (p2p) and Grid infrastructure communities are tackling an overlapping set of problems. In addressing these problems, p2p solutions are usually motivated by elegance or research interest. Grid researchers, under pressure from thousands of scientists with real file sharing and computational needs, are pooling their solutions from a wide range of sources in an attempt to meet user demand. Driven by this need to solve large scientific problems quickly, the Grid is being constructed with the tools at hand: FTP or RPC for data transfer, centralization for scheduling and authentication, and an assumption of correct, obediant nodes. If history is any guide, the World Wide Web depicts viscerally that systems that address user needs can have enormous staying power and affect future research. The Grid infrastructure is a great customer waiting for future p2p products. By no means should we make them our only customers, but we should at least put them on the list. If p2p research does not at least address the Grid, it may eventually be sidelined by defacto distributed algorithms that are less elegant but were used to solve Grid problems. In essense, well have been scooped, again.
PDF PostScript
Abstract
This paper sketches the design of the Eliot File System (Eliot), a mutable filesystem that maintains the pure im- mutability of its peer-to-peer (P2P) substrate by isolating mutation in an auxiliary metadata service.
The immutability of address-to-content bindings has several advantages in P2P systems. However, mutable filesystems are desirable because they allow clients to update existing files; a necessary property for many applications. In order to facilitate modifications, the filesystem must provide some atom of mutability. Since this atom of mutability is a fundamental characteristic of the filesystem and not the underlying storage substrate, it is a mistake to violate the integrity of the substrate with special cases for mutability. Instead, Eliot employs a separate, generalized metadata service that isolates all mutation and client state in an auxiliary replicated database. Eliot provides fine-granularity file updates with either AFS open/close or NFS-like consistency semantics. Eliot builds a mutable filesystem on a global resource bed of purely immutable P2P block storage.
PDF PostScript
This paper sketches the design of the Eliot File System (Eliot), a mutable filesystem that maintains the pure im- mutability of its peer-to-peer (P2P) substrate by isolating mutation in an auxiliary metadata service.
The immutability of address-to-content bindings has several advantages in P2P systems. However, mutable filesystems are desirable because they allow clients to update existing files; a necessary property for many applications. In order to facilitate modifications, the filesystem must provide some atom of mutability. Since this atom of mutability is a fundamental characteristic of the filesystem and not the underlying storage substrate, it is a mistake to violate the integrity of the substrate with special cases for mutability. Instead, Eliot employs a separate, generalized metadata service that isolates all mutation and client state in an auxiliary replicated database. Eliot provides fine-granularity file updates with either AFS open/close or NFS-like consistency semantics. Eliot builds a mutable filesystem on a global resource bed of purely immutable P2P block storage.
PDF PostScript
Abstract
This paper addresses the problem of forming groups in peer-to-peer (P2P) systems and examines what dependability means in decentralized distributed systems. Much of the literature in this field assumes that the participants form a local picture of global state, yet little research has been done discussing how this state remains stable as nodes enter and leave the system. We assume that nodes remain in the system long enough to benefit from retaining state, but not sufficiently long that the dynamic nature of the problem can be ignored. We look at the components that describe a system's dependability and argue that next-generation decentralized systems must explicitly delineate the information dispersal mechanisms (e.g., probe, event-driven, broadcast), the capabilities assumed about constituent nodes (bandwidth, uptime, re-entry distributions), and distribution of information demands (needles in a haystack vs. hay in a haystack). We evaluate two systems based on these criteria: Chord and a heterogeneous-node hierarchical grouping scheme. The former gives a greater than 1 failed request rate under normal P2P conditions and a prototype of the latter a similar rate under more strenuous conditions with an order of magnitude more organizational messages. This analysis suggests several methods to greatly improve the prototype.
PDF PostScript
This paper addresses the problem of forming groups in peer-to-peer (P2P) systems and examines what dependability means in decentralized distributed systems. Much of the literature in this field assumes that the participants form a local picture of global state, yet little research has been done discussing how this state remains stable as nodes enter and leave the system. We assume that nodes remain in the system long enough to benefit from retaining state, but not sufficiently long that the dynamic nature of the problem can be ignored. We look at the components that describe a system's dependability and argue that next-generation decentralized systems must explicitly delineate the information dispersal mechanisms (e.g., probe, event-driven, broadcast), the capabilities assumed about constituent nodes (bandwidth, uptime, re-entry distributions), and distribution of information demands (needles in a haystack vs. hay in a haystack). We evaluate two systems based on these criteria: Chord and a heterogeneous-node hierarchical grouping scheme. The former gives a greater than 1 failed request rate under normal P2P conditions and a prototype of the latter a similar rate under more strenuous conditions with an order of magnitude more organizational messages. This analysis suggests several methods to greatly improve the prototype.
PDF PostScript
Abstract
The Direct Access File System (DAFS) is an emerging industrial standard for network-attached storage. DAFS takes advantage of new user-level network interface standards. This enables a user-level file system structure in which client-side functionality for remote data access resides in a library rather than in the kernel. This structure addresses longstanding performance problems stemming from weak integration of buffering layers in the network transport, kernel-based file systems and applications. The benefits of this architecture include lightweight, portable and asynchronous access to network storage and improved application control over data movement, caching and prefetching.
This paper explores the fundamental performance characteristics of a user-level file system structure based on DAFS. It presents experimental results from an open-source DAFS prototype and compares its performance to a kernel-based NFS implementation optimized for zero-copy data transfer. The results show that both systems can deliver file access throughput in excess of 100 MB/s, saturating network links with similar raw bandwidth. Lower client overhead in the DAFS configuration can improve application performance by up to 40% over optimized NFS when application processing and I/O demands are well-balanced.
PDF
The Direct Access File System (DAFS) is an emerging industrial standard for network-attached storage. DAFS takes advantage of new user-level network interface standards. This enables a user-level file system structure in which client-side functionality for remote data access resides in a library rather than in the kernel. This structure addresses longstanding performance problems stemming from weak integration of buffering layers in the network transport, kernel-based file systems and applications. The benefits of this architecture include lightweight, portable and asynchronous access to network storage and improved application control over data movement, caching and prefetching.
This paper explores the fundamental performance characteristics of a user-level file system structure based on DAFS. It presents experimental results from an open-source DAFS prototype and compares its performance to a kernel-based NFS implementation optimized for zero-copy data transfer. The results show that both systems can deliver file access throughput in excess of 100 MB/s, saturating network links with similar raw bandwidth. Lower client overhead in the DAFS configuration can improve application performance by up to 40% over optimized NFS when application processing and I/O demands are well-balanced.
Abstract
Ant-32 is a new processor architecture designed specifically to address the pedagogical needs of teaching many subjects, including assembly language programming, machine architecture, compilers, operating systems, and VLSI design. This paper discusses our motivation for creating Ant-32 and the philosophy we used to guide our design decisions and gives a high level decsription of the resulting design.
PDF PostScript
Ant-32 is a new processor architecture designed specifically to address the pedagogical needs of teaching many subjects, including assembly language programming, machine architecture, compilers, operating systems, and VLSI design. This paper discusses our motivation for creating Ant-32 and the philosophy we used to guide our design decisions and gives a high level decsription of the resulting design.
PDF PostScript
Abstract
his paper presents a new instructional operating system, OS/161, and simulated execution environment, System/161, for use in teaching an introductory undergraduate operating systems course. We describe the new system, the assignments used in our course, and our experience teaching using the new system.
PDF PostScript
his paper presents a new instructional operating system, OS/161, and simulated execution environment, System/161, for use in teaching an introductory undergraduate operating systems course. We describe the new system, the assignments used in our course, and our experience teaching using the new system.
PDF PostScript
Abstract
At the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), the attendees reached consensus that the most important issue facing the OS research community was "No-Futz" computing; eliminating the ongoing "futzing" that characterizes most systems today. To date, little research has been accomplished in this area. Our goal in writing this paper is to focus the research community on the challenges we face if we are to design systems that are truly futz-free, or even low-futz.
PDF PostScript
At the 1999 Workshop on Hot Topics in Operating Systems (HotOS VII), the attendees reached consensus that the most important issue facing the OS research community was "No-Futz" computing; eliminating the ongoing "futzing" that characterizes most systems today. To date, little research has been accomplished in this area. Our goal in writing this paper is to focus the research community on the challenges we face if we are to design systems that are truly futz-free, or even low-futz.
