Research
Systopia, The Computer Systems Laboratory at the University of British Columbia, undertakes research in “Computer Systems – construed broadly.” We do this by adopting an open, outward-facing approach to the field of computer science, guided by the belief that the most interesting work lies at the boundaries and interfaces between different areas.
For details on our lab, visit Systopia.
Professor Seltzer's past work at Harvard illustrates this kind of work
Once upon a time, all of systems was one big area; today it looks more like this:
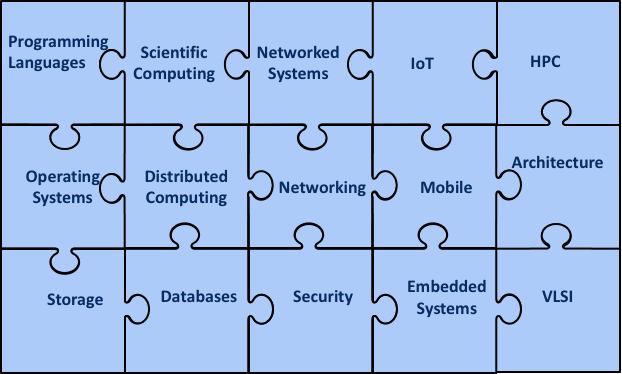
You can also augment any of these areas by providing meaningful theoretical insight (i.e., theory can be part of systems too) or by applying techniques from machine learning or by taking work in any area and using it further progress in machine learning. In other words, if you bring a focus on solving real problems and building artifacts, you’re one of us.
Lab Culture
People do their best work when they are both challenged and happy. Research provides plenty of intellectual challenge; our lab culture is designed to encourage happiness.
We are open and collaborative
We value diversity in all dimensions, welcoming students and collaborators of all genders, orientations, races, and religions. We collaborate within the lab and with colleagues outside the lab. Today, we have projects with colleagues from theory and engineering, statistics and business, Harvard and Duke, the UK and New Zealand, colleges and high schools.
We are positive
Feedback is critical to the research enterprise. However, feedback can take many forms – we welcome constructive criticism. We criticize ideas, not people. We criticize with respect. We are open to others’ perspectives. We do not always agree, but when we disagree, we do so collegially and respectfully.
We are supportive
Each of us shares in the mission to enable every member of our lab to achieve their greatest potential, realizing that each person’s definition of success is highly personal. We support each other in realizing our individual images of success. (Radhika Nagpal’s awesome talk articulates this eloquently.) We do not tolerate personal attacks and discrimination of any kind.
Our Research
We group our research into three broad and overlapping areas.
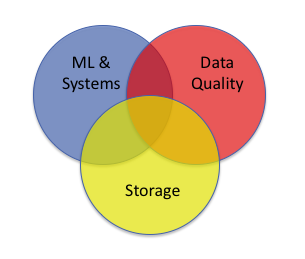
Data Quality
Data drives increasingly more of our lives, from science to business to the products we buy. However, as the importance of data has increased, the reliability of the data on which we base many decisions has not kept page. We investigate techniques and applications that make data more valuable, from capturing data provenance (a formal history of how data came to be in its present form) to deriving provenance to developing applications that use data provenance. We build tools to facilitate scientific reproducibility and we investigate ways to build systems that are more accountable to the people who develop and use them.
Related publications
Machine Learning and Systems
We both apply systems techniques to the construction of machine learning systems and leverage machine learning to improve systems. In the realm of applying systems techniques to the development of machine learning algorithms, we use custom data structures and computational caching to find optimal solutions to real world NP-hard problems. We also apply machine learning techniques to build better intrusion detection systems and automatically parallelizing systems.
Related publications
Storage
Our storage work spans the graph processing, file systems, and database areas. Graph-structured data has become increasingly important, whether it describes social networks, data provenance, or database relations. However, traditional graph storage and graph processing solutions are disjoint – we strive to unify these areas. Historically, file systems have been designed to hold large, unstructured data while databases were designed to manage small, structured data. This distinction has become less meaningful over time; we strive to develop solutions that bridge these two worlds. Finally, new non-volatile memory technologies promise to blur the distinction between memory and persistence – we build systems to confront this new reality.