PDF PostScript
Abstract
As Java becomes a viable platform for server applications, performance becomes a greater concern. An important aspect of Java Virtual Machine performance is its dynamic memory management system (garbage collection or GC). Traditional GC benchmarking often focuses on a set of fixed applications. As a result, when an actual application's memory behavior differs from that of the standard benchmarks, the benchmark results do not help the user judge which GC implementation suits her application the best. In this paper, we present HBench:JGC, an application-specific benchmarking suite, based on the idea that a system's performance be measured in the context of a specific application. HBench:JGC employs a methodology that characterizes the application memory usage and the GC implementation independently and carefully combines both characterizations to form a single metric that reflects a particular application's performance in the presence of a particular GC implementation. We evaluate our approach on Sun Microsystems's JDK1.2.2 classic JVM with a sequential mark-sweep GC. Our results demonstrate HBench:JGC's unique predictive power and its ability to provide meaningful metrics that lead to a better understanding of GC performance.
PDF
As Java becomes a viable platform for server applications, performance becomes a greater concern. An important aspect of Java Virtual Machine performance is its dynamic memory management system (garbage collection or GC). Traditional GC benchmarking often focuses on a set of fixed applications. As a result, when an actual application's memory behavior differs from that of the standard benchmarks, the benchmark results do not help the user judge which GC implementation suits her application the best. In this paper, we present HBench:JGC, an application-specific benchmarking suite, based on the idea that a system's performance be measured in the context of a specific application. HBench:JGC employs a methodology that characterizes the application memory usage and the GC implementation independently and carefully combines both characterizations to form a single metric that reflects a particular application's performance in the presence of a particular GC implementation. We evaluate our approach on Sun Microsystems's JDK1.2.2 classic JVM with a sequential mark-sweep GC. Our results demonstrate HBench:JGC's unique predictive power and its ability to provide meaningful metrics that lead to a better understanding of GC performance.
Abstract
The UNIX Fast File System (FFS) is probably the most widely-used file system for performance comparisons. However, such comparisons frequently overlook many of the performance enhancements that have been added over the past decade. In this paper, we explore the two most commonly used approaches for improving the performance of meta-data operations and recovery: journaling and Soft Updates. Journaling systems use an auxiliary log to record meta-data operations and Soft Updates uses ordered writes to ensure meta-data consistency.
The commercial sector has moved en masse to journaling file systems, as evidenced by their presence on nearly every server platform available today: Solaris, AIX, Digital UNIX, HP-UX, Irix, and Windows NT. On all but Solaris, the default file system uses journaling. In the meantime, Soft Updates holds the promise of providing stronger reliability guarantees than journaling, with faster recovery and superior performance in certain boundary cases.
HTML PDF PostScript Slides (PDF) Slides (PostScript)
The UNIX Fast File System (FFS) is probably the most widely-used file system for performance comparisons. However, such comparisons frequently overlook many of the performance enhancements that have been added over the past decade. In this paper, we explore the two most commonly used approaches for improving the performance of meta-data operations and recovery: journaling and Soft Updates. Journaling systems use an auxiliary log to record meta-data operations and Soft Updates uses ordered writes to ensure meta-data consistency.
The commercial sector has moved en masse to journaling file systems, as evidenced by their presence on nearly every server platform available today: Solaris, AIX, Digital UNIX, HP-UX, Irix, and Windows NT. On all but Solaris, the default file system uses journaling. In the meantime, Soft Updates holds the promise of providing stronger reliability guarantees than journaling, with faster recovery and superior performance in certain boundary cases.
HTML PDF PostScript Slides (PDF) Slides (PostScript)
Abstract
Proportional-share resource management is becoming increasingly important in today's computing environments. In particular, the growing use of the computational resources of central service providers argues for a proportional-share approach that allows resource principals to obtain allocations that reflect their relative importance. In such environments, resource principals must be isolated from one another to prevent the activities of one principal from impinging on the resource rights of others. However, such isolation limits the flexibility with which resource allocations can be modified to reflect the actual needs of applications. We present extensions to the lottery-scheduling resource management framework that increase its flexibility while preserving its ability to provide secure isolation. To demonstrate how this extended framework safely overcomes the limits imposed by existing proportional-share schemes, we have implemented a prototype system that uses the framework to manage CPU time, physical memory, and disk bandwidth. We present the results of experiments that evaluate the prototype, and we show that our framework has the potential to enable server applications to achieve significant gains in performance.
Addendum
As discussed in our 2000 USENIX paper, lottery scheduling's currency abstraction imposes lower limits on the resource allocations that clients of a system can receive. In our USENIX paper, we proposed one method for overcoming these lower limits. In this addendum to the paper, we discuss a limitation of our original solution to the lower-limits problem, and we propose an alternate solution that overcomes the shortcomings of the original solution.
PDF PostScript Slides (PDF) Addendum (PDF)
Proportional-share resource management is becoming increasingly important in today's computing environments. In particular, the growing use of the computational resources of central service providers argues for a proportional-share approach that allows resource principals to obtain allocations that reflect their relative importance. In such environments, resource principals must be isolated from one another to prevent the activities of one principal from impinging on the resource rights of others. However, such isolation limits the flexibility with which resource allocations can be modified to reflect the actual needs of applications. We present extensions to the lottery-scheduling resource management framework that increase its flexibility while preserving its ability to provide secure isolation. To demonstrate how this extended framework safely overcomes the limits imposed by existing proportional-share schemes, we have implemented a prototype system that uses the framework to manage CPU time, physical memory, and disk bandwidth. We present the results of experiments that evaluate the prototype, and we show that our framework has the potential to enable server applications to achieve significant gains in performance.
Addendum
As discussed in our 2000 USENIX paper, lottery scheduling's currency abstraction imposes lower limits on the resource allocations that clients of a system can receive. In our USENIX paper, we proposed one method for overcoming these lower limits. In this addendum to the paper, we discuss a limitation of our original solution to the lower-limits problem, and we propose an alternate solution that overcomes the shortcomings of the original solution.
PDF PostScript Slides (PDF) Addendum (PDF)
Abstract
The emergence of thin client computing and multi-user, remote, graphical interaction revives a range of operating system research issues long dormant, and introduces new directions as well. This paper investigates the effect of operating system design and implementation on the performance of thin client service and interactive applications. We contend that the key performance metric for this type of system and its applications is user-perceived latency and we give a structured approach for investigating operating system design with this criterion in mind. In particular, we apply our approach to a quantitative comparison and analysis of Windows NT, Terminal Server Edition (TSE), and Linux with the X Windows System, two popular implementations of thin client service.
We find that the processor and memory scheduling algorithms in both operating systems are not tuned for thin client service. Under heavy CPU and memory load, we observed user-perceived latencies up to 100 times beyond the threshold of human perception. Even in the idle state, these systems induce unnecessary latency. TSE performs particularly poorly despite scheduler modifications to improve interactive responsiveness. We also show that TSE's network protocol outperforms X by up to six times, and also makes use of a bitmap cache which is essential for handling dynamic elements of modern user interfaces and can reduce network load in these cases by up to 2000%.
PDF
The emergence of thin client computing and multi-user, remote, graphical interaction revives a range of operating system research issues long dormant, and introduces new directions as well. This paper investigates the effect of operating system design and implementation on the performance of thin client service and interactive applications. We contend that the key performance metric for this type of system and its applications is user-perceived latency and we give a structured approach for investigating operating system design with this criterion in mind. In particular, we apply our approach to a quantitative comparison and analysis of Windows NT, Terminal Server Edition (TSE), and Linux with the X Windows System, two popular implementations of thin client service.
We find that the processor and memory scheduling algorithms in both operating systems are not tuned for thin client service. Under heavy CPU and memory load, we observed user-perceived latencies up to 100 times beyond the threshold of human perception. Even in the idle state, these systems induce unnecessary latency. TSE performs particularly poorly despite scheduler modifications to improve interactive responsiveness. We also show that TSE's network protocol outperforms X by up to six times, and also makes use of a bitmap cache which is essential for handling dynamic elements of modern user interfaces and can reduce network load in these cases by up to 2000%.
Abstract
On the vast majority of today's computers, the dominant form of computation is GUI-based user interaction. In such an environment, the user's perception is the final arbiter of performance. Human-factors research shows that a user's perception of performance is affected by unexpectedly long delays. However, most performance-tuning techniques currently rely on throughput-sensitive benchmarks. While these techniques improve the average performance of the system, they do little to detect or eliminate response-time variabilities--in particular, unexpectedly long delays.
We introduce a measurement infrastructure that allows us to improve user-perceived performance by helping us to identify and eliminate the causes of the unexpected long response times that users find unacceptable. We describe TIPME (The Interactive Performance Monitoring Environment), a collection of measurement tools that allowed us to quickly and easily diagnose interactive performance "bugs" in a mature operating system. We present two case studies that demonstrate the effectiveness of our measurement infrastructure. Each of the performance problems we identify drastically affects variability in response time in a mature system, demonstrating that current tuning techniques do not address this class of performance problems.
PDF PostScript
On the vast majority of today's computers, the dominant form of computation is GUI-based user interaction. In such an environment, the user's perception is the final arbiter of performance. Human-factors research shows that a user's perception of performance is affected by unexpectedly long delays. However, most performance-tuning techniques currently rely on throughput-sensitive benchmarks. While these techniques improve the average performance of the system, they do little to detect or eliminate response-time variabilities--in particular, unexpectedly long delays.
We introduce a measurement infrastructure that allows us to improve user-perceived performance by helping us to identify and eliminate the causes of the unexpected long response times that users find unacceptable. We describe TIPME (The Interactive Performance Monitoring Environment), a collection of measurement tools that allowed us to quickly and easily diagnose interactive performance "bugs" in a mature operating system. We present two case studies that demonstrate the effectiveness of our measurement infrastructure. Each of the performance problems we identify drastically affects variability in response time in a mature system, demonstrating that current tuning techniques do not address this class of performance problems.
PDF PostScript
Abstract
Java applications represent a broad class of programs, ranging from programs running on embedded products to high-performance server applications. Standard Java benchmarks ignore this fact and assume a fixed workload. When an actual application's behavior differs from that included in a standard benchmark, the benchmark results are useless, if not misleading. In this paper, we present HBench:Java, an application-specific benchmarking framework, based on the concept that a system's performance must be measured in the context of the application of interest. HBench:Java employs a methodology that uses vectors to characterize the application and the underlying JVM and carefully combines the two vectors to form a single metric that reflects a specific application's performance on a particular JVM such that the performance of multiple JVMs can be realistically compared. Our performance results demonstrate HBench:Java's superiority over traditional benchmarking approaches in predicting real application performance and its ability to pinpoint performance problems.
PDF
Java applications represent a broad class of programs, ranging from programs running on embedded products to high-performance server applications. Standard Java benchmarks ignore this fact and assume a fixed workload. When an actual application's behavior differs from that included in a standard benchmark, the benchmark results are useless, if not misleading. In this paper, we present HBench:Java, an application-specific benchmarking framework, based on the concept that a system's performance must be measured in the context of the application of interest. HBench:Java employs a methodology that uses vectors to characterize the application and the underlying JVM and carefully combines the two vectors to form a single metric that reflects a specific application's performance on a particular JVM such that the performance of multiple JVMs can be realistically compared. Our performance results demonstrate HBench:Java's superiority over traditional benchmarking approaches in predicting real application performance and its ability to pinpoint performance problems.
Abstract
With the introduction of Windows NT, Terminal Server Edition (TSE), Microsoft finally brings to Windows the ``thin-client'' computing model the X Window System has offered Unix for a decade. TSE's two most salient features are the provision of multi-user login service and the provision of that service remotely, over a network link. These features distinguish TSE from previous Microsoft operating systems not only by functionality, but also by how its performance ought to be measured. Because TSE's primary service is interactive, user-perceived latency is more important than ever. In this paper, we examine the resource consumption and latency characteristics of shared usage on a TSE system. We find that the introduction of remote, multi-user access has added to the minimal level of resource consumption, that the efficiency of TSE's RDP protocol is generally good but degrades on dynamic user interface elements, and that TSE can exhibit poor latency performance when subjected to high processor, memory, and network load.
PDF PostScript
With the introduction of Windows NT, Terminal Server Edition (TSE), Microsoft finally brings to Windows the ``thin-client'' computing model the X Window System has offered Unix for a decade. TSE's two most salient features are the provision of multi-user login service and the provision of that service remotely, over a network link. These features distinguish TSE from previous Microsoft operating systems not only by functionality, but also by how its performance ought to be measured. Because TSE's primary service is interactive, user-perceived latency is more important than ever. In this paper, we examine the resource consumption and latency characteristics of shared usage on a TSE system. We find that the introduction of remote, multi-user access has added to the minimal level of resource consumption, that the efficiency of TSE's RDP protocol is generally good but degrades on dynamic user interface elements, and that TSE can exhibit poor latency performance when subjected to high processor, memory, and network load.
PDF PostScript
Abstract
This paper presents the design, implementation, and performance of the Harvard Array of Clustered Computers (HACC), a cluster-based design for scalable, cost-effective web servers. HACC is designed for locality enhancement. Requests that arrive at the cluster are distributed among the nodes so as to enhance the locality of reference that occurs on individual nodes in the cluster. By improving locality on individual cluster nodes, we can reduce their working set sizes and achieve superior performance for less cost than conventional approaches. We implemented HACC on Windows NT 4.0 and evaluated its performance for both static documents and workloads of dynamically generated documents adapted from logs of commercial web servers. Our performance results show that HACC's locality enhancement can improve performance by up to 121% for our stochastically generated static file case, by up to 40% for our trace-based static file case, and by up to 52% for our trace-based dynamic document case, compared to an IP-Sprayer approach to building cluster-based web servers.
PDF
This paper presents the design, implementation, and performance of the Harvard Array of Clustered Computers (HACC), a cluster-based design for scalable, cost-effective web servers. HACC is designed for locality enhancement. Requests that arrive at the cluster are distributed among the nodes so as to enhance the locality of reference that occurs on individual nodes in the cluster. By improving locality on individual cluster nodes, we can reduce their working set sizes and achieve superior performance for less cost than conventional approaches. We implemented HACC on Windows NT 4.0 and evaluated its performance for both static documents and workloads of dynamically generated documents adapted from logs of commercial web servers. Our performance results show that HACC's locality enhancement can improve performance by up to 121% for our stochastically generated static file case, by up to 40% for our trace-based static file case, and by up to 52% for our trace-based dynamic document case, compared to an IP-Sprayer approach to building cluster-based web servers.
Abstract
Berkeley DB is an Open Source embedded database system with a number of key advantages over comparable systems. It is simple to use, supports concurrent access by multiple users, and provides industrial-strength transaction support, including surviving system and disk crashes. This paper describes the design and technical features of Berkeley DB, the distribution, and its license.
PDF
Berkeley DB is an Open Source embedded database system with a number of key advantages over comparable systems. It is simple to use, supports concurrent access by multiple users, and provides industrial-strength transaction support, including surviving system and disk crashes. This paper describes the design and technical features of Berkeley DB, the distribution, and its license.
Abstract
Lottery scheduling's ticket and currency abstractions provide a resource management framework that allows for both flexible allocation and insulation between groups of processes. We propose extensions to this framework that enable greater flexibility while preserving the ability to isolate groups of processes. In particular, we present a mechanism that allows processes to modify their own resource rights by exchanging resource-specific tickets with other processes. Ticket exchanges limit the effects of the changed allocations to the participants in the exchange, and they allow applications to coordinate with each other in ways that are mutually beneficial. Application-specific "negotiators" can be used to initiate exchanges based on an application's quality-of-service requirements and the current state of the system. We also propose flexible access controls for currencies through extensible "brokers" that solve such problems as the inability of users isolated by currencies to renice background jobs. Finally, we suggest using extensibility to allow users to install specialized allocation mechanisms for their processes. Together, these extensions enable an application-centered approach to resource management that is both secure and effective.
HTML PDF PostScript Slides (PostScript)
Lottery scheduling's ticket and currency abstractions provide a resource management framework that allows for both flexible allocation and insulation between groups of processes. We propose extensions to this framework that enable greater flexibility while preserving the ability to isolate groups of processes. In particular, we present a mechanism that allows processes to modify their own resource rights by exchanging resource-specific tickets with other processes. Ticket exchanges limit the effects of the changed allocations to the participants in the exchange, and they allow applications to coordinate with each other in ways that are mutually beneficial. Application-specific "negotiators" can be used to initiate exchanges based on an application's quality-of-service requirements and the current state of the system. We also propose flexible access controls for currencies through extensible "brokers" that solve such problems as the inability of users isolated by currencies to renice background jobs. Finally, we suggest using extensibility to allow users to install specialized allocation mechanisms for their processes. Together, these extensions enable an application-centered approach to resource management that is both secure and effective.
HTML PDF PostScript Slides (PostScript)
Abstract
Most performance analysis today uses either microbenchmarks or standard macrobenchmarks (e.g., SPEC, LADDIS, the Andrew benchmark). However, the results of such benchmarks provide little information to indicate how well a particular system will handle a particular application. Such results are, at best, useless and, at worst, misleading. In this paper, we argue for an application-directed approach to benchmarking, using performance metrics that reflect the expected behavior of a particular application across a range of hardware or software platforms. We present three different approaches to application-specific measurement, one using vectors that characterize both the underlying system and an application, one using trace-driven techniques, and a hybrid approach. We argue that such techniques should become the new standard.
HTML PDF PostScript Slides (PostScript) Slides (HTML)
Most performance analysis today uses either microbenchmarks or standard macrobenchmarks (e.g., SPEC, LADDIS, the Andrew benchmark). However, the results of such benchmarks provide little information to indicate how well a particular system will handle a particular application. Such results are, at best, useless and, at worst, misleading. In this paper, we argue for an application-directed approach to benchmarking, using performance metrics that reflect the expected behavior of a particular application across a range of hardware or software platforms. We present three different approaches to application-specific measurement, one using vectors that characterize both the underlying system and an application, one using trace-driven techniques, and a hybrid approach. We argue that such techniques should become the new standard.
HTML PDF PostScript Slides (PostScript) Slides (HTML)
Abstract
Database configuration and maintenance have historically been complex tasks, often requiring expert knowledge of database design and application behavior. In an embedded environment, it is not feasible to require such expertise and ongoing database maintenance. This paper discusses the database administration challenges posed by embedded systems and describes how the Berkeley DB architecture addresses these challenges.
HTML
Database configuration and maintenance have historically been complex tasks, often requiring expert knowledge of database design and application behavior. In an embedded environment, it is not feasible to require such expertise and ongoing database maintenance. This paper discusses the database administration challenges posed by embedded systems and describes how the Berkeley DB architecture addresses these challenges.
HTML
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncracies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts. Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF PostScript
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncracies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts. Passive NFS traces provide an easy and unobtrusive way to measure, analyze, and gain an understanding of an NFS workload. Historically, such traces have been used primarily by file system researchers in an attempt to understand, categorize, and generalize file system workloads. However, because such traces provide a wealth of detailed information about how a specific system is actually used, they should also be of interest to system administrators. We introduce a new open-source toolkit for passively gathering and summarizing NFS traces and show how to use this toolkit to perform analyses that are difficult or impossible with existing tools.
PDF PostScript
Abstract
The boundary between application and system is becoming increasingly permeable. Extensible applications, such as web browsers, database systems, and operating systems, demonstrate the value of allowing end-users to extend and modify the behavior of what was formerly considered to be a static, inviolate system. Unfortunately, flexibility often comes with a cost: systems unprotected from misbehaved end-user extensions are fragile and prone to instability.
Object-oriented programming models are a good fit for the development of this kind of system. An extension can be designed as a refinement to an existing class and loaded into a running system. In our model, when code is downloaded into the system, it is used to replace a virtual function on an existing C++ object. Because our tool is source-language-neutral, it can be used to build safe, extensible systems written in other languages as well.
There are three methods commonly used to make end-user extensions safe: restrict the extension language (e.g., Java), interpret the extension language (e.g., Tcl), or combine run-time checks with a trusted environment. The third technique is the one discussed here; it offers the twin benefits of the flexibility to implement extensions in an unsafe language, such as C++, and the performance of compiled code.
MiSFIT, the Minimal i386 Software Fault Isolation Tool, can be used as a component of a tool set for building safe extensible systems in C++. MiSFIT transforms C++ code, compiled by the Gnu C++ compiler, into safe binary code. Combined with a runtime support library, the overhead of MiSFIT is an order of magnitude lower than the overhead of interpreted Java, and permits safe extensible systems to be written in C++.
PDF
The boundary between application and system is becoming increasingly permeable. Extensible applications, such as web browsers, database systems, and operating systems, demonstrate the value of allowing end-users to extend and modify the behavior of what was formerly considered to be a static, inviolate system. Unfortunately, flexibility often comes with a cost: systems unprotected from misbehaved end-user extensions are fragile and prone to instability.
Object-oriented programming models are a good fit for the development of this kind of system. An extension can be designed as a refinement to an existing class and loaded into a running system. In our model, when code is downloaded into the system, it is used to replace a virtual function on an existing C++ object. Because our tool is source-language-neutral, it can be used to build safe, extensible systems written in other languages as well.
There are three methods commonly used to make end-user extensions safe: restrict the extension language (e.g., Java), interpret the extension language (e.g., Tcl), or combine run-time checks with a trusted environment. The third technique is the one discussed here; it offers the twin benefits of the flexibility to implement extensions in an unsafe language, such as C++, and the performance of compiled code.
MiSFIT, the Minimal i386 Software Fault Isolation Tool, can be used as a component of a tool set for building safe extensible systems in C++. MiSFIT transforms C++ code, compiled by the Gnu C++ compiler, into safe binary code. Combined with a runtime support library, the overhead of MiSFIT is an order of magnitude lower than the overhead of interpreted Java, and permits safe extensible systems to be written in C++.
Abstract
Mug-shot search is the classic example of the general problem of searching a large facial image database when starting out with only a mental image of the sought-after face. We have implemented a prototype content-based image retrieval system that integrates composite face creation methods with a face-recognition technique (Eigenfaces) so that a user can both create faces and search for them automatically in a database.
Although the Eigenface method has been studied extensively for its ability to perform face identification tasks (in which the input to the system is an on-line facial image to identify), little research has been done to determine how effective it is when applied to the mug shot search problem (in which there is no on-line input image at the outset, and in which the task is similarity retrieval rather than face-recognition). With our prototype system, we have conducted a pilot user study that examines the usefulness of Eigenfaces applied to this problem. The study shows that the Eigenface method, though helpful, is an imperfect model of human perception of similarity between faces. Using a novel evaluation methodology, we have made progress at identifying specific search strategies that, given an imperfect correlation between the system and human similarity metrics, use whatever correlation does exist to the best advantage. The study also indicates that the use of facial composites as query images is advantageous compared to restricting users to database images for their queries.
HTML PDF PostScript Slides (PostScript) Slides (HTML) Slides (PDF)
Mug-shot search is the classic example of the general problem of searching a large facial image database when starting out with only a mental image of the sought-after face. We have implemented a prototype content-based image retrieval system that integrates composite face creation methods with a face-recognition technique (Eigenfaces) so that a user can both create faces and search for them automatically in a database.
Although the Eigenface method has been studied extensively for its ability to perform face identification tasks (in which the input to the system is an on-line facial image to identify), little research has been done to determine how effective it is when applied to the mug shot search problem (in which there is no on-line input image at the outset, and in which the task is similarity retrieval rather than face-recognition). With our prototype system, we have conducted a pilot user study that examines the usefulness of Eigenfaces applied to this problem. The study shows that the Eigenface method, though helpful, is an imperfect model of human perception of similarity between faces. Using a novel evaluation methodology, we have made progress at identifying specific search strategies that, given an imperfect correlation between the system and human similarity metrics, use whatever correlation does exist to the best advantage. The study also indicates that the use of facial composites as query images is advantageous compared to restricting users to database images for their queries.
HTML PDF PostScript Slides (PostScript) Slides (HTML) Slides (PDF)
Abstract
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncrasies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts.
PDF PostScript
A central goal in high-level programming languages, such as those we use to teach introductory computer science courses, is to provide an abstraction that hides the complexity and idiosyncrasies of computer hardware. Although programming languages are very effective at achieving this goal, certain properties of computer hardware cannot be hidden, or are useful to know about. As a consequence, many of the greatest conceptual challenges for beginning programmers arise from a lack of understanding of the basic properties of the hardware upon which computer programs execute.
To address this problem, we have developed a simple virtual machine called ANT for use in our introductory computer science (CS1) curriculum. ANT is designed to be simple enough that a CS1 student can quickly understand it, while at the same time providing an accurate model of many important properties of computer hardware. After two years of experience with ANT in our CS1 course, we believe it is a valuable tool for helping young students understand how programs and data are actually represented in a computer system.
This paper gives a short introduction to ANT. We start with a brief description of the architecture, and then describe how we use ANT in our CS1 course. We include specific examples that demonstrate how ANT can give students intuition about pointers, the representation of data in memory, and other key concepts.
PDF PostScript
Abstract
There is a great deal of research about improving Web server performance and building better, faster servers, but little research in characterizing servers and the load imposed upon them. While some tremendously popular and busy sites, such as netscape.com, playboy.com, and altavista.com, receive several million hits per day, most servers are never subjected to loads of this magnitude. This paper presents the analysis of internet Web server logs for a variety of different types of sites. We present a taxonomy of the different types of Web sites and characterize their access patterns and, more importantly, their growth. We then use our server logs to address some common perceptions about the Web. We show that, on a variety of sites, contrary to popular belief, the use of CGI does not appear to be increasing and that long latencies are not necessarily due to server loading. We then show that, as expected, persistent connections are generally useful, but that dynamic time-out intervals may be unnecessarily complex and that allowing multiple persistent connections per client may actually hinder resource utilization compared to allowing only a single persistent connection.
HTML PDF PostScript
There is a great deal of research about improving Web server performance and building better, faster servers, but little research in characterizing servers and the load imposed upon them. While some tremendously popular and busy sites, such as netscape.com, playboy.com, and altavista.com, receive several million hits per day, most servers are never subjected to loads of this magnitude. This paper presents the analysis of internet Web server logs for a variety of different types of sites. We present a taxonomy of the different types of Web sites and characterize their access patterns and, more importantly, their growth. We then use our server logs to address some common perceptions about the Web. We show that, on a variety of sites, contrary to popular belief, the use of CGI does not appear to be increasing and that long latencies are not necessarily due to server loading. We then show that, as expected, persistent connections are generally useful, but that dynamic time-out intervals may be unnecessarily complex and that allowing multiple persistent connections per client may actually hinder resource utilization compared to allowing only a single persistent connection.
HTML PDF PostScript
Abstract
The majority of today's computing takes place on interactive systems that use a Graphical User Interface (GUI). Performance of these systems is unique in that "good performance" is a reflection of a user's perception. In this paper, we explain why this unique environment requires a new methodological aproach. We describe a measurement/diagnostic tool currently under development and evaluate the feasibility of implementing such a tool under Windows NT. We then present several issues that must be resolved in order for Windows NT to become a popular research platform for this type of work.
PDF
The majority of today's computing takes place on interactive systems that use a Graphical User Interface (GUI). Performance of these systems is unique in that "good performance" is a reflection of a user's perception. In this paper, we explain why this unique environment requires a new methodological aproach. We describe a measurement/diagnostic tool currently under development and evaluate the feasibility of implementing such a tool under Windows NT. We then present several issues that must be resolved in order for Windows NT to become a popular research platform for this type of work.
Abstract
The lmbench suite of operating system microbenchmarks provides a set of portable programs for use in cross-platform comparisons. We have augmented the lmbench suite to increase its flexibility and precision, and to improve its methodological and statistical operation. This enables the detailed study of interactions between the operating system and the hardware architecture. We describe modifications to lmbench, and then use our new benchmark suite, hbench:OS, to examine how the performance of operating system primitives under NetBSD has scaled with the processor evolution of the Intel x86 architecture. Our analysis shows that off-chip memory system design continues to influence operating system performance in a significant way and that key design decisions (such as suboptimal choices of DRAM and cache technology, and memory-bus and cache coherency protocols) can essentially nullify the performance benefits of the aggressive execution core and sophisticated on-chip memory system of a modern processor such as the Intel Pentium Pro.
HTML PDF PostScript Additional documentation
The lmbench suite of operating system microbenchmarks provides a set of portable programs for use in cross-platform comparisons. We have augmented the lmbench suite to increase its flexibility and precision, and to improve its methodological and statistical operation. This enables the detailed study of interactions between the operating system and the hardware architecture. We describe modifications to lmbench, and then use our new benchmark suite, hbench:OS, to examine how the performance of operating system primitives under NetBSD has scaled with the processor evolution of the Intel x86 architecture. Our analysis shows that off-chip memory system design continues to influence operating system performance in a significant way and that key design decisions (such as suboptimal choices of DRAM and cache technology, and memory-bus and cache coherency protocols) can essentially nullify the performance benefits of the aggressive execution core and sophisticated on-chip memory system of a modern processor such as the Intel Pentium Pro.
HTML PDF PostScript Additional documentation
Abstract
Benchmarks are important because they provide a means for users and researchers to characterize how their workloads will perform on different systems and different system architectures. The field of file system design is no different from other areas of research in this regard, and a variety of file system benchmarks are in use, representing a wide range of the different user workloads that may be run on a file system. A realistic benchmark, however, is only one of the tools that is required in order to understand how a file system design will perform in the real world. The benchmark must also be executed on a realistic file system. While the simplest approach maybe to measure the performance of an empty file system, this represents a state that is seldom encountered by real users. In order to study file systems in more representative conditions, we present a methodology for aging a test file system by replaying a workload similar to that experienced by a real file system over a period of many months, or even years. Our aging tools allow the same aging workload to be applied to multiple versions of the same file system, allowing scientific evaluation of the relative merits of competing file system designs.
In addition to describing our aging tools, we demonstrate their use by applying them to evaluate two enhancements to the file layout policies of the UNIX fast file system.
HTML PDF PostScript Slides (PostScript) Slides (HTML) Slides (PDF)
Benchmarks are important because they provide a means for users and researchers to characterize how their workloads will perform on different systems and different system architectures. The field of file system design is no different from other areas of research in this regard, and a variety of file system benchmarks are in use, representing a wide range of the different user workloads that may be run on a file system. A realistic benchmark, however, is only one of the tools that is required in order to understand how a file system design will perform in the real world. The benchmark must also be executed on a realistic file system. While the simplest approach maybe to measure the performance of an empty file system, this represents a state that is seldom encountered by real users. In order to study file systems in more representative conditions, we present a methodology for aging a test file system by replaying a workload similar to that experienced by a real file system over a period of many months, or even years. Our aging tools allow the same aging workload to be applied to multiple versions of the same file system, allowing scientific evaluation of the relative merits of competing file system designs.
In addition to describing our aging tools, we demonstrate their use by applying them to evaluate two enhancements to the file layout policies of the UNIX fast file system.
HTML PDF PostScript Slides (PostScript) Slides (HTML) Slides (PDF)
Abstract
Extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. Extensibility enables a system to efficiently support a broader class of applications than is currently supported. This paper discusses the key challenge in making extensible systems practical: determining which parts of the system need to be extended and how. The determination of which parts of the system need to be extended requires self-monitoring, capturing a significant quantity of data about the performance of the system. Determining how to extend the system requires self-adaptation. In this paper, we describe how an extensible operating system (VINO) can use in situ simulation to explore the efficacy of policy changes. This automatic exploration is applicable to other extensible operating systems and can make these systems self-adapting to workload demands.
PDF Slides (PDF)
Extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. Extensibility enables a system to efficiently support a broader class of applications than is currently supported. This paper discusses the key challenge in making extensible systems practical: determining which parts of the system need to be extended and how. The determination of which parts of the system need to be extended requires self-monitoring, capturing a significant quantity of data about the performance of the system. Determining how to extend the system requires self-adaptation. In this paper, we describe how an extensible operating system (VINO) can use in situ simulation to explore the efficacy of policy changes. This automatic exploration is applicable to other extensible operating systems and can make these systems self-adapting to workload demands.
PDF Slides (PDF)
Abstract
Today's extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. The advantage of this approach is that it provides improved application flexibility and performance; the disadvantage is that buggy or malicious code can jeopardize the integrity of the kernel. It has been demonstrated that it is feasible to use safe languages, software fault isolation, or virtual memory protection to safeguard the main kernel. However, such protection mechanisms do not address the full range of problems, such as resource hoarding, that can arise when application code is introduced into the kernel.
In this paper, we present an analysis of extension mechanisms in the VINO kernel. VINO uses software fault isolation as its safety mechanism and a lightweight transaction system to cope with resource-hoarding. We explain how these two mechanisms are sufficient to protect against a large class of errant or malicious extensions, and we quantify the overhead that this protection introduces.
We find that while the overhead of these techniques is high relative to the cost of the extensions themselves, it is low relative to the benefits that extensibility brings.
HTML PDF PostScript Slides (PostScript) Slides (PDF)
Today's extensible operating systems allow applications to modify kernel behavior by providing mechanisms for application code to run in the kernel address space. The advantage of this approach is that it provides improved application flexibility and performance; the disadvantage is that buggy or malicious code can jeopardize the integrity of the kernel. It has been demonstrated that it is feasible to use safe languages, software fault isolation, or virtual memory protection to safeguard the main kernel. However, such protection mechanisms do not address the full range of problems, such as resource hoarding, that can arise when application code is introduced into the kernel.
In this paper, we present an analysis of extension mechanisms in the VINO kernel. VINO uses software fault isolation as its safety mechanism and a lightweight transaction system to cope with resource-hoarding. We explain how these two mechanisms are sufficient to protect against a large class of errant or malicious extensions, and we quantify the overhead that this protection introduces.
We find that while the overhead of these techniques is high relative to the cost of the extensions themselves, it is low relative to the benefits that extensibility brings.
HTML PDF PostScript Slides (PostScript) Slides (PDF)
Abstract
The bandwidth demands of the World Wide Web continue to grow at a hyper-exponential rate. Given this rocketing growth, caching of web objects as a means to reduce network bandwidth consumption is likely to be a necessity in the very near future. Unfortunately, many Web caches do not satisfactorily maintain cache consistency. This paper presents a survey of contemporary cache consistency mechanisms in use on the Internet today and examines recent research in Web cache consistency. Using trace-driven simulation, we show that a weak cache consistency protocol (the one used in the Alex ftp cache) reduces network bandwidth consumption and server load more than either time-to-live fields or an invalidation protocol and can be tuned to return stale data less than 5% of the time.
PDF PostScript
The bandwidth demands of the World Wide Web continue to grow at a hyper-exponential rate. Given this rocketing growth, caching of web objects as a means to reduce network bandwidth consumption is likely to be a necessity in the very near future. Unfortunately, many Web caches do not satisfactorily maintain cache consistency. This paper presents a survey of contemporary cache consistency mechanisms in use on the Internet today and examines recent research in Web cache consistency. Using trace-driven simulation, we show that a weak cache consistency protocol (the one used in the Alex ftp cache) reduces network bandwidth consumption and server load more than either time-to-live fields or an invalidation protocol and can be tuned to return stale data less than 5% of the time.
PDF PostScript
Abstract
The current trend in operating systems research is to allow applications to dynamically extend the kernel to improve application performance or extend functionality, but the most effective approach to extensibility remains unclear. Some systems use safe languages to permit code to be downloaded directly into the kernel; other systems provide in-kernel interpreters to execute extension code; still others use software techniques to ensure the safety of kernel extensions. The key characteristics that distinguish these systems are the philosophy behind extensibility and the technology used to implement extensibility. This paper presents a taxonomy of the types of extensions that might be desirable in an extensible operating system, evaluates the performance cost of various extension techniques currently being employed, and compares the cost of adding a kernel extension to the benefit of having the extension in the kernel. Our results show that compiled technologies (e.g. Modula-3 and software fault isolation) are good candidates for implementing general-purpose kernel extensions, but that the overhead of interpreted languages is sufficiently high that they are inappropriate for this use.
PDF PostScript
The current trend in operating systems research is to allow applications to dynamically extend the kernel to improve application performance or extend functionality, but the most effective approach to extensibility remains unclear. Some systems use safe languages to permit code to be downloaded directly into the kernel; other systems provide in-kernel interpreters to execute extension code; still others use software techniques to ensure the safety of kernel extensions. The key characteristics that distinguish these systems are the philosophy behind extensibility and the technology used to implement extensibility. This paper presents a taxonomy of the types of extensions that might be desirable in an extensible operating system, evaluates the performance cost of various extension techniques currently being employed, and compares the cost of adding a kernel extension to the benefit of having the extension in the kernel. Our results show that compiled technologies (e.g. Modula-3 and software fault isolation) are good candidates for implementing general-purpose kernel extensions, but that the overhead of interpreted languages is sufficiently high that they are inappropriate for this use.
PDF PostScript
Abstract
The 4.4BSD file system includes a new algorithm for allocating disk blocks to files. The goal of this algorithm is to improve file clustering, increasing the amount of sequential I/O when reading or writing files, thereby improving file system performance. In this paper we study the effectiveness of this algorithm at reducing file system fragmentation. We have created a program that artificially ages a file system by replaying a workload similar to that experienced by a real file system. We used this program to evaluate the effectiveness of the new disk allocation algorithm by replaying ten months of activity on two file systems that differed only in the disk allocation algorithms that they used. At the end of the ten month simulation, the file system using the new allocation algorithm had approximately half the fragmentation of a similarly aged file system that used the traditional disk allocation algorithm. Measuring the performance difference between the two file systems by reading and writing the same set of files on the two systems showed that this decrease in fragmentation improved file write throughput by 20% and read throughput by 32%. In certain test cases, the new allocation algorithm provided a performance improvement of greater than 50%.
PDF Supplementary Materials
The 4.4BSD file system includes a new algorithm for allocating disk blocks to files. The goal of this algorithm is to improve file clustering, increasing the amount of sequential I/O when reading or writing files, thereby improving file system performance. In this paper we study the effectiveness of this algorithm at reducing file system fragmentation. We have created a program that artificially ages a file system by replaying a workload similar to that experienced by a real file system. We used this program to evaluate the effectiveness of the new disk allocation algorithm by replaying ten months of activity on two file systems that differed only in the disk allocation algorithms that they used. At the end of the ten month simulation, the file system using the new allocation algorithm had approximately half the fragmentation of a similarly aged file system that used the traditional disk allocation algorithm. Measuring the performance difference between the two file systems by reading and writing the same set of files on the two systems showed that this decrease in fragmentation improved file write throughput by 20% and read throughput by 32%. In certain test cases, the new allocation algorithm provided a performance improvement of greater than 50%.
PDF Supplementary Materials
Abstract
This paper presents a comparative study of the performance of three operating systems that run on the personal computer architecture derived from the IBM-PC. The operating systems, Windows for Workgroups (tm), Windows NT (tm), and NetBSD (a freely available UNIX (tm) variant) cover a broad range of system functionality and user requirements, from a single address space model to full protection with preemptive multi-tasking. Our measurements were enabled by hardware counters in Intel's Pentium (tm) processor that permit measurement of a broad range of processor events including instruction counts and on-chip cache miss counts. We used both microbenchmarks, which expose specific differences between the systems, and application workloads, which provide an indication of expected end-to-end performance. Our microbenchmark results show that accessing system functionality is often more expensive in Windows than in the other two systems due to frequent changes in machine mode and the use of system call hooks. When running native applications, Windows NT is more efficient than Windows, but it incurs overhead similar to that of a microkernel since its application interface(the Win32 API) is implemented as a user-level server. Overall, system functionality can be accessed most efficiently in NetBSD; we attribute this to its monolithic structure, and to the absence of the complications created by backwards compatibility in the other systems. Measurements of application performance show that although the impact of these differences is significant in terms of instruction counts and other hardware events (often a factor of 2 to 7 difference between the systems), overall performance is sometimes determined by the functionality provided by specific subsystems, such as the graphics subsystem or the file system buffer cache.
PDF PostScript Supplementary Materials Transactions on Computer Systems version (PostScript)
This paper presents a comparative study of the performance of three operating systems that run on the personal computer architecture derived from the IBM-PC. The operating systems, Windows for Workgroups (tm), Windows NT (tm), and NetBSD (a freely available UNIX (tm) variant) cover a broad range of system functionality and user requirements, from a single address space model to full protection with preemptive multi-tasking. Our measurements were enabled by hardware counters in Intel's Pentium (tm) processor that permit measurement of a broad range of processor events including instruction counts and on-chip cache miss counts. We used both microbenchmarks, which expose specific differences between the systems, and application workloads, which provide an indication of expected end-to-end performance. Our microbenchmark results show that accessing system functionality is often more expensive in Windows than in the other two systems due to frequent changes in machine mode and the use of system call hooks. When running native applications, Windows NT is more efficient than Windows, but it incurs overhead similar to that of a microkernel since its application interface(the Win32 API) is implemented as a user-level server. Overall, system functionality can be accessed most efficiently in NetBSD; we attribute this to its monolithic structure, and to the absence of the complications created by backwards compatibility in the other systems. Measurements of application performance show that although the impact of these differences is significant in terms of instruction counts and other hardware events (often a factor of 2 to 7 difference between the systems), overall performance is sometimes determined by the functionality provided by specific subsystems, such as the graphics subsystem or the file system buffer cache.
PDF PostScript Supplementary Materials Transactions on Computer Systems version (PostScript)
Abstract
Applications often require functionality that is implemented in the kernel, but is not directly available to the user level. While extensible operating systems allow kernel functionality to be augmented, we believe that the emphasis on extensibility is misplaced. Applications should be able to reuse kernel code directly and the emphasis should be placed on designing a kernel with that reuse in mind. The advantage of structuring the kernel as a set of reusable, extensible tools is that applications can avoid re-implementing functionality that is already present in the kernel. This will lead to smaller applications, fewer lines of total code, and a more unified computing environment that will be easier to maintain and perform better.
PDF PostScript
Applications often require functionality that is implemented in the kernel, but is not directly available to the user level. While extensible operating systems allow kernel functionality to be augmented, we believe that the emphasis on extensibility is misplaced. Applications should be able to reuse kernel code directly and the emphasis should be placed on designing a kernel with that reuse in mind. The advantage of structuring the kernel as a set of reusable, extensible tools is that applications can avoid re-implementing functionality that is already present in the kernel. This will lead to smaller applications, fewer lines of total code, and a more unified computing environment that will be easier to maintain and perform better.
PDF PostScript
Abstract
Most existing wide-area caching schemes are client initiated. Decisions on when and where to cache information are made without the benefit of the server's global knowledge of the situation. We believe that the server should play a role in making these caching decisions, and we propose geographical push-caching as a way of bringing the server back into the loop. The World Wide Web is an excellent example of a wide-area system that will benefit from geographical push-caching, and we present an architecture that allows a Web server to autonomously replicate HTML pages.
PDF PostScript
Most existing wide-area caching schemes are client initiated. Decisions on when and where to cache information are made without the benefit of the server's global knowledge of the situation. We believe that the server should play a role in making these caching decisions, and we propose geographical push-caching as a way of bringing the server back into the loop. The World Wide Web is an excellent example of a wide-area system that will benefit from geographical push-caching, and we present an architecture that allows a Web server to autonomously replicate HTML pages.
PDF PostScript
Abstract
The Log-structured File System (LFS), introduced in 1991, has received much attention for its potential order-of-magnitude improvement in file system performance. Early research results showed that small file performance could scale with processor speed and that cleaning costs could be kept low, allowing LFS to write at an effective bandwidth of 62 to 83% of the maximum. Later work showed that the presence of synchronous disk operations could degrade performance by as much as 62% and that cleaning overhead could become prohibitive in transaction processing workloads, reducing performance by as much as 40%. The same work showed that the addition of clustered reads and writes in the Berkeley Fast File System (FFS) made it competitive with LFS in large-file handling and software development environments as approximated by the Andrew benchmark.
These seemingly inconsistent results have caused confusion in the file system research community. This paper presents a detailed performance comparison of the 4.4BSD Log-structured File system and the 4.4BSD Fast File System. Ignoring cleaner overhead, our results show that the order-of-magnitude improvement in performance claimed for LFS applies only to meta-data intensive activities, specifically the creation of files one-kilobyte or less and deletion of files 64 kilobytes or less.
For small files, both systems provide comparable read performance, but LFS offers superior performance on writes. For large files (one megabyte and larger), the performance of the two file systems is comparable. When FFS is tuned for writing, its large-file write performance is approximately 15% better than LFS, but its write performance is 25% worse. When FFS is optimized for reading, its large-file read and write performance is comparable to LFS.
Both LFS and FFS can suffer performance degradation, due to cleaning and disk fragmentation respectively. We find that active FFS file systems function at approximately 85-95% of their maximum performance after two to three years. We examine LFS cleaner performance in a transaction-processing environment and find that cleaner overhead reduces LFS performance by more than 33% when the disk is 50% full.
PDF PostScript Supplementary Materials
The Log-structured File System (LFS), introduced in 1991, has received much attention for its potential order-of-magnitude improvement in file system performance. Early research results showed that small file performance could scale with processor speed and that cleaning costs could be kept low, allowing LFS to write at an effective bandwidth of 62 to 83% of the maximum. Later work showed that the presence of synchronous disk operations could degrade performance by as much as 62% and that cleaning overhead could become prohibitive in transaction processing workloads, reducing performance by as much as 40%. The same work showed that the addition of clustered reads and writes in the Berkeley Fast File System (FFS) made it competitive with LFS in large-file handling and software development environments as approximated by the Andrew benchmark.
These seemingly inconsistent results have caused confusion in the file system research community. This paper presents a detailed performance comparison of the 4.4BSD Log-structured File system and the 4.4BSD Fast File System. Ignoring cleaner overhead, our results show that the order-of-magnitude improvement in performance claimed for LFS applies only to meta-data intensive activities, specifically the creation of files one-kilobyte or less and deletion of files 64 kilobytes or less.
For small files, both systems provide comparable read performance, but LFS offers superior performance on writes. For large files (one megabyte and larger), the performance of the two file systems is comparable. When FFS is tuned for writing, its large-file write performance is approximately 15% better than LFS, but its write performance is 25% worse. When FFS is optimized for reading, its large-file read and write performance is comparable to LFS.
Both LFS and FFS can suffer performance degradation, due to cleaning and disk fragmentation respectively. We find that active FFS file systems function at approximately 85-95% of their maximum performance after two to three years. We examine LFS cleaner performance in a transaction-processing environment and find that cleaner overhead reduces LFS performance by more than 33% when the disk is 50% full.
PDF PostScript Supplementary Materials
Abstract
Research results show that while Log-Structured File Systems (LFS) offer the potential for dramatically improved file system performance, the cleaner can seriously degrade performance, by as much as 40% in transaction processing workloads. Our goal is to examine trace data from live file systems and use those to derive simple heuristics that will permit the cleaner to run without interfering with normal file access. Our results show that trivial heuristics perform very well, allowing 97% of all cleaning on the most heavily loaded system we studied to be done in the background.
PDF PostScript
Research results show that while Log-Structured File Systems (LFS) offer the potential for dramatically improved file system performance, the cleaner can seriously degrade performance, by as much as 40% in transaction processing workloads. Our goal is to examine trace data from live file systems and use those to derive simple heuristics that will permit the cleaner to run without interfering with normal file access. Our results show that trivial heuristics perform very well, allowing 97% of all cleaning on the most heavily loaded system we studied to be done in the background.
PDF PostScript
Abstract
This paper explores the application of interactive genetic algorithms to the creation of line drawings. We have built a system that mates or mutates drawings selected by the user to create a new generation of drawings. The initial population from which the user makes selections may be generated randomly or input manually. The process of selection and procreation is repeated many times to evolve a drawing. A wide variety of complex sketches with highlighting and shading can be evolved from very simple drawings. This technique has potential for augmenting and enhancing the power of traditional computer-aided drawing tools, and for expanding the repertoire of the computer-assisted artist.
HTML PDF PostScript Slides (HTML) Slides (PDF)
This paper explores the application of interactive genetic algorithms to the creation of line drawings. We have built a system that mates or mutates drawings selected by the user to create a new generation of drawings. The initial population from which the user makes selections may be generated randomly or input manually. The process of selection and procreation is repeated many times to evolve a drawing. A wide variety of complex sketches with highlighting and shading can be evolved from very simple drawings. This technique has potential for augmenting and enhancing the power of traditional computer-aided drawing tools, and for expanding the repertoire of the computer-assisted artist.
HTML PDF PostScript Slides (HTML) Slides (PDF)
Abstract
Transaction Support in a Log-Structured File System
PDF PostScript Slides (PostScript) Slides (PDF)
Transaction Support in a Log-Structured File System
PDF PostScript Slides (PostScript) Slides (PDF)
Abstract
Research results demonstrate that a log-structured file system offers the potential for dramatically improved write performance, faster recovery time, and faster file creation and deletion than traditional UNIX file systems. This paper presents a redesign and implementation of the Sprite log-structured file system that is more robust and integrated into the vnode interface. Measurements show its performance to be superior to the 4BSD Fast File System in a variety of benchmarks and not significantly less than FFS in any test. Unfortunately, an enhanced version of FFS (with read and write clustering) provides comparable and sometimes superior performance to our LFS. However, LFS can be extended to provide additional functionality such as embedded transactions and versioning, not easily implemented in traditional file systems.
PDF PostScript Slides (PostScript) Slides (PDF)
Research results demonstrate that a log-structured file system offers the potential for dramatically improved write performance, faster recovery time, and faster file creation and deletion than traditional UNIX file systems. This paper presents a redesign and implementation of the Sprite log-structured file system that is more robust and integrated into the vnode interface. Measurements show its performance to be superior to the 4BSD Fast File System in a variety of benchmarks and not significantly less than FFS in any test. Unfortunately, an enhanced version of FFS (with read and write clustering) provides comparable and sometimes superior performance to our LFS. However, LFS can be extended to provide additional functionality such as embedded transactions and versioning, not easily implemented in traditional file systems.
PDF PostScript Slides (PostScript) Slides (PDF)
Abstract
Given the decreasing cost of non-volatile RAM (NVRAM), by the late 1990's it will be feasible for most workstations to include a megabyte or more of NVRAM, enabling the design of higher-performance, more reliable systems. We present the trace-driven simulation and analysis of two uses of NVRAM to improve I/O performance in distributed file systems: non-volatile file caches on client workstations to reduce write traffic to file servers, and write buffers for write-optimized file systems to reduce server disk accesses. Our results show that a megabyte of NVRAM on diskless clients reduces the amount of file data written to the server by 40 to 50%. Increasing the amount of NVRAM shows rapidly diminishing returns, and the particular NVRAM block replacement policy makes little difference to write traffic. Closely integrating the NVRAM with the volatile cache provides the best total traffic reduction. At today's prices, volatile memory provides a better performance improvement per dollar than NVRAM for client caching, but as volatile cache sizes increase and NVRAM becomes cheaper, NVRAM will become cost effective. On the server side, providing a one-half megabyte write-buffer per file system reduces disk accesses by about 20% on most of the measured log-structured file systems (LFS), and by 90% on one heavily-used file system that includes transaction-processing workloads.
PDF PostScript
Given the decreasing cost of non-volatile RAM (NVRAM), by the late 1990's it will be feasible for most workstations to include a megabyte or more of NVRAM, enabling the design of higher-performance, more reliable systems. We present the trace-driven simulation and analysis of two uses of NVRAM to improve I/O performance in distributed file systems: non-volatile file caches on client workstations to reduce write traffic to file servers, and write buffers for write-optimized file systems to reduce server disk accesses. Our results show that a megabyte of NVRAM on diskless clients reduces the amount of file data written to the server by 40 to 50%. Increasing the amount of NVRAM shows rapidly diminishing returns, and the particular NVRAM block replacement policy makes little difference to write traffic. Closely integrating the NVRAM with the volatile cache provides the best total traffic reduction. At today's prices, volatile memory provides a better performance improvement per dollar than NVRAM for client caching, but as volatile cache sizes increase and NVRAM becomes cheaper, NVRAM will become cost effective. On the server side, providing a one-half megabyte write-buffer per file system reduces disk accesses by about 20% on most of the measured log-structured file systems (LFS), and by 90% on one heavily-used file system that includes transaction-processing workloads.
PDF PostScript
Abstract
Transactions provide a useful programming paradigm for maintaining logical consistency, arbitrating concurrent access, and managing recovery. In traditional UNIX systems, the only easy way of using transactions is to purchase a database system. Such systems are often slow, costly, and may not provide the exact functionality desired. This paper presents the design, implementation, and performance of LIBTP, a simple, non-proprietary transaction library using the 4.4BSD database access routines (db(3)). On a conventional transaction processing style benchmark, its performance is approximately 85% that of the database access routines without transaction protection, 200% of that using fsync(2) to commit modifications to disk, and 125% that of a commercial relational database system.
PDF PostScript
Transactions provide a useful programming paradigm for maintaining logical consistency, arbitrating concurrent access, and managing recovery. In traditional UNIX systems, the only easy way of using transactions is to purchase a database system. Such systems are often slow, costly, and may not provide the exact functionality desired. This paper presents the design, implementation, and performance of LIBTP, a simple, non-proprietary transaction library using the 4.4BSD database access routines (db(3)). On a conventional transaction processing style benchmark, its performance is approximately 85% that of the database access routines without transaction protection, 200% of that using fsync(2) to commit modifications to disk, and 125% that of a commercial relational database system.
PDF PostScript
Abstract
This paper presents a performance comparison of several file system allocation policies. The file systems are designed to provide high bandwidth between disks and main memory by taking advantage of parallelism in an underlying disk array, cateringv to large units of transfer, and minimizing the bandwidth dedicated to the transfer of meta data. All of the file systems described use a multiblock allocation strategy that allows both large and small files to be allocated efficiently. Simulation results show that these multiblock policies result in systems that are able to utilize a large percentage of the underlying disk bandwidth; more than 90% in sequential cases. As general purpose systems are called upon to support more data intensive applications such as databases and supercomputing, these policies offer an opportunity to provide superior performance to a larger class of users.
PDF PostScript
This paper presents a performance comparison of several file system allocation policies. The file systems are designed to provide high bandwidth between disks and main memory by taking advantage of parallelism in an underlying disk array, cateringv to large units of transfer, and minimizing the bandwidth dedicated to the transfer of meta data. All of the file systems described use a multiblock allocation strategy that allows both large and small files to be allocated efficiently. Simulation results show that these multiblock policies result in systems that are able to utilize a large percentage of the underlying disk bandwidth; more than 90% in sequential cases. As general purpose systems are called upon to support more data intensive applications such as databases and supercomputing, these policies offer an opportunity to provide superior performance to a larger class of users.
PDF PostScript
Abstract
UNIX support of disk oriented hashing was originally provided by dbm [ATI79] and subsequently improved upon in ndbm [BSD86]. In AT&T System V, in-memory hashed storage and access support was added in the hsearch library routines [ATT85]. The result is a system with two incompatible hashing schemes, each with its own set of shortcomings. This paper presents the design and performance characteristics of a new hashing package providing a superset of the functionality provided by dbm and hsearch. The new package uses linear hashing to provide efficient support of both memory based and disk based hash tables with performance superior to both dbm and hsearch under most conditions.
PDF PostScript
UNIX support of disk oriented hashing was originally provided by dbm [ATI79] and subsequently improved upon in ndbm [BSD86]. In AT&T System V, in-memory hashed storage and access support was added in the hsearch library routines [ATT85]. The result is a system with two incompatible hashing schemes, each with its own set of shortcomings. This paper presents the design and performance characteristics of a new hashing package providing a superset of the functionality provided by dbm and hsearch. The new package uses linear hashing to provide efficient support of both memory based and disk based hash tables with performance superior to both dbm and hsearch under most conditions.
PDF PostScript
Abstract
This paper provides a comparative analysis of five implementations of transaction support. The first of the methods is the traditional approach of implementing transaction processing within a data manager on top of a read optimized file system. The second also assumes a traditional file system but embeds transaction support inside the file system. The third model considers a traditional data manager on top of a write optimized file system. The last two models both embed transaction support inside a write optimized file system, each using a different logging mechanism. Our results show that in a transaction processing environment, a write optimized file system often yields better performance than one optimized for reads. In addition, we show that file system embedded transaction managers can perform as well as data managers when transaction throughput is limited by I/O bandwidth. Finally, even when the CPU is the critical resource, the difference in performance between a data manager and an embedded system is much smaller than previous work has shown.
PDF PostScript
This paper provides a comparative analysis of five implementations of transaction support. The first of the methods is the traditional approach of implementing transaction processing within a data manager on top of a read optimized file system. The second also assumes a traditional file system but embeds transaction support inside the file system. The third model considers a traditional data manager on top of a write optimized file system. The last two models both embed transaction support inside a write optimized file system, each using a different logging mechanism. Our results show that in a transaction processing environment, a write optimized file system often yields better performance than one optimized for reads. In addition, we show that file system embedded transaction managers can perform as well as data managers when transaction throughput is limited by I/O bandwidth. Finally, even when the CPU is the critical resource, the difference in performance between a data manager and an embedded system is much smaller than previous work has shown.
PDF PostScript
Abstract
Since the invention of the movable head disk, people have improved I/O performance by intelligent scheduling of disk accesses. We have applied these techniques to systems with large memories and potentially long disk queues. By viewing the entire buffer cache as a write buffer, we can improve disk bandwidth utilization by applying some traditional disk scheduling techniques. We have analyzed these techniques, which attempt to optimize head movement and guarantee fairness in response time, in the presence of long disk queues. We then propose two algorithms which take rotational latency into account, achieving disk bandwidth utilizations of nearly four times a simple first come first serve algorithm. One of these two algorithms, a weighted shortest total time first, is particularly applicable to a file server environment because it guarantees that all requests get to disk within a specified time window.
PDF PostScript
Since the invention of the movable head disk, people have improved I/O performance by intelligent scheduling of disk accesses. We have applied these techniques to systems with large memories and potentially long disk queues. By viewing the entire buffer cache as a write buffer, we can improve disk bandwidth utilization by applying some traditional disk scheduling techniques. We have analyzed these techniques, which attempt to optimize head movement and guarantee fairness in response time, in the presence of long disk queues. We then propose two algorithms which take rotational latency into account, achieving disk bandwidth utilizations of nearly four times a simple first come first serve algorithm. One of these two algorithms, a weighted shortest total time first, is particularly applicable to a file server environment because it guarantees that all requests get to disk within a specified time window.
PDF PostScript